 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantRetouch: Efficient and High-Fidelity Instruction-Guided Image Retouching with Bilateral Space
Jun 03, 2026Language-guided photo retouching aims to adjust color and tone while preserving geometry and texture. Recently, diffusion-based retouching shows a superior visual quality, but often struggles with both fidelity issues due to its generative nature and efficiency because of its iterative sampling process. In this work, we propose an efficient and fidelity-preserving retouching method using bilateral space manipulation, which is both compact and content-decoupled. Specifically, instead of directly editing pixels or image latents, our model predicts a low-resolution bilateral grid of affine transforms, which are sliced using a learned guidance map and then applied to the full-resolution image. This approach yields both high fidelity and improved efficiency. To retain strong priors of a pretrained generative model, we distill a multi-step diffusion model into our bilateral grid framework using Variational Score Distillation, complemented by a prompt alignment loss to guide instruction-following behavior. Additionally, we introduce a new benchmark and evaluate our method across multiple dimensions: fidelity, instruction following, and efficiency. Compared to the latest retouch methods, like Gemini-2.5-Flash (Nano-Banana), our method can avoid content drift, significantly improve latency, and generate visually pleasing edits, while maintaining a high level of fidelity. Project page: https://openimaginglab.github.io/InstantRetouch/.
Representation Collapse in Sequential Post-Training of Large Language Models
May 28, 2026Large language models are now adapted through chains of post-training stages rather than through a single instruction-tuning pass. This paper studies whether such sequential post-training gradually compresses internal representations into low-rank, anisotropic, and homogeneous feature spaces. We define a measurement suite for hidden states, logits, token trajectories, and LoRA updates, and we use it to analyze supervised fine-tuning, preference optimization, safety/refusal tuning, math and code specialization, and long chain-of-thought tuning under controlled stage orderings. The central hypothesis is that excessive representation concentration is not merely a geometric curiosity: it predicts reduced plasticity during later adaptation, weaker out-of-domain generalization, and poorer calibration. We further evaluate lightweight interventions, including mixed-domain replay, feature refresh, representation diversity regularization, and LoRA update decorrelation, as ways to preserve future learnability without giving up the behavioral gains of post-training.
$I^2G$: Generating Instructional Illustrations via Text-Conditioned Diffusion
May 22, 2025
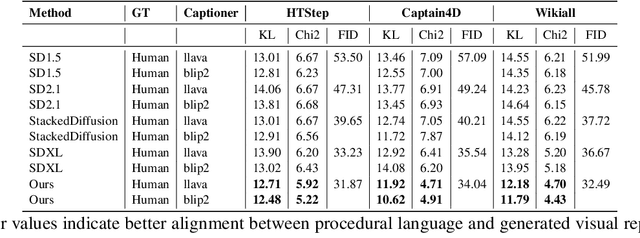
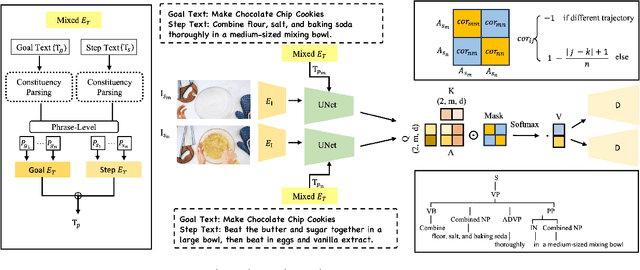
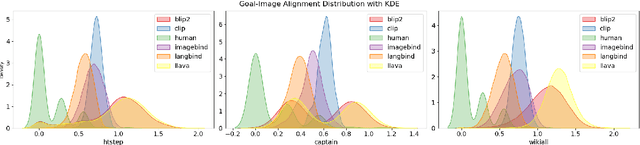
The effective communication of procedural knowledge remains a significant challenge in natural language processing (NLP), as purely textual instructions often fail to convey complex physical actions and spatial relationships. We address this limitation by proposing a language-driven framework that translates procedural text into coherent visual instructions. Our approach models the linguistic structure of instructional content by decomposing it into goal statements and sequential steps, then conditioning visual generation on these linguistic elements. We introduce three key innovations: (1) a constituency parser-based text encoding mechanism that preserves semantic completeness even with lengthy instructions, (2) a pairwise discourse coherence model that maintains consistency across instruction sequences, and (3) a novel evaluation protocol specifically designed for procedural language-to-image alignment. Our experiments across three instructional datasets (HTStep, CaptainCook4D, and WikiAll) demonstrate that our method significantly outperforms existing baselines in generating visuals that accurately reflect the linguistic content and sequential nature of instructions. This work contributes to the growing body of research on grounding procedural language in visual content, with applications spanning education, task guidance, and multimodal language understanding.
