 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Teacher-Aware Learning
Oct 17, 2021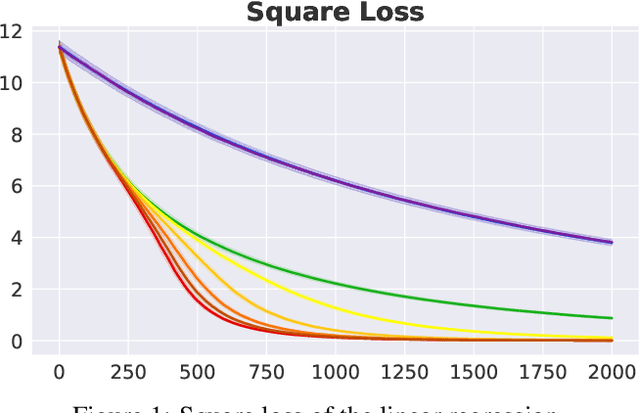

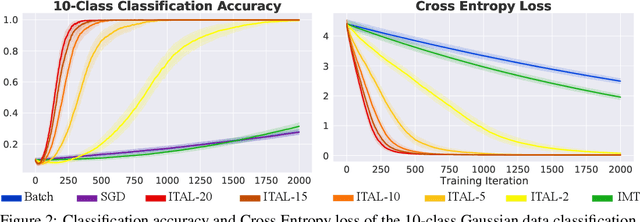

In human pedagogy, teachers and students can interact adaptively to maximize communication efficiency. The teacher adjusts her teaching method for different students, and the student, after getting familiar with the teacher's instruction mechanism, can infer the teacher's intention to learn faster. Recently, the benefits of integrating this cooperative pedagogy into machine concept learning in discrete spaces have been proved by multiple works. However, how cooperative pedagogy can facilitate machine parameter learning hasn't been thoroughly studied. In this paper, we propose a gradient optimization based teacher-aware learner who can incorporate teacher's cooperative intention into the likelihood function and learn provably faster compared with the naive learning algorithms used in previous machine teaching works. We give theoretical proof that the iterative teacher-aware learning (ITAL) process leads to local and global improvements. We then validate our algorithms with extensive experiments on various tasks including regression, classification, and inverse reinforcement learning using synthetic and real data. We also show the advantage of modeling teacher-awareness when agents are learning from human teachers.
Emergence of Theory of Mind Collaboration in Multiagent Systems
Sep 30, 2021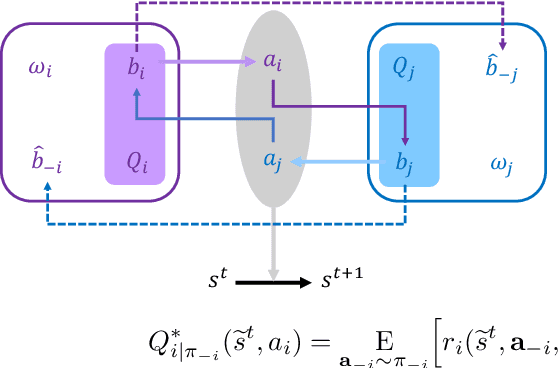

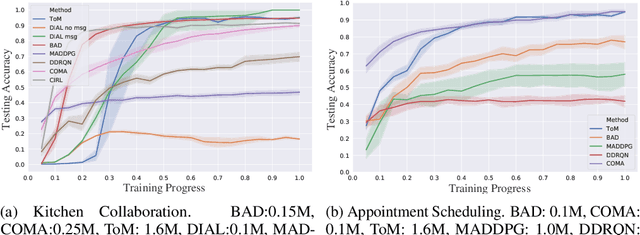
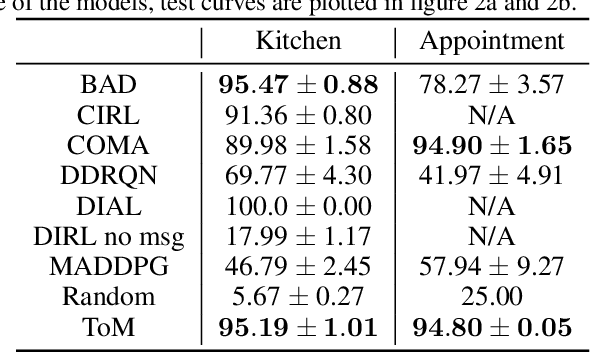
Currently, in the study of multiagent systems, the intentions of agents are usually ignored. Nonetheless, as pointed out by Theory of Mind (ToM), people regularly reason about other's mental states, including beliefs, goals, and intentions, to obtain performance advantage in competition, cooperation or coalition. However, due to its intrinsic recursion and intractable modeling of distribution over belief, integrating ToM in multiagent planning and decision making is still a challenge. In this paper, we incorporate ToM in multiagent partially observable Markov decision process (POMDP) and propose an adaptive training algorithm to develop effective collaboration between agents with ToM. We evaluate our algorithms with two games, where our algorithm surpasses all previous decentralized execution algorithms without modeling ToM.
