 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-R1: Reinforcing 3D Constraints for Text-to-Video Generation
Apr 27, 2026Recent video foundation models demonstrate impressive visual synthesis but frequently suffer from geometric inconsistencies. While existing methods attempt to inject 3D priors via architectural modifications, they often incur high computational costs and limit scalability. We propose World-R1, a framework that aligns video generation with 3D constraints through reinforcement learning. To facilitate this alignment, we introduce a specialized pure text dataset tailored for world simulation. Utilizing Flow-GRPO, we optimize the model using feedback from pre-trained 3D foundation models and vision-language models to enforce structural coherence without altering the underlying architecture. We further employ a periodic decoupled training strategy to balance rigid geometric consistency with dynamic scene fluidity. Extensive evaluations reveal that our approach significantly enhances 3D consistency while preserving the original visual quality of the foundation model, effectively bridging the gap between video generation and scalable world simulation.
From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
Apr 24, 2026Individual agent capabilities have advanced rapidly through modular skills and tool integrations, yet multi-agent systems remain constrained by fixed team structures, tightly coupled coordination logic, and session-bound learning. We argue that this reflects a deeper absence: a principled organisational layer that governs how a workforce of agents is assembled, governed, and improved over time, decoupled from what individual agents know. To fill this gap, we introduce \emph{OneManCompany (OMC)}, a framework that elevates multi-agent systems to the organisational level. OMC encapsulates skills, tools, and runtime configurations into portable agent identities called \emph{Talents}, orchestrated through typed organisational interfaces that abstract over heterogeneous backends. A community-driven \emph{Talent Market} enables on-demand recruitment, allowing the organisation to close capability gaps and reconfigure itself dynamically during execution. Organisational decision-making is operationalised through an \emph{Explore-Execute-Review} ($\text{E}^2$R) tree search, which unifies planning, execution, and evaluation in a single hierarchical loop: tasks are decomposed top-down into accountable units and execution outcomes are aggregated bottom-up to drive systematic review and refinement. This loop provides formal guarantees on termination and deadlock freedom while mirroring the feedback mechanisms of human enterprises. Together, these contributions transform multi-agent systems from static, pre-configured pipelines into self-organising and self-improving AI organisations capable of adapting to open-ended tasks across diverse domains. Empirical evaluation on PRDBench shows that OMC achieves an $84.67\%$ success rate, surpassing the state of the art by $15.48$ percentage points, with cross-domain case studies further demonstrating its generality.
InfoSeeker: A Scalable Hierarchical Parallel Agent Framework for Web Information Seeking
Apr 03, 2026Recent agentic search systems have made substantial progress by emphasising deep, multi-step reasoning. However, this focus often overlooks the challenges of wide-scale information synthesis, where agents must aggregate large volumes of heterogeneous evidence across many sources. As a result, most existing large language model agent systems face severe limitations in data-intensive settings, including context saturation, cascading error propagation, and high end-to-end latency. To address these challenges, we present \framework, a hierarchical framework based on principle of near-decomposability, containing a strategic \textit{Host}, multiple \textit{Managers} and parallel \textit{Workers}. By leveraging aggregation and reflection mechanisms at the Manager layer, our framework enforces strict context isolation to prevent saturation and error propagation. Simultaneously, the parallelism in worker layer accelerates the speed of overall task execution, mitigating the significant latency. Our evaluation on two complementary benchmarks demonstrates both efficiency ($ 3-5 \times$ speed-up) and effectiveness, achieving a $8.4\%$ success rate on WideSearch-en and $52.9\%$ accuracy on BrowseComp-zh. The code is released at https://github.com/agent-on-the-fly/InfoSeeker
Act While Thinking: Accelerating LLM Agents via Pattern-Aware Speculative Tool Execution
Mar 19, 2026LLM-powered agents are emerging as a dominant paradigm for autonomous task solving. Unlike standard inference workloads, agents operate in a strictly serial "LLM-tool" loop, where the LLM must wait for external tool execution at every step. This execution model introduces severe latency bottlenecks. To address this problem, we propose PASTE, a Pattern-Aware Speculative Tool Execution method designed to hide tool latency through speculation. PASTE is based on the insight that although agent requests are semantically diverse, they exhibit stable application level control flows (recurring tool-call sequences) and predictable data dependencies (parameter passing between tools). By exploiting these properties, PASTE improves agent serving performance through speculative tool execution. Experimental results against state of the art baselines show that PASTE reduces average task completion time by 48.5% and improves tool execution throughput by 1.8x.
