 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Nov 07, 2025Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
Aug 28, 2025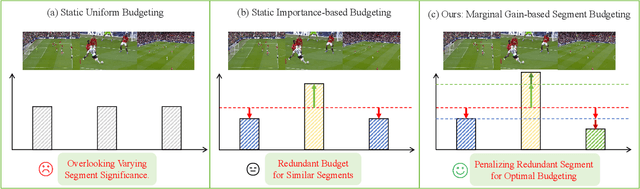
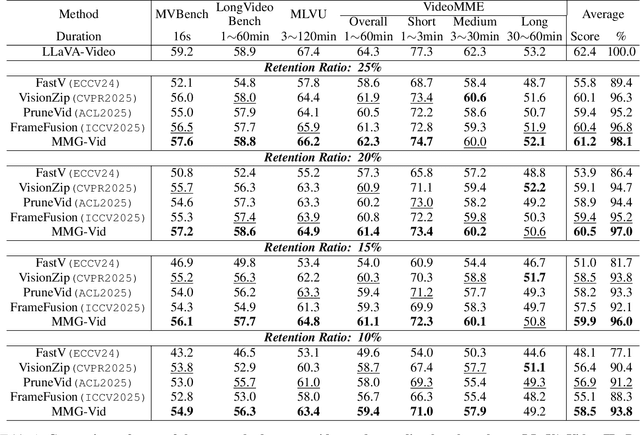
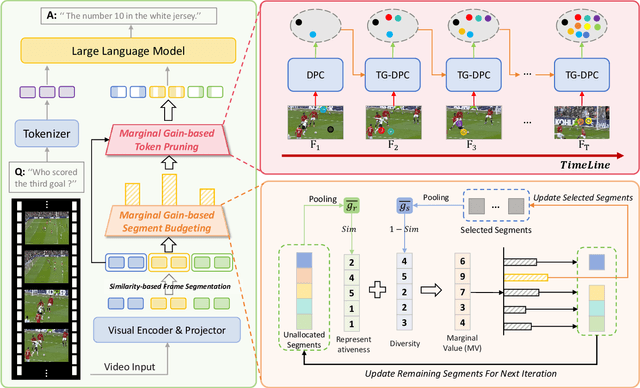
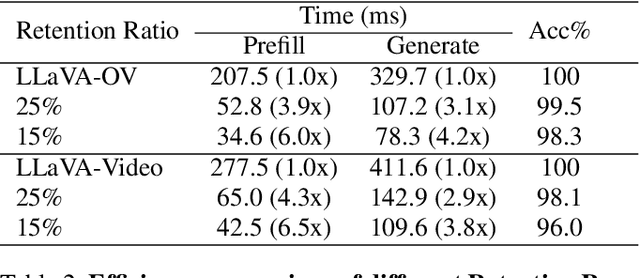
Video Large Language Models (VLLMs) excel in video understanding, but their excessive visual tokens pose a significant computational challenge for real-world applications. Current methods aim to enhance inference efficiency by visual token pruning. However, they do not consider the dynamic characteristics and temporal dependencies of video frames, as they perceive video understanding as a multi-frame task. To address these challenges, we propose MMG-Vid, a novel training-free visual token pruning framework that removes redundancy by Maximizing Marginal Gains at both segment-level and token-level. Specifically, we first divide the video into segments based on frame similarity, and then dynamically allocate the token budget for each segment to maximize the marginal gain of each segment. Subsequently, we propose a temporal-guided DPC algorithm that jointly models inter-frame uniqueness and intra-frame diversity, thereby maximizing the marginal gain of each token. By combining both stages, MMG-Vid can maximize the utilization of the limited token budget, significantly improving efficiency while maintaining strong performance. Extensive experiments demonstrate that MMG-Vid can maintain over 99.5% of the original performance, while effectively reducing 75% visual tokens and accelerating the prefilling stage by 3.9x on LLaVA-OneVision-7B. Code will be released soon.
