 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQKVQA: Question-Focused Filtering for Knowledge-based VQA
Jan 21, 2026Knowledge-based Visual Question Answering (KB-VQA) aims to answer questions by integrating images with external knowledge. Effective knowledge filtering is crucial for improving accuracy. Typical filtering methods use similarity metrics to locate relevant article sections from one article, leading to information selection errors at the article and intra-article levels. Although recent explorations of Multimodal Large Language Model (MLLM)-based filtering methods demonstrate superior semantic understanding and cross-article filtering capabilities, their high computational cost limits practical application. To address these issues, this paper proposes a question-focused filtering method. This approach can perform question-focused, cross-article filtering, efficiently obtaining high-quality filtered knowledge while keeping computational costs comparable to typical methods. Specifically, we design a trainable Question-Focused Filter (QFF) and a Chunk-based Dynamic Multi-Article Selection (CDA) module, which collectively alleviate information selection errors at both the article and intra-article levels. Experiments show that our method outperforms current state-of-the-art models by 4.9% on E-VQA and 3.8% on InfoSeek, validating its effectiveness. The code is publicly available at: https://github.com/leaffeall/QKVQA.
I2E: From Image Pixels to Actionable Interactive Environments for Text-Guided Image Editing
Jan 07, 2026Existing text-guided image editing methods primarily rely on end-to-end pixel-level inpainting paradigm. Despite its success in simple scenarios, this paradigm still significantly struggles with compositional editing tasks that require precise local control and complex multi-object spatial reasoning. This paradigm is severely limited by 1) the implicit coupling of planning and execution, 2) the lack of object-level control granularity, and 3) the reliance on unstructured, pixel-centric modeling. To address these limitations, we propose I2E, a novel "Decompose-then-Action" paradigm that revisits image editing as an actionable interaction process within a structured environment. I2E utilizes a Decomposer to transform unstructured images into discrete, manipulable object layers and then introduces a physics-aware Vision-Language-Action Agent to parse complex instructions into a series of atomic actions via Chain-of-Thought reasoning. Further, we also construct I2E-Bench, a benchmark designed for multi-instance spatial reasoning and high-precision editing. Experimental results on I2E-Bench and multiple public benchmarks demonstrate that I2E significantly outperforms state-of-the-art methods in handling complex compositional instructions, maintaining physical plausibility, and ensuring multi-turn editing stability.
SCIR: A Self-Correcting Iterative Refinement Framework for Enhanced Information Extraction Based on Schema
Dec 13, 2025Although Large language Model (LLM)-powered information extraction (IE) systems have shown impressive capabilities, current fine-tuning paradigms face two major limitations: high training costs and difficulties in aligning with LLM preferences. To address these issues, we propose a novel universal IE paradigm, the Self-Correcting Iterative Refinement (SCIR) framework, along with a Multi-task Bilingual (Chinese-English) Self-Correcting (MBSC) dataset containing over 100,000 entries. The SCIR framework achieves plug-and-play compatibility with existing LLMs and IE systems through its Dual-Path Self-Correcting module and feedback-driven optimization, thereby significantly reducing training costs. Concurrently, the MBSC dataset tackles the challenge of preference alignment by indirectly distilling GPT-4's capabilities into IE result detection models. Experimental results demonstrate that SCIR outperforms state-of-the-art IE methods across three key tasks: named entity recognition, relation extraction, and event extraction, achieving a 5.27 percent average improvement in span-based Micro-F1 while reducing training costs by 87 percent compared to baseline approaches. These advancements not only enhance the flexibility and accuracy of IE systems but also pave the way for lightweight and efficient IE paradigms.
