 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced User Credit Risk Prediction Model using LightGBM, XGBoost and Tabnet with SMOTEENN
Aug 07, 2024Bank credit risk is a significant challenge in modern financial transactions, and the ability to identify qualified credit card holders among a large number of applicants is crucial for the profitability of a bank'sbank's credit card business. In the past, screening applicants'applicants' conditions often required a significant amount of manual labor, which was time-consuming and labor-intensive. Although the accuracy and reliability of previously used ML models have been continuously improving, the pursuit of more reliable and powerful AI intelligent models is undoubtedly the unremitting pursuit by major banks in the financial industry. In this study, we used a dataset of over 40,000 records provided by a commercial bank as the research object. We compared various dimensionality reduction techniques such as PCA and T-SNE for preprocessing high-dimensional datasets and performed in-depth adaptation and tuning of distributed models such as LightGBM and XGBoost, as well as deep models like Tabnet. After a series of research and processing, we obtained excellent research results by combining SMOTEENN with these techniques. The experiments demonstrated that LightGBM combined with PCA and SMOTEENN techniques can assist banks in accurately predicting potential high-quality customers, showing relatively outstanding performance compared to other models.
Real-Time Summarization of Twitter
Jul 11, 2024
In this paper, we describe our approaches to TREC Real-Time Summarization of Twitter. We focus on real time push notification scenario, which requires a system monitors the stream of sampled tweets and returns the tweets relevant and novel to given interest profiles. Dirichlet score with and with very little smoothing (baseline) are employed to classify whether a tweet is relevant to a given interest profile. Using metrics including Mean Average Precision (MAP, cumulative gain (CG) and discount cumulative gain (DCG), the experiment indicates that our approach has a good performance. It is also desired to remove the redundant tweets from the pushing queue. Due to the precision limit, we only describe the algorithm in this paper.
Online Learning of Multiple Tasks and Their Relationships : Testing on Spam Email Data and EEG Signals Recorded in Construction Fields
Jun 26, 2024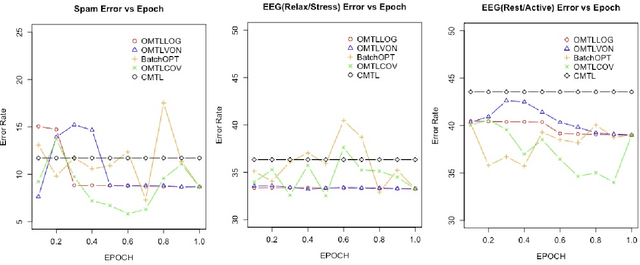

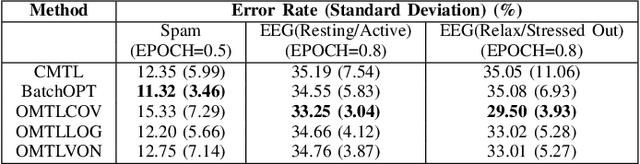
This paper examines an online multi-task learning (OMTL) method, which processes data sequentially to predict labels across related tasks. The framework learns task weights and their relatedness concurrently. Unlike previous models that assumed static task relatedness, our approach treats tasks as initially independent, updating their relatedness iteratively using newly calculated weight vectors. We introduced three rules to update the task relatedness matrix: OMTLCOV, OMTLLOG, and OMTLVON, and compared them against a conventional method (CMTL) that uses a fixed relatedness value. Performance evaluations on three datasets a spam dataset and two EEG datasets from construction workers under varying conditions demonstrated that our OMTL methods outperform CMTL, improving accuracy by 1\% to 3\% on EEG data, and maintaining low error rates around 12\% on the spam dataset.
Unsupervised Discovery of Object Landmarks as Structural Representations
Apr 12, 2018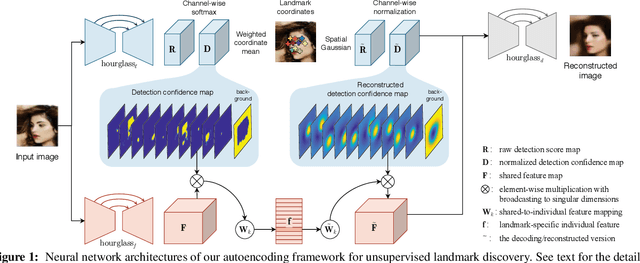
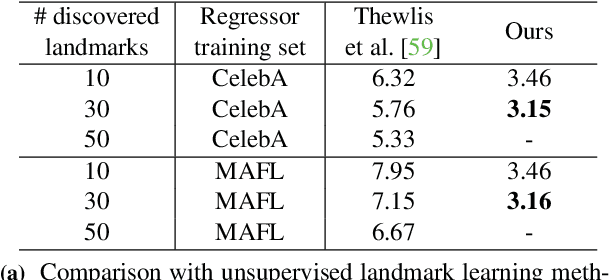

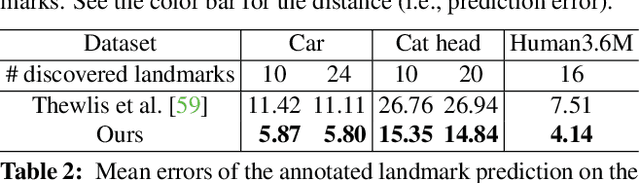
Deep neural networks can model images with rich latent representations, but they cannot naturally conceptualize structures of object categories in a human-perceptible way. This paper addresses the problem of learning object structures in an image modeling process without supervision. We propose an autoencoding formulation to discover landmarks as explicit structural representations. The encoding module outputs landmark coordinates, whose validity is ensured by constraints that reflect the necessary properties for landmarks. The decoding module takes the landmarks as a part of the learnable input representations in an end-to-end differentiable framework. Our discovered landmarks are semantically meaningful and more predictive of manually annotated landmarks than those discovered by previous methods. The coordinates of our landmarks are also complementary features to pretrained deep-neural-network representations in recognizing visual attributes. In addition, the proposed method naturally creates an unsupervised, perceptible interface to manipulate object shapes and decode images with controllable structures. The project webpage is at http://ytzhang.net/projects/lmdis-rep
* 48 pages