Steering Externalities: Benign Activation Steering Unintentionally Increases Jailbreak Risk for Large Language Models
Feb 03, 2026Activation steering is a practical post-training model alignment technique to enhance the utility of Large Language Models (LLMs). Prior to deploying a model as a service, developers can steer a pre-trained model toward specific behavioral objectives, such as compliance or instruction adherence, without the need for retraining. This process is as simple as adding a steering vector to the model's internal representations. However, this capability unintentionally introduces critical and under-explored safety risks. We identify a phenomenon termed Steering Externalities, where steering vectors derived from entirely benign datasets-such as those enforcing strict compliance or specific output formats like JSON-inadvertently erode safety guardrails. Experiments reveal that these interventions act as a force multiplier, creating new vulnerabilities to jailbreaks and increasing attack success rates to over 80% on standard benchmarks by bypassing the initial safety alignment. Ultimately, our results expose a critical blind spot in deployment: benign activation steering systematically erodes the "safety margin," rendering models more vulnerable to black-box attacks and proving that inference-time utility improvements must be rigorously audited for unintended safety externalities.
On the Limitations of Rank-One Model Editing in Answering Multi-hop Questions
Jan 08, 2026Recent advances in Knowledge Editing (KE), particularly Rank-One Model Editing (ROME), show superior efficiency over fine-tuning and in-context learning for updating single-hop facts in transformers. However, these methods face significant challenges when applied to multi-hop reasoning tasks requiring knowledge chaining. In this work, we study the effect of editing knowledge with ROME on different layer depths and identify three key failure modes. First, the "hopping-too-late" problem occurs as later layers lack access to necessary intermediate representations. Second, generalization ability deteriorates sharply when editing later layers. Third, the model overfits to edited knowledge, incorrectly prioritizing edited-hop answers regardless of context. To mitigate the issues of "hopping-too-late" and generalisation decay, we propose Redundant Editing, a simple yet effective strategy that enhances multi-hop reasoning. Our experiments demonstrate that this approach can improve accuracy on 2-hop questions by at least 15.5 percentage points, representing a 96% increase over the previous single-edit strategy, while trading off some specificity and language naturalness.
$ΔL$ Normalization: Rethink Loss Aggregation in RLVR
Sep 09, 2025We propose $\Delta L$ Normalization, a simple yet effective loss aggregation method tailored to the characteristic of dynamic generation lengths in Reinforcement Learning with Verifiable Rewards (RLVR). Recently, RLVR has demonstrated strong potential in improving the reasoning capabilities of large language models (LLMs), but a major challenge lies in the large variability of response lengths during training, which leads to high gradient variance and unstable optimization. Although previous methods such as GRPO, DAPO, and Dr. GRPO introduce different loss normalization terms to address this issue, they either produce biased estimates or still suffer from high gradient variance. By analyzing the effect of varying lengths on policy loss both theoretically and empirically, we reformulate the problem as finding a minimum-variance unbiased estimator. Our proposed $\Delta L$ Normalization not only provides an unbiased estimate of the true policy loss but also minimizes gradient variance in theory. Extensive experiments show that it consistently achieves superior results across different model sizes, maximum lengths, and tasks. Our code will be made public at https://github.com/zerolllin/Delta-L-Normalization.
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
May 19, 2025Reinforcement learning (RL) has become a cornerstone for enhancing the reasoning capabilities of large language models (LLMs), with recent innovations such as Group Relative Policy Optimization (GRPO) demonstrating exceptional effectiveness. In this study, we identify a critical yet underexplored issue in RL training: low-probability tokens disproportionately influence model updates due to their large gradient magnitudes. This dominance hinders the effective learning of high-probability tokens, whose gradients are essential for LLMs' performance but are substantially suppressed. To mitigate this interference, we propose two novel methods: Advantage Reweighting and Low-Probability Token Isolation (Lopti), both of which effectively attenuate gradients from low-probability tokens while emphasizing parameter updates driven by high-probability tokens. Our approaches promote balanced updates across tokens with varying probabilities, thereby enhancing the efficiency of RL training. Experimental results demonstrate that they substantially improve the performance of GRPO-trained LLMs, achieving up to a 46.2% improvement in K&K Logic Puzzle reasoning tasks. Our implementation is available at https://github.com/zhyang2226/AR-Lopti.