Show Me What You Can Do: Capability Calibration on Reachable Workspace for Human-Robot Collaboration
Mar 06, 2021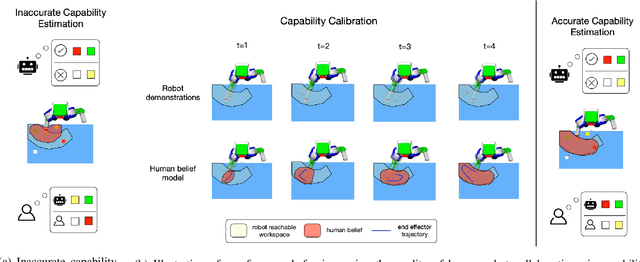
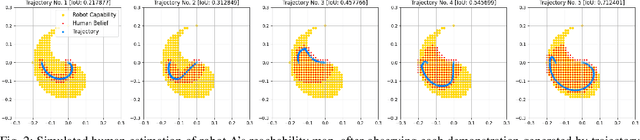
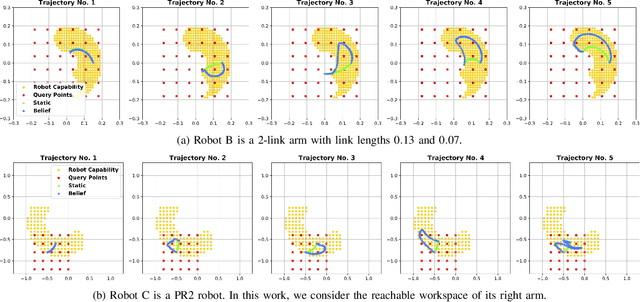

Aligning humans' assessment of what a robot can do with its true capability is crucial for establishing a common ground between human and robot partners when they collaborate on a joint task. In this work, we propose an approach to calibrate humans' estimate of a robot's reachable workspace through a small number of demonstrations before collaboration. We develop a novel motion planning method, REMP (Reachability-Expressive Motion Planning), which jointly optimizes the physical cost and the expressiveness of robot motion to reveal the robot's motion capability to a human observer. Our experiments with human participants demonstrate that a short calibration using REMP can effectively bridge the gap between what a non-expert user thinks a robot can reach and the ground-truth. We show that this calibration procedure not only results in better user perception, but also promotes more efficient human-robot collaborations in a subsequent joint task.
Emergence of Pragmatics from Referential Game between Theory of Mind Agents
Jan 21, 2020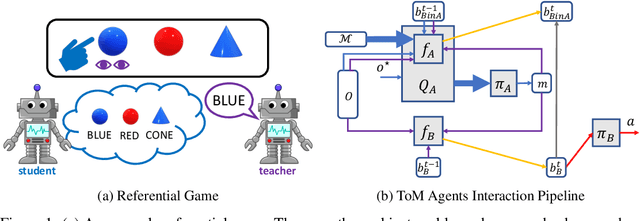
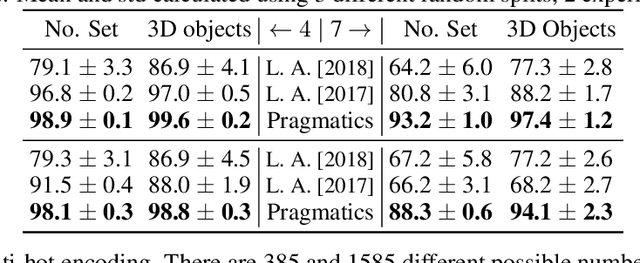
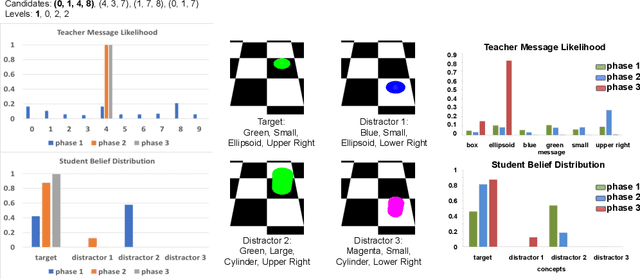
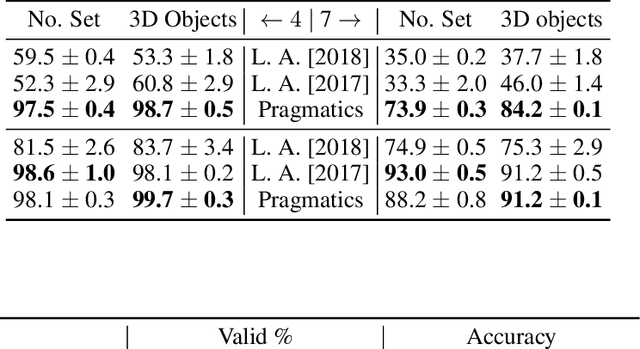
Pragmatics studies how context can contribute to language meanings [1]. In human communication, language is never interpreted out of context, and sentences can usually convey more information than their literal meanings [2]. However, this mechanism is missing in most multi-agent systems [3, 4, 5, 6], restricting the communication efficiency and the capability of human-agent interaction. In this paper, we propose an algorithm, using which agents can spontaneously learn the ability to "read between lines" without any explicit hand-designed rules. We integrate the theory of mind (ToM) [7, 8] in a cooperative