S2R-HDR: A Large-Scale Rendered Dataset for HDR Fusion
Apr 10, 2025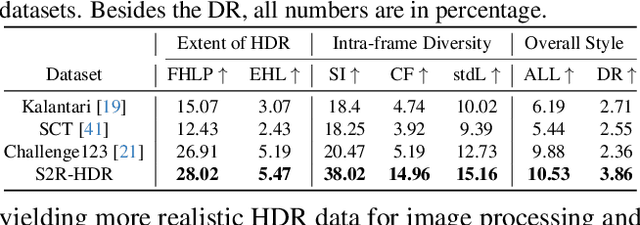
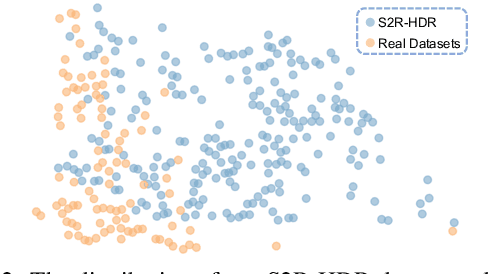
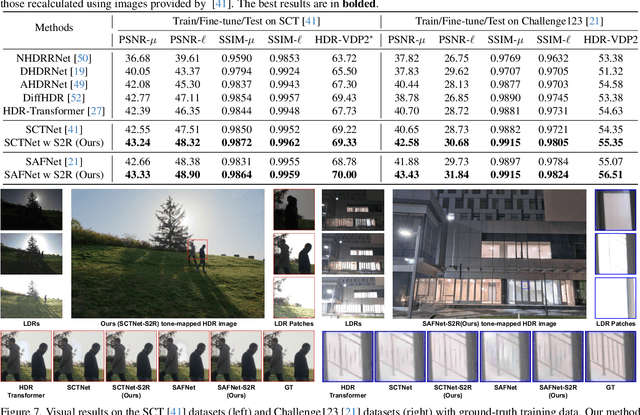

The generalization of learning-based high dynamic range (HDR) fusion is often limited by the availability of training data, as collecting large-scale HDR images from dynamic scenes is both costly and technically challenging. To address these challenges, we propose S2R-HDR, the first large-scale high-quality synthetic dataset for HDR fusion, with 24,000 HDR samples. Using Unreal Engine 5, we design a diverse set of realistic HDR scenes that encompass various dynamic elements, motion types, high dynamic range scenes, and lighting. Additionally, we develop an efficient rendering pipeline to generate realistic HDR images. To further mitigate the domain gap between synthetic and real-world data, we introduce S2R-Adapter, a domain adaptation designed to bridge this gap and enhance the generalization ability of models. Experimental results on real-world datasets demonstrate that our approach achieves state-of-the-art HDR reconstruction performance. Dataset and code will be available at https://openimaginglab.github.io/S2R-HDR.
