 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadFabric: Agentic AI System with Reasoning Capability for Radiology
Jun 17, 2025Chest X ray (CXR) imaging remains a critical diagnostic tool for thoracic conditions, but current automated systems face limitations in pathology coverage, diagnostic accuracy, and integration of visual and textual reasoning. To address these gaps, we propose RadFabric, a multi agent, multimodal reasoning framework that unifies visual and textual analysis for comprehensive CXR interpretation. RadFabric is built on the Model Context Protocol (MCP), enabling modularity, interoperability, and scalability for seamless integration of new diagnostic agents. The system employs specialized CXR agents for pathology detection, an Anatomical Interpretation Agent to map visual findings to precise anatomical structures, and a Reasoning Agent powered by large multimodal reasoning models to synthesize visual, anatomical, and clinical data into transparent and evidence based diagnoses. RadFabric achieves significant performance improvements, with near-perfect detection of challenging pathologies like fractures (1.000 accuracy) and superior overall diagnostic accuracy (0.799) compared to traditional systems (0.229 to 0.527). By integrating cross modal feature alignment and preference-driven reasoning, RadFabric advances AI-driven radiology toward transparent, anatomically precise, and clinically actionable CXR analysis.
Labits: Layered Bidirectional Time Surfaces Representation for Event Camera-based Continuous Dense Trajectory Estimation
Dec 12, 2024



Event cameras provide a compelling alternative to traditional frame-based sensors, capturing dynamic scenes with high temporal resolution and low latency. Moving objects trigger events with precise timestamps along their trajectory, enabling smooth continuous-time estimation. However, few works have attempted to optimize the information loss during event representation construction, imposing a ceiling on this task. Fully exploiting event cameras requires representations that simultaneously preserve fine-grained temporal information, stable and characteristic 2D visual features, and temporally consistent information density, an unmet challenge in existing representations. We introduce Labits: Layered Bidirectional Time Surfaces, a simple yet elegant representation designed to retain all these features. Additionally, we propose a dedicated module for extracting active pixel local optical flow (APLOF), significantly boosting the performance. Our approach achieves an impressive 49% reduction in trajectory end-point error (TEPE) compared to the previous state-of-the-art on the MultiFlow dataset. The code will be released upon acceptance.
Humble Teachers Teach Better Students for Semi-Supervised Object Detection
Jun 19, 2021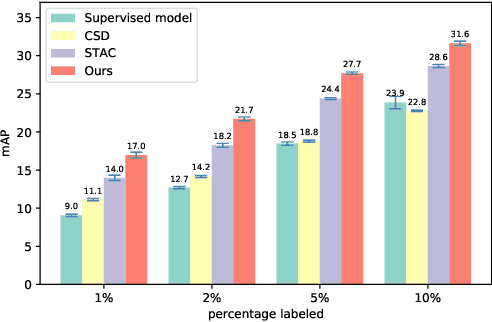
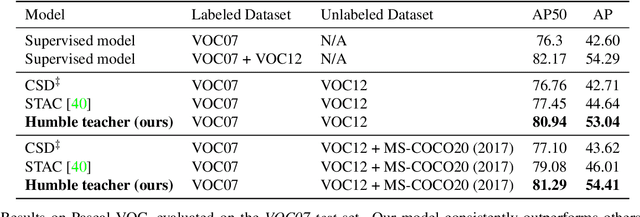

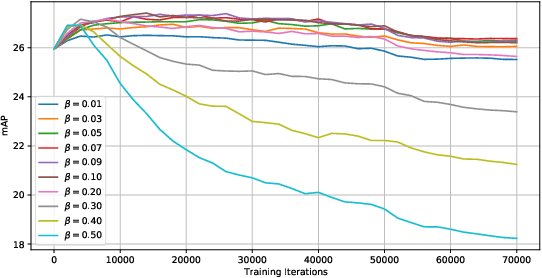
We propose a semi-supervised approach for contemporary object detectors following the teacher-student dual model framework. Our method is featured with 1) the exponential moving averaging strategy to update the teacher from the student online, 2) using plenty of region proposals and soft pseudo-labels as the student's training targets, and 3) a light-weighted detection-specific data ensemble for the teacher to generate more reliable pseudo-labels. Compared to the recent state-of-the-art -- STAC, which uses hard labels on sparsely selected hard pseudo samples, the teacher in our model exposes richer information to the student with soft-labels on many proposals. Our model achieves COCO-style AP of 53.04% on VOC07 val set, 8.4% better than STAC, when using VOC12 as unlabeled data. On MS-COCO, it outperforms prior work when only a small percentage of data is taken as labeled. It also reaches 53.8% AP on MS-COCO test-dev with 3.1% gain over the fully supervised ResNet-152 Cascaded R-CNN, by tapping into unlabeled data of a similar size to the labeled data.
Unsupervised Discovery of Object Landmarks as Structural Representations
Apr 12, 2018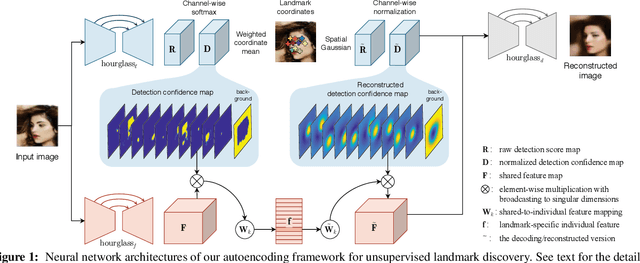
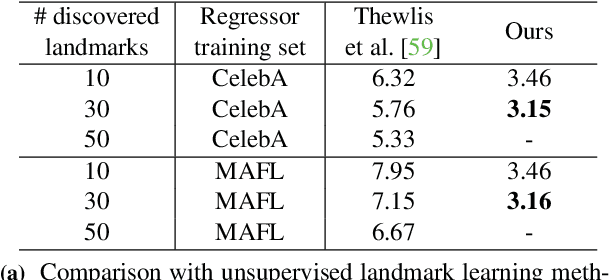

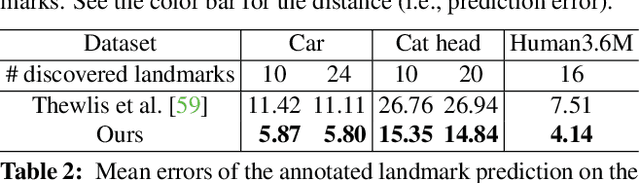
Deep neural networks can model images with rich latent representations, but they cannot naturally conceptualize structures of object categories in a human-perceptible way. This paper addresses the problem of learning object structures in an image modeling process without supervision. We propose an autoencoding formulation to discover landmarks as explicit structural representations. The encoding module outputs landmark coordinates, whose validity is ensured by constraints that reflect the necessary properties for landmarks. The decoding module takes the landmarks as a part of the learnable input representations in an end-to-end differentiable framework. Our discovered landmarks are semantically meaningful and more predictive of manually annotated landmarks than those discovered by previous methods. The coordinates of our landmarks are also complementary features to pretrained deep-neural-network representations in recognizing visual attributes. In addition, the proposed method naturally creates an unsupervised, perceptible interface to manipulate object shapes and decode images with controllable structures. The project webpage is at http://ytzhang.net/projects/lmdis-rep
* 48 pages