 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-Aware Visual Cropping: Enhancing Fine-Grained VQA with Attention-Guided Subimage
Jan 30, 2026Multimodal Large Language Models (MLLMs) show strong performance in Visual Question Answering (VQA) but remain limited in fine-grained reasoning due to low-resolution inputs and noisy attention aggregation. We propose \textbf{Head Aware Visual Cropping (HAVC)}, a training-free method that improves visual grounding by leveraging a selectively refined subset of attention heads. HAVC first filters heads through an OCR-based diagnostic task, ensuring that only those with genuine grounding ability are retained. At inference, these heads are further refined using spatial entropy for stronger spatial concentration and gradient sensitivity for predictive contribution. The fused signals produce a reliable Visual Cropping Guidance Map, which highlights the most task-relevant region and guides the cropping of a subimage subsequently provided to the MLLM together with the image-question pair. Extensive experiments on multiple fine-grained VQA benchmarks demonstrate that HAVC consistently outperforms state-of-the-art cropping strategies, achieving more precise localization, stronger visual grounding, providing a simple yet effective strategy for enhancing precision in MLLMs.
SatAOI: Delimitating Area of Interest for Swing-Arm Troweling Robot for Construction
May 08, 2025In concrete troweling for building construction, robots can significantly reduce workload and improve automation level. However, as a primary task of coverage path planning (CPP) for troweling, delimitating area of interest (AOI) in complex scenes is still challenging, especially for swing-arm robots with more complex working modes. Thus, this research proposes an algorithm to delimitate AOI for swing-arm troweling robot (SatAOI algorithm). By analyzing characteristics of the robot and obstacle maps, mathematical models and collision principles are established. On this basis, SatAOI algorithm achieves AOI delimitation by global search and collision detection. Experiments on different obstacle maps indicate that AOI can be effectively delimitated in scenes under different complexity, and the algorithm can fully consider the connectivity of obstacle maps. This research serves as a foundation for CPP algorithm and full process simulation of swing-arm troweling robots.
RFUAV: A Benchmark Dataset for Unmanned Aerial Vehicle Detection and Identification
Mar 12, 2025



In this paper, we propose RFUAV as a new benchmark dataset for radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification and address the following challenges: Firstly, many existing datasets feature a restricted variety of drone types and insufficient volumes of raw data, which fail to meet the demands of practical applications. Secondly, existing datasets often lack raw data covering a broad range of signal-to-noise ratios (SNR), or do not provide tools for transforming raw data to different SNR levels. This limitation undermines the validity of model training and evaluation. Lastly, many existing datasets do not offer open-access evaluation tools, leading to a lack of unified evaluation standards in current research within this field. RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37 distinct UAVs using the Universal Software Radio Peripheral (USRP) device in real-world environments. Through in-depth analysis of the RF data in RFUAV, we define a drone feature sequence called RF drone fingerprint, which aids in distinguishing drone signals. In addition to the dataset, RFUAV provides a baseline preprocessing method and model evaluation tools. Rigorous experiments demonstrate that these preprocessing methods achieve state-of-the-art (SOTA) performance using the provided evaluation tools. The RFUAV dataset and baseline implementation are publicly available at https://github.com/kitoweeknd/RFUAV/.
Impact of color and mixing proportion of synthetic point clouds on semantic segmentation
Dec 26, 2024



Semantic segmentation of point clouds is essential for understanding the built environment, and a large amount of high-quality data is required for training deep learning models. Despite synthetic point clouds (SPC) having the potential to compensate for the shortage of real data, how to exploit the benefits of SPC is still open. Therefore, this study systematically investigates how color and mixing proportion of SPC impact semantic segmentation for the first time. First, a new method to mimic the scanning process and generate SPC based on BIM is proposed, to create a synthetic dataset with consistent colors of BIM (UniSPC) and a synthetic dataset with real colors (RealSPC) respectively. Subsequently, by integrating with the S3DIS dataset, further experiments on PointNet, PointNet++, and DGCNN are conducted. Meanwhile, benchmark experiments and new evaluation metrics are introduced to better evaluate the performance of different models. Experiments show that synthetic color significantly impacts model performance, the performance for common components of the models trained with pure RealSPC is comparable to models with real data, and RealSPC contributes average improvements of 14.1% on overall accuracy and 7.3% on mIoU than UniSPC. Furthermore, the proportion of SPC also has a significant impact on the performance. In mixing training experiments, adding more than 70% SPC achieves an average of 3.9% on overall accuracy and 3.4% on mIoU better than benchmark on three models. It is also revealed that for large flat elements such as floors, ceilings, and walls, the SPC can even replace real point clouds without compromising model performance.