Flow Diverse and Efficient: Learning Momentum Flow Matching via Stochastic Velocity Field Sampling
Jun 10, 2025Recently, the rectified flow (RF) has emerged as the new state-of-the-art among flow-based diffusion models due to its high efficiency advantage in straight path sampling, especially with the amazing images generated by a series of RF models such as Flux 1.0 and SD 3.0. Although a straight-line connection between the noisy and natural data distributions is intuitive, fast, and easy to optimize, it still inevitably leads to: 1) Diversity concerns, which arise since straight-line paths only cover a fairly restricted sampling space. 2) Multi-scale noise modeling concerns, since the straight line flow only needs to optimize the constant velocity field $\bm v$ between the two distributions $\bm\pi_0$ and $\bm\pi_1$. In this work, we present Discretized-RF, a new family of rectified flow (also called momentum flow models since they refer to the previous velocity component and the random velocity component in each diffusion step), which discretizes the straight path into a series of variable velocity field sub-paths (namely ``momentum fields'') to expand the search space, especially when close to the distribution $p_\text{noise}$. Different from the previous case where noise is directly superimposed on $\bm x$, we introduce noise on the velocity $\bm v$ of the sub-path to change its direction in order to improve the diversity and multi-scale noise modeling abilities. Experimental results on several representative datasets demonstrate that learning momentum flow matching by sampling random velocity fields will produce trajectories that are both diverse and efficient, and can consistently generate high-quality and diverse results. Code is available at https://github.com/liuruixun/momentum-fm.
Context-Aware Autoregressive Models for Multi-Conditional Image Generation
May 18, 2025Autoregressive transformers have recently shown impressive image generation quality and efficiency on par with state-of-the-art diffusion models. Unlike diffusion architectures, autoregressive models can naturally incorporate arbitrary modalities into a single, unified token sequence--offering a concise solution for multi-conditional image generation tasks. In this work, we propose $\textbf{ContextAR}$, a flexible and effective framework for multi-conditional image generation. ContextAR embeds diverse conditions (e.g., canny edges, depth maps, poses) directly into the token sequence, preserving modality-specific semantics. To maintain spatial alignment while enhancing discrimination among different condition types, we introduce hybrid positional encodings that fuse Rotary Position Embedding with Learnable Positional Embedding. We design Conditional Context-aware Attention to reduces computational complexity while preserving effective intra-condition perception. Without any fine-tuning, ContextAR supports arbitrary combinations of conditions during inference time. Experimental results demonstrate the powerful controllability and versatility of our approach, and show that the competitive perpormance than diffusion-based multi-conditional control approaches the existing autoregressive baseline across diverse multi-condition driven scenarios. Project page: $\href{https://context-ar.github.io/}{https://context-ar.github.io/.}$
CMAL: A Novel Cross-Modal Associative Learning Framework for Vision-Language Pre-Training
Oct 16, 2024



With the flourishing of social media platforms, vision-language pre-training (VLP) recently has received great attention and many remarkable progresses have been achieved. The success of VLP largely benefits from the information complementation and enhancement between different modalities. However, most of recent studies focus on cross-modal contrastive learning (CMCL) to promote image-text alignment by pulling embeddings of positive sample pairs together while pushing those of negative pairs apart, which ignores the natural asymmetry property between different modalities and requires large-scale image-text corpus to achieve arduous progress. To mitigate this predicament, we propose CMAL, a Cross-Modal Associative Learning framework with anchor points detection and cross-modal associative learning for VLP. Specifically, we first respectively embed visual objects and textual tokens into separate hypersphere spaces to learn intra-modal hidden features, and then design a cross-modal associative prompt layer to perform anchor point masking and swap feature filling for constructing a hybrid cross-modal associative prompt. Afterwards, we exploit a unified semantic encoder to learn their cross-modal interactive features for context adaptation. Finally, we design an associative mapping classification layer to learn potential associative mappings between modalities at anchor points, within which we develop a fresh self-supervised associative mapping classification task to boost CMAL's performance. Experimental results verify the effectiveness of CMAL, showing that it achieves competitive performance against previous CMCL-based methods on four common downstream vision-and-language tasks, with significantly fewer corpus. Especially, CMAL obtains new state-of-the-art results on SNLI-VE and REC (testA).