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Jun 12, 2025



In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95\% and CUDA latency by 78\%, while maintaining 94\% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
Concept-as-Tree: Synthetic Data is All You Need for VLM Personalization
Mar 17, 2025Vision-Language Models (VLMs) have demonstrated exceptional performance in various multi-modal tasks. Recently, there has been an increasing interest in improving the personalization capabilities of VLMs. To better integrate user-provided concepts into VLMs, many methods use positive and negative samples to fine-tune these models. However, the scarcity of user-provided positive samples and the low quality of retrieved negative samples pose challenges for fine-tuning. To reveal the relationship between sample and model performance, we systematically investigate the impact of positive and negative samples (easy and hard) and their diversity on VLM personalization tasks. Based on the detailed analysis, we introduce Concept-as-Tree (CaT), which represents a concept as a tree structure, thereby enabling the data generation of positive and negative samples with varying difficulty and diversity for VLM personalization. With a well-designed data filtering strategy, our CaT framework can ensure the quality of generated data, constituting a powerful pipeline. We perform thorough experiments with various VLM personalization baselines to assess the effectiveness of the pipeline, alleviating the lack of positive samples and the low quality of negative samples. Our results demonstrate that CaT equipped with the proposed data filter significantly enhances the personalization capabilities of VLMs across the MyVLM, Yo'LLaVA, and MC-LLaVA datasets. To our knowledge, this work is the first controllable synthetic data pipeline for VLM personalization. The code is released at \href{https://github.com/zengkaiya/CaT}{https://github.com/zengkaiya/CaT}.
MoVE-KD: Knowledge Distillation for VLMs with Mixture of Visual Encoders
Jan 03, 2025



Visual encoders are fundamental components in vision-language models (VLMs), each showcasing unique strengths derived from various pre-trained visual foundation models. To leverage the various capabilities of these encoders, recent studies incorporate multiple encoders within a single VLM, leading to a considerable increase in computational cost. In this paper, we present Mixture-of-Visual-Encoder Knowledge Distillation (MoVE-KD), a novel framework that distills the unique proficiencies of multiple vision encoders into a single, efficient encoder model. Specifically, to mitigate conflicts and retain the unique characteristics of each teacher encoder, we employ low-rank adaptation (LoRA) and mixture-of-experts (MoEs) to selectively activate specialized knowledge based on input features, enhancing both adaptability and efficiency. To regularize the KD process and enhance performance, we propose an attention-based distillation strategy that adaptively weighs the different visual encoders and emphasizes valuable visual tokens, reducing the burden of replicating comprehensive but distinct features from multiple teachers. Comprehensive experiments on popular VLMs, such as LLaVA and LLaVA-NeXT, validate the effectiveness of our method. The code will be released.
[CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster
Dec 02, 2024![Figure 1 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F8-Table1-1.png&w=640&q=75)
![Figure 2 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F5-Figure3-1.png&w=640&q=75)
![Figure 4 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F9-Table3-1.png&w=640&q=75)
Large vision-language models (VLMs) often rely on a substantial number of visual tokens when interacting with large language models (LLMs), which has proven to be inefficient. Recent efforts have aimed to accelerate VLM inference by pruning visual tokens. Most existing methods assess the importance of visual tokens based on the text-visual cross-attentions in LLMs. In this study, we find that the cross-attentions between text and visual tokens in LLMs are inaccurate. Pruning tokens based on these inaccurate attentions leads to significant performance degradation, especially at high reduction ratios. To this end, we introduce FasterVLM, a simple yet effective training-free visual token pruning method that evaluates the importance of visual tokens more accurately by utilizing attentions between the [CLS] token and image tokens from the visual encoder. Since FasterVLM eliminates redundant visual tokens immediately after the visual encoder, ensuring they do not interact with LLMs and resulting in faster VLM inference. It is worth noting that, benefiting from the accuracy of [CLS] cross-attentions, FasterVLM can prune 95\% of visual tokens while maintaining 90\% of the performance of LLaVA-1.5-7B. We apply FasterVLM to various VLMs, including LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA, to demonstrate its effectiveness. Experimental results show that our FasterVLM maintains strong performance across various VLM architectures and reduction ratios, significantly outperforming existing text-visual attention-based methods. Our code is available at https://github.com/Theia-4869/FasterVLM.