What makes a good BIM design: quantitative linking between design behavior and quality
Nov 14, 2024



In the Architecture Engineering & Construction (AEC) industry, how design behaviors impact design quality remains unclear. This study proposes a novel approach, which, for the first time, identifies and quantitatively describes the relationship between design behaviors and quality of design based on Building Information Modeling (BIM). Real-time collection and log mining are integrated to collect raw data of design behaviors. Feature engineering and various machine learning models are then utilized for quantitative modeling and interpretation. Results confirm an existing quantifiable relationship which can be learned by various models. The best-performing model using Extremely Random Trees achieved an R2 value of 0.88 on the test set. Behavioral features related to designer's skill level and changes of design intentions are identified to have significant impacts on design quality. These findings deepen our understanding of the design process and help forming BIM designs with better quality.
Establishing Rigorous and Cost-effective Clinical Trials for Artificial Intelligence Models
Jul 11, 2024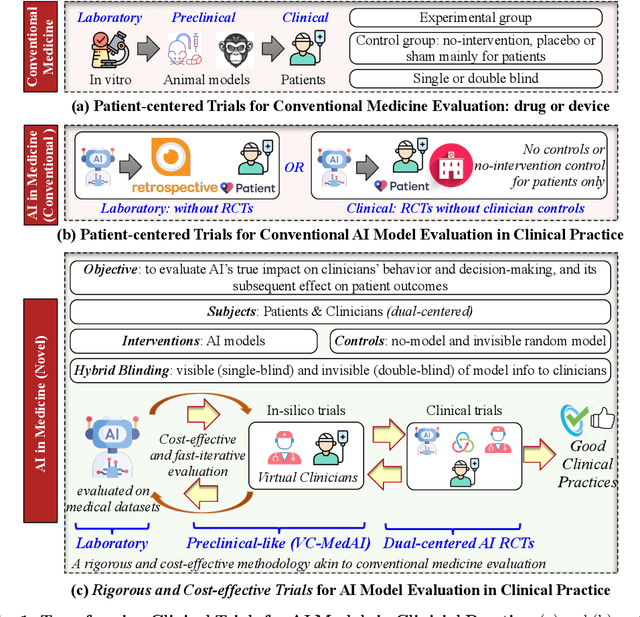
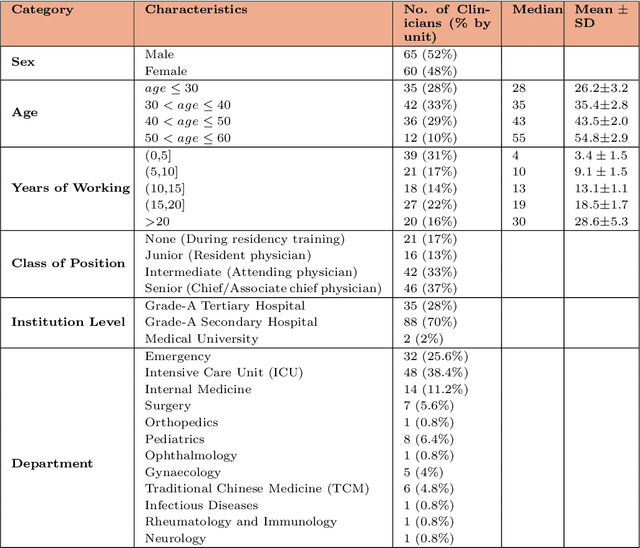
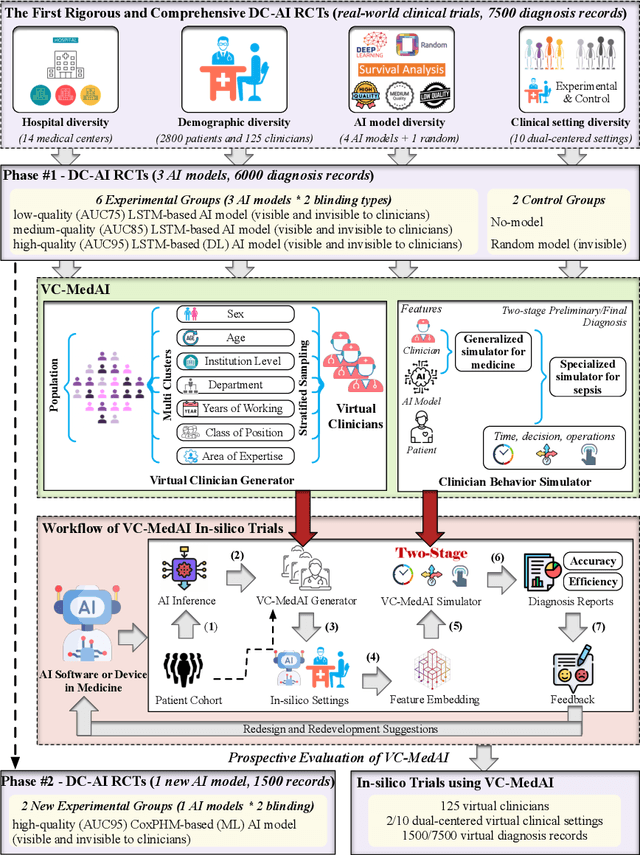
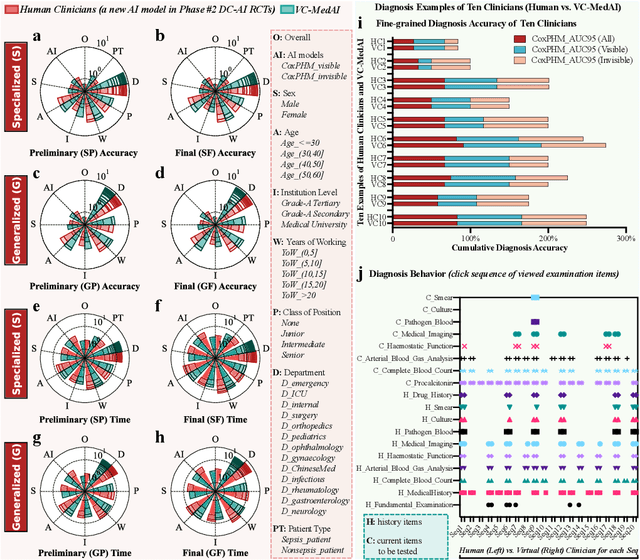
A profound gap persists between artificial intelligence (AI) and clinical practice in medicine, primarily due to the lack of rigorous and cost-effective evaluation methodologies. State-of-the-art and state-of-the-practice AI model evaluations are limited to laboratory studies on medical datasets or direct clinical trials with no or solely patient-centered controls. Moreover, the crucial role of clinicians in collaborating with AI, pivotal for determining its impact on clinical practice, is often overlooked. For the first time, we emphasize the critical necessity for rigorous and cost-effective evaluation methodologies for AI models in clinical practice, featuring patient/clinician-centered (dual-centered) AI randomized controlled trials (DC-AI RCTs) and virtual clinician-based in-silico trials (VC-MedAI) as an effective proxy for DC-AI RCTs. Leveraging 