RIGID: A Training-free and Model-Agnostic Framework for Robust AI-Generated Image Detection
May 30, 2024



The rapid advances in generative AI models have empowered the creation of highly realistic images with arbitrary content, raising concerns about potential misuse and harm, such as Deepfakes. Current research focuses on training detectors using large datasets of generated images. However, these training-based solutions are often computationally expensive and show limited generalization to unseen generated images. In this paper, we propose a training-free method to distinguish between real and AI-generated images. We first observe that real images are more robust to tiny noise perturbations than AI-generated images in the representation space of vision foundation models. Based on this observation, we propose RIGID, a training-free and model-agnostic method for robust AI-generated image detection. RIGID is a simple yet effective approach that identifies whether an image is AI-generated by comparing the representation similarity between the original and the noise-perturbed counterpart. Our evaluation on a diverse set of AI-generated images and benchmarks shows that RIGID significantly outperforms existing trainingbased and training-free detectors. In particular, the average performance of RIGID exceeds the current best training-free method by more than 25%. Importantly, RIGID exhibits strong generalization across different image generation methods and robustness to image corruptions.
Position Engineering: Boosting Large Language Models through Positional Information Manipulation
Apr 17, 2024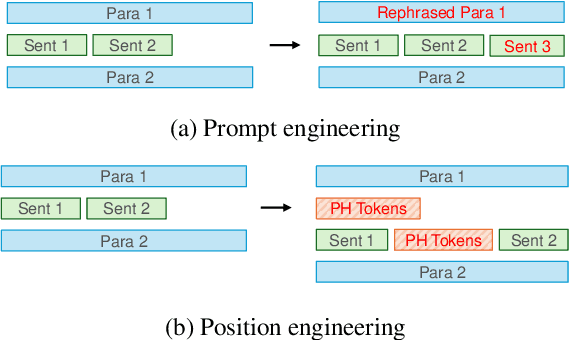
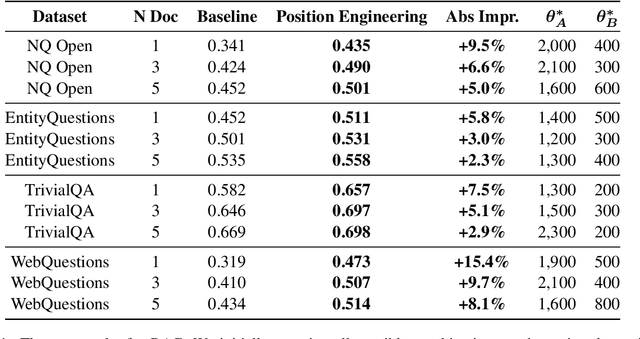
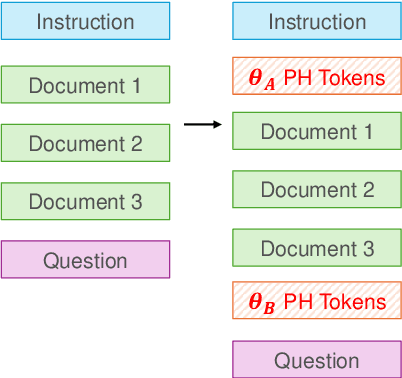
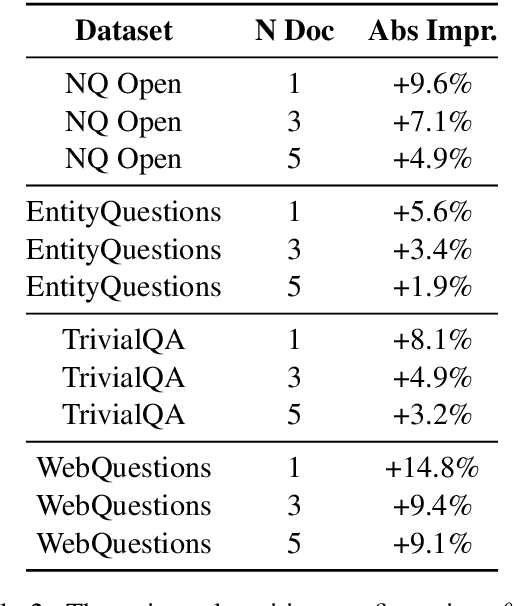
The performance of large language models (LLMs) is significantly influenced by the quality of the prompts provided. In response, researchers have developed enormous prompt engineering strategies aimed at modifying the prompt text to enhance task performance. In this paper, we introduce a novel technique termed position engineering, which offers a more efficient way to guide large language models. Unlike prompt engineering, which requires substantial effort to modify the text provided to LLMs, position engineering merely involves altering the positional information in the prompt without modifying the text itself. We have evaluated position engineering in two widely-used LLM scenarios: retrieval-augmented generation (RAG) and in-context learning (ICL). Our findings show that position engineering substantially improves upon the baseline in both cases. Position engineering thus represents a promising new strategy for exploiting the capabilities of large language models.