 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTravelBench: A Broader Real-World Benchmark for Multi-Turn and Tool-Using Travel Planning
Jan 05, 2026Travel planning is a natural real-world task to test large language models (LLMs) planning and tool-use abilities. Although prior work has studied LLM performance on travel planning, existing settings still differ from real-world needs, mainly due to limited domain coverage, insufficient modeling of users' implicit preferences in multi-turn conversations, and a lack of clear evaluation of agents' capability boundaries. To mitigate these gaps, we propose \textbf{TravelBench}, a benchmark for fully real-world travel planning. We collect user queries, user profile and tools from real scenarios, and construct three subtasks-Single-Turn, Multi-Turn, and Unsolvable-to evaluate agent's three core capabilities in real settings: (1) solving problems autonomously, (2) interacting with users over multiple turns to refine requirements, and (3) recognizing the limits of own abilities. To enable stable tool invocation and reproducible evaluation, we cache real tool-call results and build a sandbox environment that integrates ten travel-related tools. Agents can combine these tools to solve most practical travel planning problems, and our systematic verification demonstrates the stability of the proposed benchmark. We further evaluate multiple LLMs on TravelBench and conduct an in-depth analysis of their behaviors and performance. TravelBench provides a practical and reproducible evaluation benchmark to advance research on LLM agents for travel planning.\footnote{Our code and data will be available after internal review.
AMAP Agentic Planning Technical Report
Dec 31, 2025We present STAgent, an agentic large language model tailored for spatio-temporal understanding, designed to solve complex tasks such as constrained point-of-interest discovery and itinerary planning. STAgent is a specialized model capable of interacting with ten distinct tools within spatio-temporal scenarios, enabling it to explore, verify, and refine intermediate steps during complex reasoning. Notably, STAgent effectively preserves its general capabilities. We empower STAgent with these capabilities through three key contributions: (1) a stable tool environment that supports over ten domain-specific tools, enabling asynchronous rollout and training; (2) a hierarchical data curation framework that identifies high-quality data like a needle in a haystack, curating high-quality queries with a filter ratio of 1:10,000, emphasizing both diversity and difficulty; and (3) a cascaded training recipe that starts with a seed SFT stage acting as a guardian to measure query difficulty, followed by a second SFT stage fine-tuned on queries with high certainty, and an ultimate RL stage that leverages data of low certainty. Initialized with Qwen3-30B-A3B to establish a strong SFT foundation and leverage insights into sample difficulty, STAgent yields promising performance on TravelBench while maintaining its general capabilities across a wide range of general benchmarks, thereby demonstrating the effectiveness of our proposed agentic model.
TravelBench: A Real-World Benchmark for Multi-Turn and Tool-Augmented Travel Planning
Dec 27, 2025Large language model (LLM) agents have demonstrated strong capabilities in planning and tool use. Travel planning provides a natural and high-impact testbed for these capabilities, as it requires multi-step reasoning, iterative preference elicitation through interaction, and calls to external tools under evolving constraints. Prior work has studied LLMs on travel-planning tasks, but existing settings are limited in domain coverage and multi-turn interaction. As a result, they cannot support dynamic user-agent interaction and therefore fail to comprehensively assess agent capabilities. In this paper, we introduce TravelBench, a real-world travel-planning benchmark featuring multi-turn interaction and tool use. We collect user requests from real-world scenarios and construct three subsets-multi-turn, single-turn, and unsolvable-to evaluate different aspects of agent performance. For stable and reproducible evaluation, we build a controlled sandbox environment with 10 travel-domain tools, providing deterministic tool outputs for reliable reasoning. We evaluate multiple LLMs on TravelBench and conduct an analysis of their behaviors and performance. TravelBench offers a practical and reproducible benchmark for advancing LLM agents in travel planning.
Variational Polya Tree
Oct 26, 2025Density estimation is essential for generative modeling, particularly with the rise of modern neural networks. While existing methods capture complex data distributions, they often lack interpretability and uncertainty quantification. Bayesian nonparametric methods, especially the \polya tree, offer a robust framework that addresses these issues by accurately capturing function behavior over small intervals. Traditional techniques like Markov chain Monte Carlo (MCMC) face high computational complexity and scalability limitations, hindering the use of Bayesian nonparametric methods in deep learning. To tackle this, we introduce the variational \polya tree (VPT) model, which employs stochastic variational inference to compute posterior distributions. This model provides a flexible, nonparametric Bayesian prior that captures latent densities and works well with stochastic gradient optimization. We also leverage the joint distribution likelihood for a more precise variational posterior approximation than traditional mean-field methods. We evaluate the model performance on both real data and images, and demonstrate its competitiveness with other state-of-the-art deep density estimation methods. We also explore its ability in enhancing interpretability and uncertainty quantification. Code is available at https://github.com/howardchanth/var-polya-tree.
CrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Sep 17, 2025High-quality annotated data is a cornerstone of modern Natural Language Processing (NLP). While recent methods begin to leverage diverse annotation sources-including Large Language Models (LLMs), Small Language Models (SLMs), and human experts-they often focus narrowly on the labeling step itself. A critical gap remains in the holistic process control required to manage these sources dynamically, addressing complex scheduling and quality-cost trade-offs in a unified manner. Inspired by real-world crowdsourcing companies, we introduce CrowdAgent, a multi-agent system that provides end-to-end process control by integrating task assignment, data annotation, and quality/cost management. It implements a novel methodology that rationally assigns tasks, enabling LLMs, SLMs, and human experts to advance synergistically in a collaborative annotation workflow. We demonstrate the effectiveness of CrowdAgent through extensive experiments on six diverse multimodal classification tasks. The source code and video demo are available at https://github.com/QMMMS/CrowdAgent.
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Aug 20, 2025We present DuPO, a dual learning-based preference optimization framework that generates annotation-free feedback via a generalized duality. DuPO addresses two key limitations: Reinforcement Learning with Verifiable Rewards (RLVR)'s reliance on costly labels and applicability restricted to verifiable tasks, and traditional dual learning's restriction to strictly dual task pairs (e.g., translation and back-translation). Specifically, DuPO decomposes a primal task's input into known and unknown components, then constructs its dual task to reconstruct the unknown part using the primal output and known information (e.g., reversing math solutions to recover hidden variables), broadening applicability to non-invertible tasks. The quality of this reconstruction serves as a self-supervised reward to optimize the primal task, synergizing with LLMs' ability to instantiate both tasks via a single model. Empirically, DuPO achieves substantial gains across diverse tasks: it enhances the average translation quality by 2.13 COMET over 756 directions, boosts the mathematical reasoning accuracy by an average of 6.4 points on three challenge benchmarks, and enhances performance by 9.3 points as an inference-time reranker (trading computation for accuracy). These results position DuPO as a scalable, general, and annotation-free paradigm for LLM optimization.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
MoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
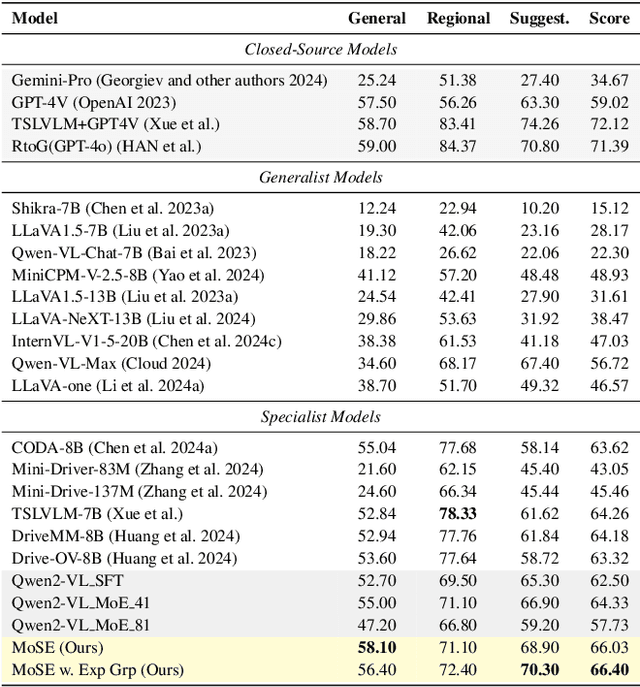
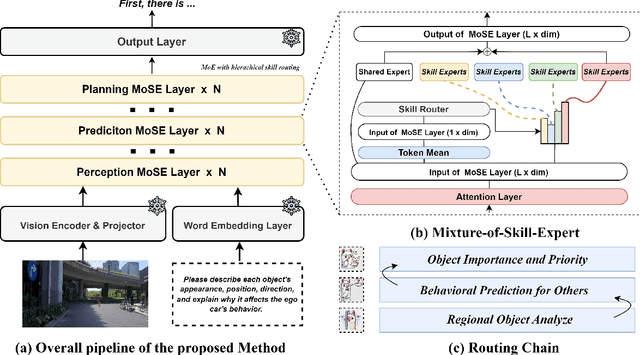
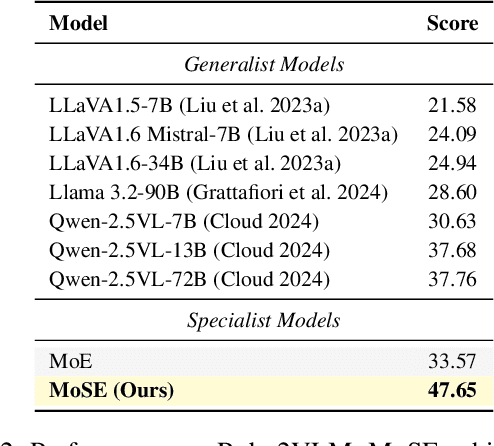
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