7500 diagnosis records from two-phase inaugural DC-AI RCTs across 14 medical centers with 125 clinicians, our results demonstrate the necessity of DC-AI RCTs and the effectiveness of VC-MedAI. Notably, VC-MedAI performs comparably to human clinicians, replicating insights and conclusions from prospective DC-AI RCTs. We envision DC-AI RCTs and VC-MedAI as pivotal advancements, presenting innovative and transformative evaluation methodologies for AI models in clinical practice, offering a preclinical-like setting mirroring conventional medicine, and reshaping development paradigms in a cost-effective and fast-iterative manner. Chinese Clinical Trial Registration: ChiCTR2400086816.
Heterogeneous Graph Collaborative Filtering using Textual Information
Oct 04, 2020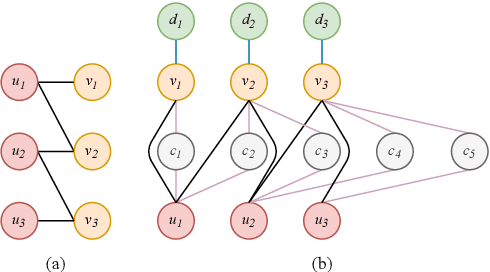
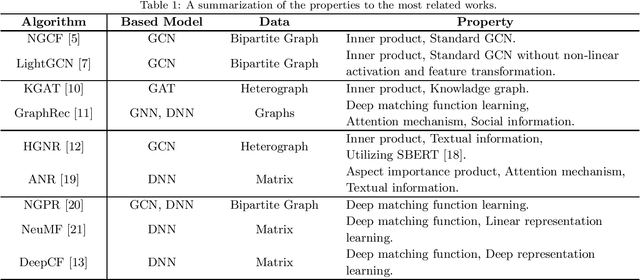
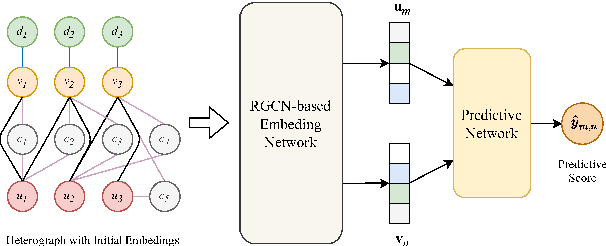

Due to the development of graph neural network models, like graph convolutional network (GCN), graph-based representation learning methods have made great progress in recommender systems. However, the data sparsity is still a challenging problem that graph-based methods are confronted with. Recent works try to solve this problem by utilizing the side information. In this paper, we introduce easily accessible textual information to alleviate the negative effects of data sparsity. Specifically, to incorporate with rich textual knowledge, we utilize a pre-trained context-awareness natural language processing model to initialize the embeddings of text nodes. By a GCN-based node information propagation on the constructed heterogeneous graph, the embeddings of users and items can finally be enriched by the textual knowledge. The matching function used by most graph-based representation learning methods is the inner product, this linear operation can not fit complex semantics well. We design a predictive network, which can combine the graph-based representation learning with the matching function learning, and demonstrate that this predictive architecture can gain significant improvements. Extensive experiments are conducted on three public datasets and the results verify the superior performance of our method over several baselines.
