 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Boosting Decision Tree with LSTM for Investment Prediction
May 29, 2025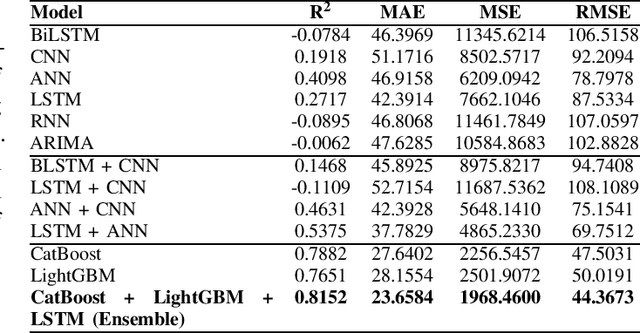
This paper proposes a hybrid framework combining LSTM (Long Short-Term Memory) networks with LightGBM and CatBoost for stock price prediction. The framework processes time-series financial data and evaluates performance using seven models: Artificial Neural Networks (ANNs), Convolutional Neural Networks (CNNs), Bidirectional LSTM (BiLSTM), vanilla LSTM, XGBoost, LightGBM, and standard Neural Networks (NNs). Key metrics, including MAE, R-squared, MSE, and RMSE, are used to establish benchmarks across different time scales. Building on these benchmarks, we develop an ensemble model that combines the strengths of sequential and tree-based approaches. Experimental results show that the proposed framework improves accuracy by 10 to 15 percent compared to individual models and reduces error during market changes. This study highlights the potential of ensemble methods for financial forecasting and provides a flexible design for integrating new machine learning techniques.
[CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster
Dec 02, 2024![Figure 1 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F8-Table1-1.png&w=640&q=75)
![Figure 2 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F5-Figure3-1.png&w=640&q=75)
![Figure 4 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F9-Table3-1.png&w=640&q=75)
Large vision-language models (VLMs) often rely on a substantial number of visual tokens when interacting with large language models (LLMs), which has proven to be inefficient. Recent efforts have aimed to accelerate VLM inference by pruning visual tokens. Most existing methods assess the importance of visual tokens based on the text-visual cross-attentions in LLMs. In this study, we find that the cross-attentions between text and visual tokens in LLMs are inaccurate. Pruning tokens based on these inaccurate attentions leads to significant performance degradation, especially at high reduction ratios. To this end, we introduce FasterVLM, a simple yet effective training-free visual token pruning method that evaluates the importance of visual tokens more accurately by utilizing attentions between the [CLS] token and image tokens from the visual encoder. Since FasterVLM eliminates redundant visual tokens immediately after the visual encoder, ensuring they do not interact with LLMs and resulting in faster VLM inference. It is worth noting that, benefiting from the accuracy of [CLS] cross-attentions, FasterVLM can prune 95\% of visual tokens while maintaining 90\% of the performance of LLaVA-1.5-7B. We apply FasterVLM to various VLMs, including LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA, to demonstrate its effectiveness. Experimental results show that our FasterVLM maintains strong performance across various VLM architectures and reduction ratios, significantly outperforming existing text-visual attention-based methods. Our code is available at https://github.com/Theia-4869/FasterVLM.
Advanced User Credit Risk Prediction Model using LightGBM, XGBoost and Tabnet with SMOTEENN
Aug 07, 2024Bank credit risk is a significant challenge in modern financial transactions, and the ability to identify qualified credit card holders among a large number of applicants is crucial for the profitability of a bank'sbank's credit card business. In the past, screening applicants'applicants' conditions often required a significant amount of manual labor, which was time-consuming and labor-intensive. Although the accuracy and reliability of previously used ML models have been continuously improving, the pursuit of more reliable and powerful AI intelligent models is undoubtedly the unremitting pursuit by major banks in the financial industry. In this study, we used a dataset of over 40,000 records provided by a commercial bank as the research object. We compared various dimensionality reduction techniques such as PCA and T-SNE for preprocessing high-dimensional datasets and performed in-depth adaptation and tuning of distributed models such as LightGBM and XGBoost, as well as deep models like Tabnet. After a series of research and processing, we obtained excellent research results by combining SMOTEENN with these techniques. The experiments demonstrated that LightGBM combined with PCA and SMOTEENN techniques can assist banks in accurately predicting potential high-quality customers, showing relatively outstanding performance compared to other models.