Proactive Gradient Conflict Mitigation in Multi-Task Learning: A Sparse Training Perspective
Nov 27, 2024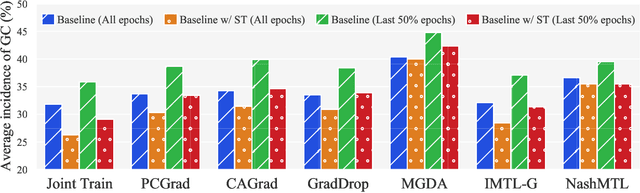
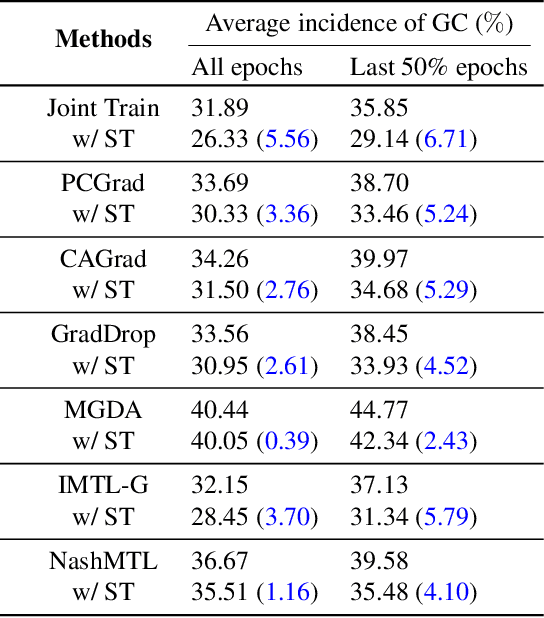
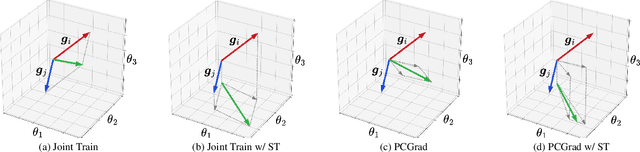
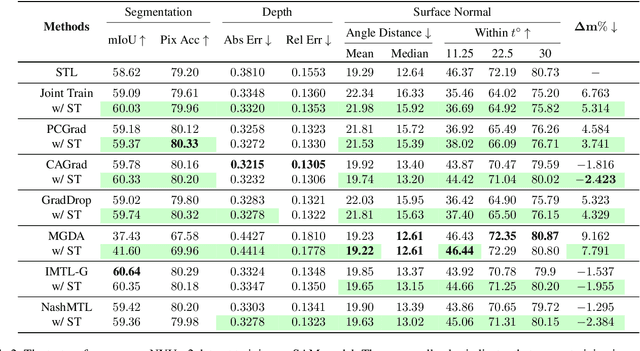
Advancing towards generalist agents necessitates the concurrent processing of multiple tasks using a unified model, thereby underscoring the growing significance of simultaneous model training on multiple downstream tasks. A common issue in multi-task learning is the occurrence of gradient conflict, which leads to potential competition among different tasks during joint training. This competition often results in improvements in one task at the expense of deterioration in another. Although several optimization methods have been developed to address this issue by manipulating task gradients for better task balancing, they cannot decrease the incidence of gradient conflict. In this paper, we systematically investigate the occurrence of gradient conflict across different methods and propose a strategy to reduce such conflicts through sparse training (ST), wherein only a portion of the model's parameters are updated during training while keeping the rest unchanged. Our extensive experiments demonstrate that ST effectively mitigates conflicting gradients and leads to superior performance. Furthermore, ST can be easily integrated with gradient manipulation techniques, thus enhancing their effectiveness.