A Text-based Deep Reinforcement Learning Framework for Interactive Recommendation
Apr 14, 2020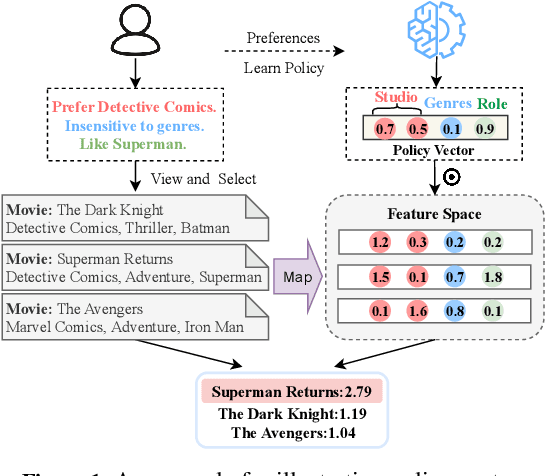
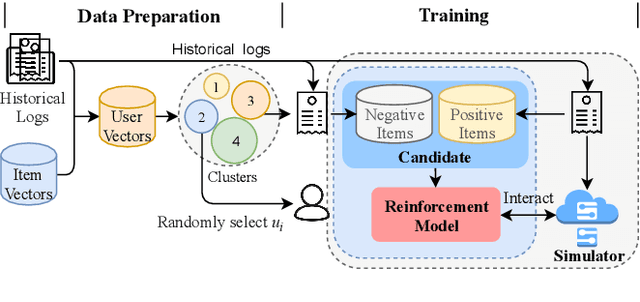

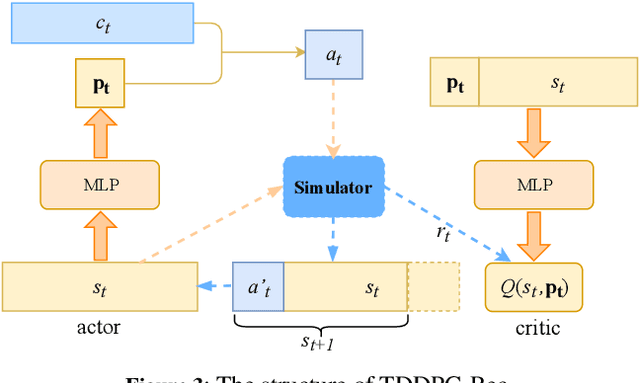
Due to its nature of learning from dynamic interactions and planning for long-run performance, reinforcement learning (RL) recently has received much attention in interactive recommender systems (IRSs). IRSs usually face the large discrete action space problem, which makes most of the existing RL-based recommendation methods inefficient. Moreover, data sparsity is another challenging problem that most IRSs are confronted with. While the textual information like reviews and descriptions is less sensitive to sparsity, existing RL-based recommendation methods either neglect or are not suitable for incorporating textual information. To address these two problems, in this paper, we propose a Text-based Deep Deterministic Policy Gradient framework (TDDPG-Rec) for IRSs. Specifically, we leverage textual information to map items and users into a feature space, which greatly alleviates the sparsity problem. Moreover, we design an effective method to construct an action candidate set. By the policy vector dynamically learned from TDDPG-Rec that expresses the user's preference, we can select actions from the candidate set effectively. Through experiments on three public datasets, we demonstrate that TDDPG-Rec achieves state-of-the-art performance over several baselines in a time-efficient manner.