Efficient Diffusion Models: A Comprehensive Survey from Principles to Practices
Oct 15, 2024



As one of the most popular and sought-after generative models in the recent years, diffusion models have sparked the interests of many researchers and steadily shown excellent advantage in various generative tasks such as image synthesis, video generation, molecule design, 3D scene rendering and multimodal generation, relying on their dense theoretical principles and reliable application practices. The remarkable success of these recent efforts on diffusion models comes largely from progressive design principles and efficient architecture, training, inference, and deployment methodologies. However, there has not been a comprehensive and in-depth review to summarize these principles and practices to help the rapid understanding and application of diffusion models. In this survey, we provide a new efficiency-oriented perspective on these existing efforts, which mainly focuses on the profound principles and efficient practices in architecture designs, model training, fast inference and reliable deployment, to guide further theoretical research, algorithm migration and model application for new scenarios in a reader-friendly way. \url{https://github.com/ponyzym/Efficient-DMs-Survey}
Oxygen vacancies modulated VO2 for neurons and Spiking Neural Network construction
Apr 16, 2024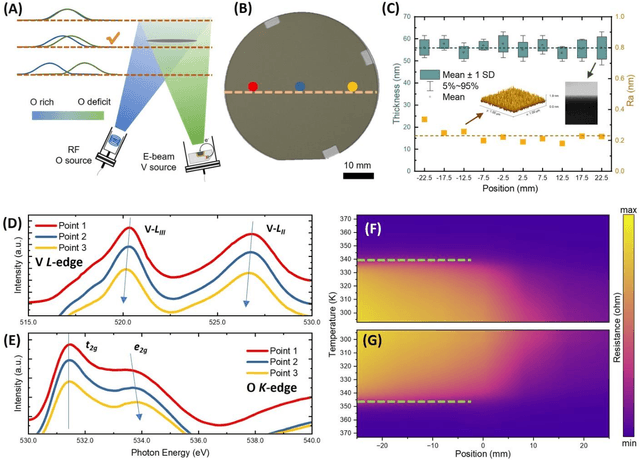
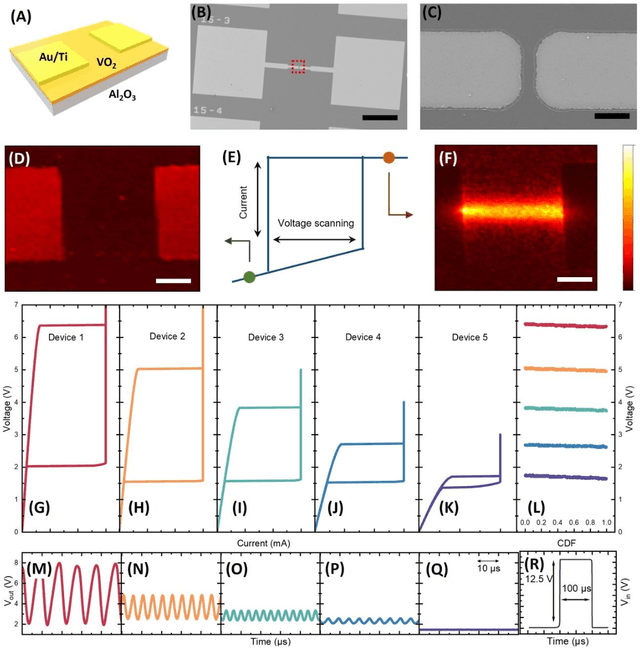
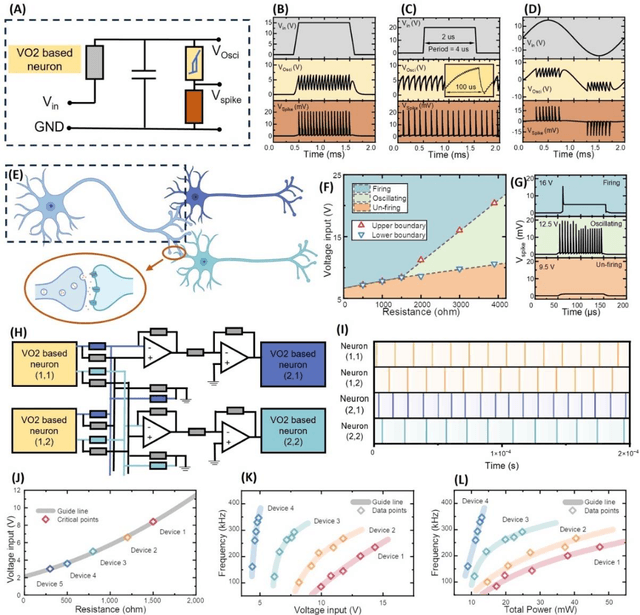
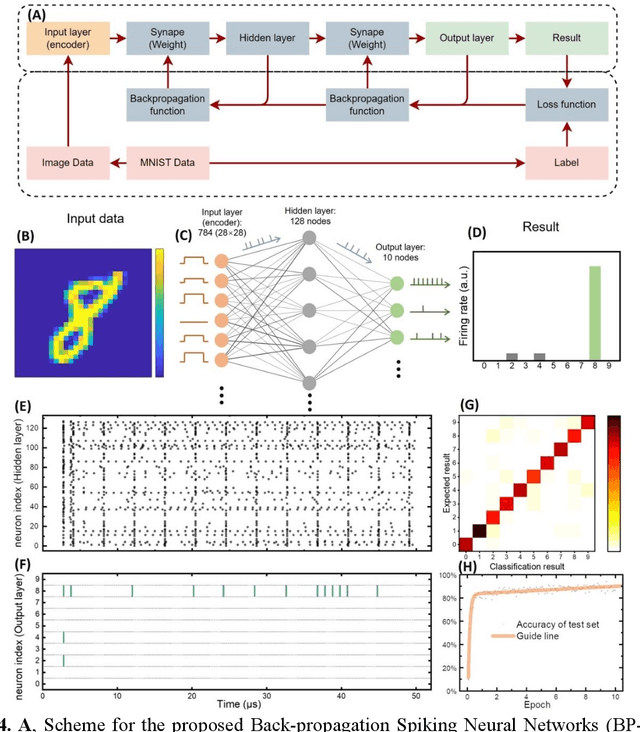
Artificial neuronal devices are the basic building blocks for neuromorphic computing systems, which have been motivated by realistic brain emulation. Aiming for these applications, various device concepts have been proposed to mimic the neuronal dynamics and functions. While till now, the artificial neuron devices with high efficiency, high stability and low power consumption are still far from practical application. Due to the special insulator-metal phase transition, Vanadium Dioxide (VO2) has been considered as an idea candidate for neuronal device fabrication. However, its intrinsic insulating state requires the VO2 neuronal device to be driven under large bias voltage, resulting in high power consumption