HybridGazeNet: Geometric model guided Convolutional Neural Networks for gaze estimation
Nov 23, 2021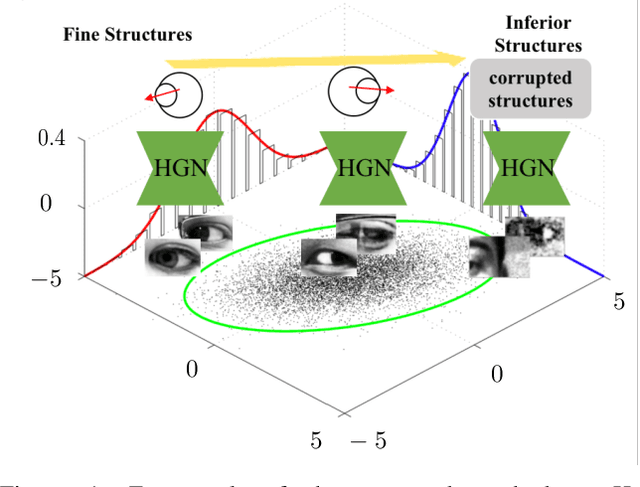

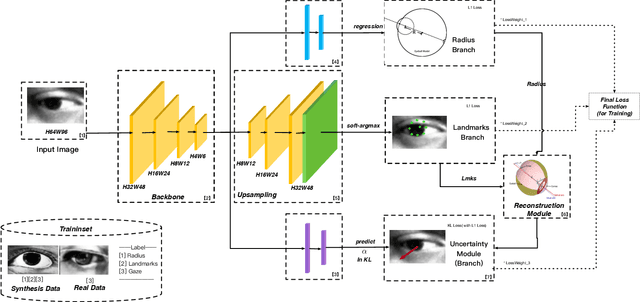
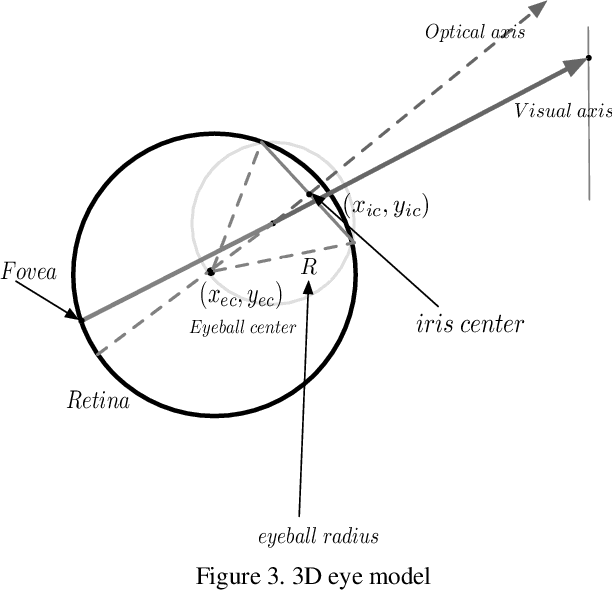
As a critical cue for understanding human intention, human gaze provides a key signal for Human-Computer Interaction(HCI) applications. Appearance-based gaze estimation, which directly regresses the gaze vector from eye images, has made great progress recently based on Convolutional Neural Networks(ConvNets) architecture and open-source large-scale gaze datasets. However, encoding model-based knowledge into CNN model to further improve the gaze estimation performance remains a topic that needs to be explored. In this paper, we propose HybridGazeNet(HGN), a unified framework that encodes the geometric eyeball model into the appearance-based CNN architecture explicitly. Composed of a multi-branch network and an uncertainty module, HybridGazeNet is trained using a hyridized strategy. Experiments on multiple challenging gaze datasets shows that HybridGazeNet has better accuracy and generalization ability compared with existing SOTA methods. The code will be released later.