multi-agent pedagogical situation and propose an adaptive reinforcement learning (RL) algorithm to develop a communication protocol. ToM is a profound cognitive science concept, claiming that people regularly reason about other's mental states, including beliefs, goals, and intentions, to obtain performance advantage in competition, cooperation or coalition. With this ability, agents consider language as not only messages but also rational acts reflecting others' hidden states. Our experiments demonstrate the advantage of pragmatic protocols over non-pragmatic protocols. We also show the teaching complexity following the pragmatic protocol empirically approximates to recursive teaching dimension (RTD).
Discriminative Bimodal Networks for Visual Localization and Detection with Natural Language Queries
Apr 17, 2017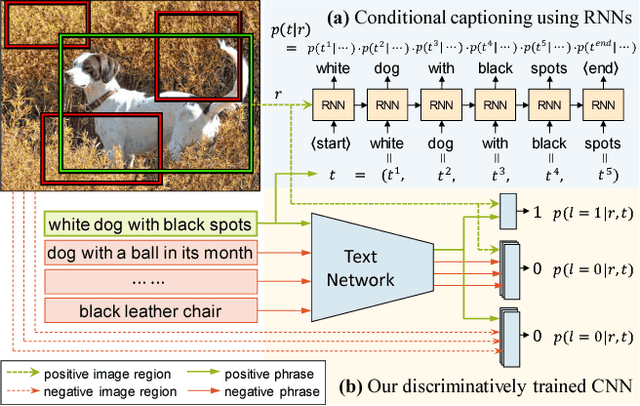
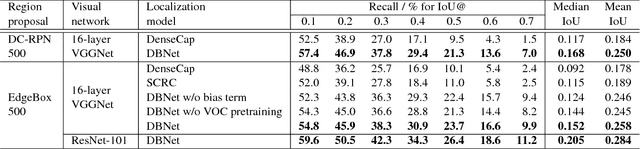
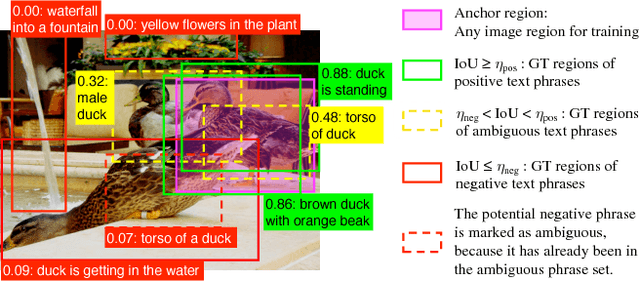
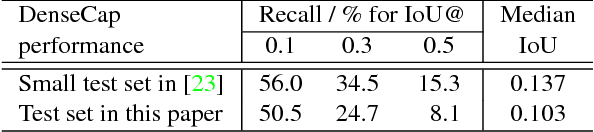
Associating image regions with text queries has been recently explored as a new way to bridge visual and linguistic representations. A few pioneering approaches have been proposed based on recurrent neural language models trained generatively (e.g., generating captions), but achieving somewhat limited localization accuracy. To better address natural-language-based visual entity localization, we propose a discriminative approach. We formulate a discriminative bimodal neural network (DBNet), which can be trained by a classifier with extensive use of negative samples. Our training objective encourages better localization on single images, incorporates text phrases in a broad range, and properly pairs image regions with text phrases into positive and negative examples. Experiments on the Visual Genome dataset demonstrate the proposed DBNet significantly outperforms previous state-of-the-art methods both for localization on single images and for detection on multiple images. We we also establish an evaluation protocol for natural-language visual detection.