Adaptive Distribution Masked Autoencoders for Continual Test-Time Adaptation
Dec 19, 2023



Continual Test-Time Adaptation (CTTA) is proposed to migrate a source pre-trained model to continually changing target distributions, addressing real-world dynamism. Existing CTTA methods mainly rely on entropy minimization or teacher-student pseudo-labeling schemes for knowledge extraction in unlabeled target domains. However, dynamic data distributions cause miscalibrated predictions and noisy pseudo-labels in existing self-supervised learning methods, hindering the effective mitigation of error accumulation and catastrophic forgetting problems during the continual adaptation process. To tackle these issues, we propose a continual self-supervised method, Adaptive Distribution Masked Autoencoders (ADMA), which enhances the extraction of target domain knowledge while mitigating the accumulation of distribution shifts. Specifically, we propose a Distribution-aware Masking (DaM) mechanism to adaptively sample masked positions, followed by establishing consistency constraints between the masked target samples and the original target samples. Additionally, for masked tokens, we utilize an efficient decoder to reconstruct a hand-crafted feature descriptor (e.g., Histograms of Oriented Gradients), leveraging its invariant properties to boost task-relevant representations. Through conducting extensive experiments on four widely recognized benchmarks, our proposed method attains state-of-the-art performance in both classification and segmentation CTTA tasks.
Gradient-based Parameter Selection for Efficient Fine-Tuning
Dec 15, 2023



With the growing size of pre-trained models, full fine-tuning and storing all the parameters for various downstream tasks is costly and infeasible. In this paper, we propose a new parameter-efficient fine-tuning method, Gradient-based Parameter Selection (GPS), demonstrating that only tuning a few selected parameters from the pre-trained model while keeping the remainder of the model frozen can generate similar or better performance compared with the full model fine-tuning method. Different from the existing popular and state-of-the-art parameter-efficient fine-tuning approaches, our method does not introduce any additional parameters and computational costs during both the training and inference stages. Another advantage is the model-agnostic and non-destructive property, which eliminates the need for any other design specific to a particular model. Compared with the full fine-tuning, GPS achieves 3.33% (91.78% vs. 88.45%, FGVC) and 9.61% (73.1% vs. 65.57%, VTAB) improvement of the accuracy with tuning only 0.36% parameters of the pre-trained model on average over 24 image classification tasks; it also demonstrates a significant improvement of 17% and 16.8% in mDice and mIoU, respectively, on medical image segmentation task. Moreover, GPS achieves state-of-the-art performance compared with existing PEFT methods.
Split & Merge: Unlocking the Potential of Visual Adapters via Sparse Training
Dec 05, 2023With the rapid growth in the scale of pre-trained foundation models, parameter-efficient fine-tuning techniques have gained significant attention, among which Adapter Tuning is the most widely used. Despite achieving efficiency, Adapter Tuning still underperforms full fine-tuning, and the performance improves at the cost of an increase in parameters. Recent efforts address this issue by pruning the original adapters, but it also introduces training instability and suboptimal performance on certain datasets. Motivated by this, we propose Mixture of Sparse Adapters, or MoSA, as a novel Adapter Tuning method to fully unleash the potential of each parameter in the adapter. We first split the standard adapter into multiple non-overlapping modules, then stochastically activate modules for sparse training, and finally merge them to form a complete adapter after tuning. In this way, MoSA can achieve significantly better performance than standard adapters without any additional computational or storage overhead. Furthermore, we propose a hierarchical sparse strategy to better leverage limited training data. Extensive experiments on a series of 27 visual tasks demonstrate that MoSA consistently outperforms other Adapter Tuning methods as well as other baselines by a significant margin. Furthermore, in two challenging scenarios with low-resource and multi-task settings, MoSA achieves satisfactory results, further demonstrating the effectiveness of our design. Our code will be released.