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025
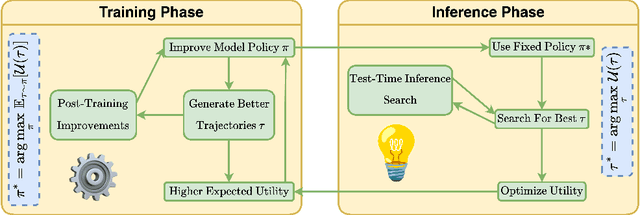
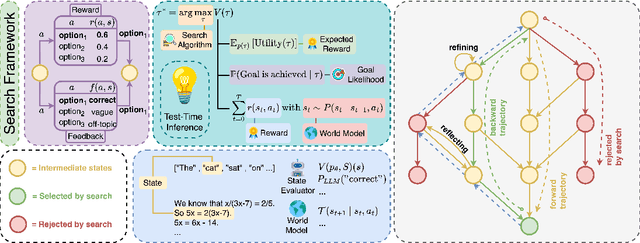
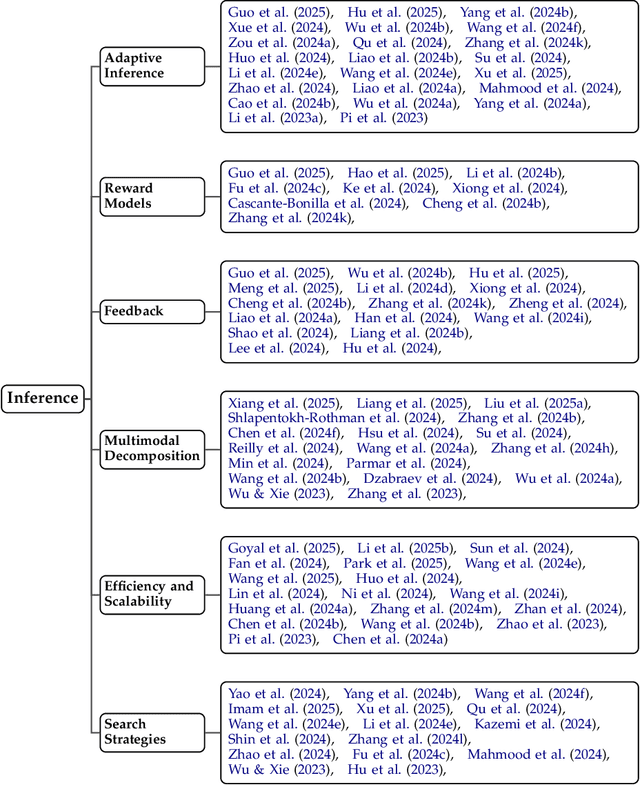
Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.
VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity
Mar 14, 2025Visual reasoning is central to human cognition, enabling individuals to interpret and abstractly understand their environment. Although recent Multimodal Large Language Models (MLLMs) have demonstrated impressive performance across language and vision-language tasks, existing benchmarks primarily measure recognition-based skills and inadequately assess true visual reasoning capabilities. To bridge this critical gap, we introduce VERIFY, a benchmark explicitly designed to isolate and rigorously evaluate the visual reasoning capabilities of state-of-the-art MLLMs. VERIFY compels models to reason primarily from visual information, providing minimal textual context to reduce reliance on domain-specific knowledge and linguistic biases. Each problem is accompanied by a human-annotated reasoning path, making it the first to provide in-depth evaluation of model decision-making processes. Additionally, we propose novel metrics that assess visual reasoning fidelity beyond mere accuracy, highlighting critical imbalances in current model reasoning patterns. Our comprehensive benchmarking of leading MLLMs uncovers significant limitations, underscoring the need for a balanced and holistic approach to both perception and reasoning. For more teaser and testing, visit our project page (https://verify-eqh.pages.dev/).
Mitigating Hallucinations in Multimodal Spatial Relations through Constraint-Aware Prompting
Feb 12, 2025Spatial relation hallucinations pose a persistent challenge in large vision-language models (LVLMs), leading to generate incorrect predictions about object positions and spatial configurations within an image. To address this issue, we propose a constraint-aware prompting framework designed to reduce spatial relation hallucinations. Specifically, we introduce two types of constraints: (1) bidirectional constraint, which ensures consistency in pairwise object relations, and (2) transitivity constraint, which enforces relational dependence across multiple objects. By incorporating these constraints, LVLMs can produce more spatially coherent and consistent outputs. We evaluate our method on three widely-used spatial relation datasets, demonstrating performance improvements over existing approaches. Additionally, a systematic analysis of various bidirectional relation analysis choices and transitivity reference selections highlights greater possibilities of our methods in incorporating constraints to mitigate spatial relation hallucinations.