and low frequency. Thus in the current study, we have addressed this challenge by preparing oxygen vacancies modulated VO2 film(VO2-x) and fabricating the VO2-x neuronal devices for Spiking Neural Networks (SNNs) construction. Results indicate the neuron devices can be operated under lower voltage with improved processing speed. The proposed VO2-x based back-propagation SNNs (BP-SNNs) system, trained with the MNIST dataset, demonstrates excellent accuracy in image recognition. Our study not only demonstrates the VO2-x based neurons and SNN system for practical application, but also offers an effective way to optimize the future neuromorphic computing systems by defect engineering strategy.
DualVAE: Dual Disentangled Variational AutoEncoder for Recommendation
Jan 10, 2024

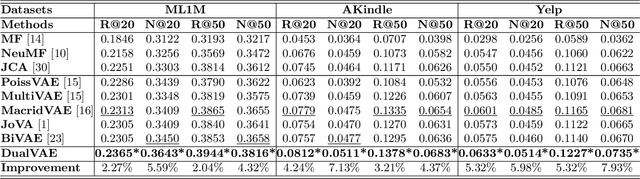
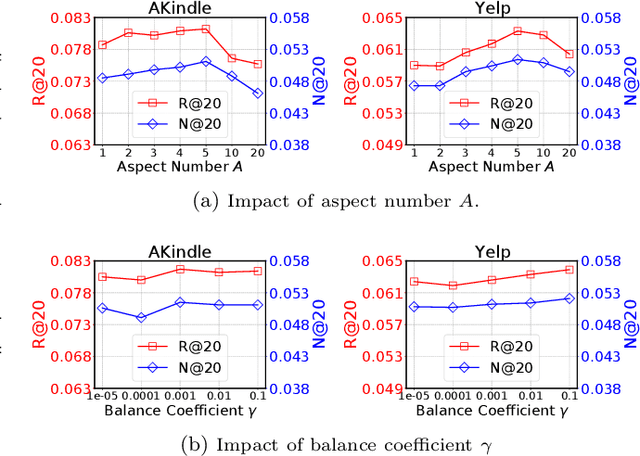
Learning precise representations of users and items to fit observed interaction data is the fundamental task of collaborative filtering. Existing studies usually infer entangled representations to fit such interaction data, neglecting to model the diverse matching relationships between users and items behind their interactions, leading to limited performance and weak interpretability. To address this problem, we propose a Dual Disentangled Variational AutoEncoder (DualVAE) for collaborative recommendation, which combines disentangled representation learning with variational inference to facilitate the generation of implicit interaction data. Specifically, we first implement the disentangling concept by unifying an attention-aware dual disentanglement and disentangled variational autoencoder to infer the disentangled latent representations of users and items. Further, to encourage the correspondence and independence of disentangled representations of users and items, we design a neighborhood-enhanced representation constraint with a customized contrastive mechanism to improve the representation quality. Extensive experiments on three real-world benchmarks show that our proposed model significantly outperforms several recent state-of-the-art baselines. Further empirical experimental results also illustrate the interpretability of the disentangled representations learned by DualVAE.