From Tens of Hours to Tens of Thousands: Scaling Back-Translation for Speech Recognition
May 22, 2025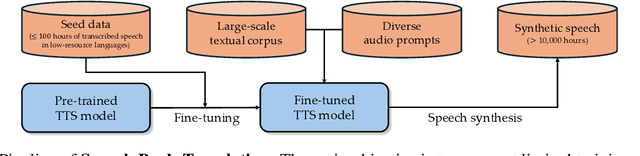
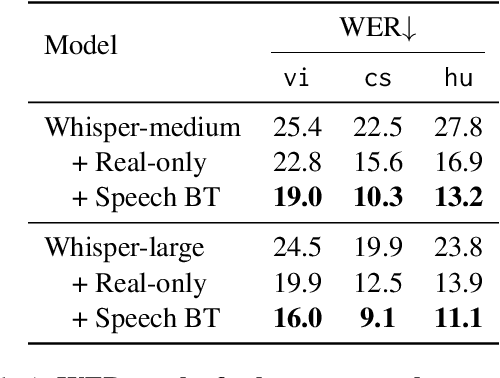
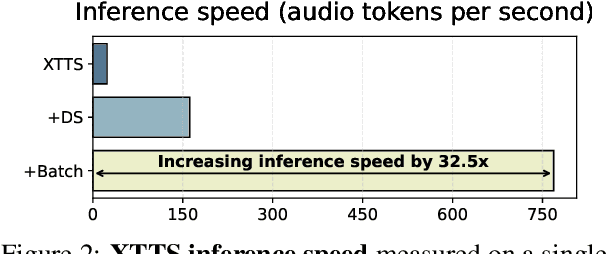

Recent advances in Automatic Speech Recognition (ASR) have been largely fueled by massive speech corpora. However, extending coverage to diverse languages with limited resources remains a formidable challenge. This paper introduces Speech Back-Translation, a scalable pipeline that improves multilingual ASR models by converting large-scale text corpora into synthetic speech via off-the-shelf text-to-speech (TTS) models. We demonstrate that just tens of hours of real transcribed speech can effectively train TTS models to generate synthetic speech at hundreds of times the original volume while maintaining high quality. To evaluate synthetic speech quality, we develop an intelligibility-based assessment framework and establish clear thresholds for when synthetic data benefits ASR training. Using Speech Back-Translation, we generate more than 500,000 hours of synthetic speech in ten languages and continue pre-training Whisper-large-v3, achieving average transcription error reductions of over 30\%. These results highlight the scalability and effectiveness of Speech Back-Translation for enhancing multilingual ASR systems.
RFUAV: A Benchmark Dataset for Unmanned Aerial Vehicle Detection and Identification
Mar 12, 2025



In this paper, we propose RFUAV as a new benchmark dataset for radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification and address the following challenges: Firstly, many existing datasets feature a restricted variety of drone types and insufficient volumes of raw data, which fail to meet the demands of practical applications. Secondly, existing datasets often lack raw data covering a broad range of signal-to-noise ratios (SNR), or do not provide tools for transforming raw data to different SNR levels. This limitation undermines the validity of model training and evaluation. Lastly, many existing datasets do not offer open-access evaluation tools, leading to a lack of unified evaluation standards in current research within this field. RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37 distinct UAVs using the Universal Software Radio Peripheral (USRP) device in real-world environments. Through in-depth analysis of the RF data in RFUAV, we define a drone feature sequence called RF drone fingerprint, which aids in distinguishing drone signals. In addition to the dataset, RFUAV provides a baseline preprocessing method and model evaluation tools. Rigorous experiments demonstrate that these preprocessing methods achieve state-of-the-art (SOTA) performance using the provided evaluation tools. The RFUAV dataset and baseline implementation are publicly available at https://github.com/kitoweeknd/RFUAV/.