NOC: High-Quality Neural Object Cloning with 3D Lifting of Segment Anything
Sep 22, 2023With the development of the neural field, reconstructing the 3D model of a target object from multi-view inputs has recently attracted increasing attention from the community. Existing methods normally learn a neural field for the whole scene, while it is still under-explored how to reconstruct a certain object indicated by users on-the-fly. Considering the Segment Anything Model (SAM) has shown effectiveness in segmenting any 2D images, in this paper, we propose Neural Object Cloning (NOC), a novel high-quality 3D object reconstruction method, which leverages the benefits of both neural field and SAM from two aspects. Firstly, to separate the target object from the scene, we propose a novel strategy to lift the multi-view 2D segmentation masks of SAM into a unified 3D variation field. The 3D variation field is then projected into 2D space and generates the new prompts for SAM. This process is iterative until convergence to separate the target object from the scene. Then, apart from 2D masks, we further lift the 2D features of the SAM encoder into a 3D SAM field in order to improve the reconstruction quality of the target object. NOC lifts the 2D masks and features of SAM into the 3D neural field for high-quality target object reconstruction. We conduct detailed experiments on several benchmark datasets to demonstrate the advantages of our method. The code will be released.
PM-DETR: Domain Adaptive Prompt Memory for Object Detection with Transformers
Jul 01, 2023The Transformer-based detectors (i.e., DETR) have demonstrated impressive performance on end-to-end object detection. However, transferring DETR to different data distributions may lead to a significant performance degradation. Existing adaptation techniques focus on model-based approaches, which aim to leverage feature alignment to narrow the distribution shift between different domains. In this study, we propose a hierarchical Prompt Domain Memory (PDM) for adapting detection transformers to different distributions. PDM comprehensively leverages the prompt memory to extract domain-specific knowledge and explicitly constructs a long-term memory space for the data distribution, which represents better domain diversity compared to existing methods. Specifically, each prompt and its corresponding distribution value are paired in the memory space, and we inject top M distribution-similar prompts into the input and multi-level embeddings of DETR. Additionally, we introduce the Prompt Memory Alignment (PMA) to reduce the discrepancy between the source and target domains by fully leveraging the domain-specific knowledge extracted from the prompt domain memory. Extensive experiments demonstrate that our method outperforms state-of-the-art domain adaptive object detection methods on three benchmarks, including scene, synthetic to real, and weather adaptation. Codes will be released.
Exploring Sparse Visual Prompt for Cross-domain Semantic Segmentation
Mar 17, 2023Visual Domain Prompts (VDP) have shown promising potential in addressing visual cross-domain problems. Existing methods adopt VDP in classification domain adaptation (DA), such as tuning image-level or feature-level prompts for target domains. Since the previous dense prompts are opaque and mask out continuous spatial details in the prompt regions, it will suffer from inaccurate contextual information extraction and insufficient domain-specific feature transferring when dealing with the dense prediction (i.e. semantic segmentation) DA problems. Therefore, we propose a novel Sparse Visual Domain Prompts (SVDP) approach tailored for addressing domain shift problems in semantic segmentation, which holds minimal discrete trainable parameters (e.g. 10\%) of the prompt and reserves more spatial information. To better apply SVDP, we propose Domain Prompt Placement (DPP) method to adaptively distribute several SVDP on regions with large data distribution distance based on uncertainty guidance. It aims to extract more local domain-specific knowledge and realizes efficient cross-domain learning. Furthermore, we design a Domain Prompt Updating (DPU) method to optimize prompt parameters differently for each target domain sample with different degrees of domain shift, which helps SVDP to better fit target domain knowledge. Experiments, which are conducted on the widely-used benchmarks (Cityscapes, Foggy-Cityscapes, and ACDC), show that our proposed method achieves state-of-the-art performances on the source-free adaptations, including six Test Time Adaptation and one Continual Test-Time Adaptation in semantic segmentation.