LGMRec: Local and Global Graph Learning for Multimodal Recommendation
Dec 27, 2023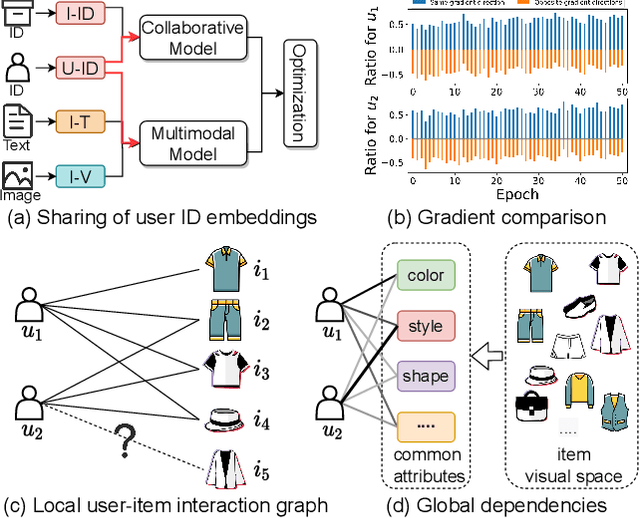
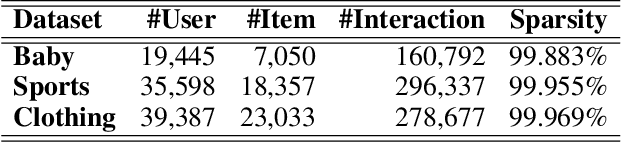
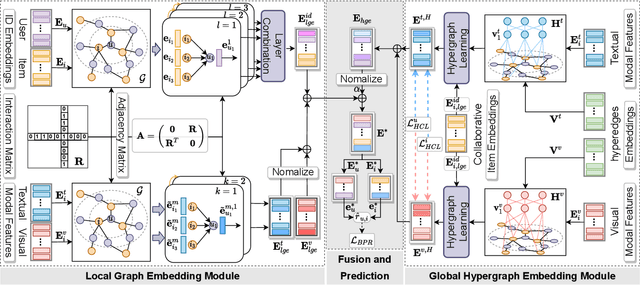
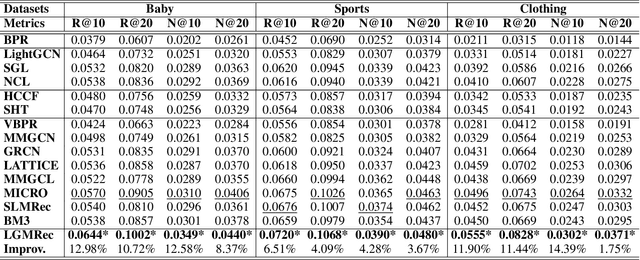
The multimodal recommendation has gradually become the infrastructure of online media platforms, enabling them to provide personalized service to users through a joint modeling of user historical behaviors (e.g., purchases, clicks) and item various modalities (e.g., visual and textual). The majority of existing studies typically focus on utilizing modal features or modal-related graph structure to learn user local interests. Nevertheless, these approaches encounter two limitations: (1) Shared updates of user ID embeddings result in the consequential coupling between collaboration and multimodal signals; (2) Lack of exploration into robust global user interests to alleviate the sparse interaction problems faced by local interest modeling. To address these issues, we propose a novel Local and Global Graph Learning-guided Multimodal Recommender (LGMRec), which jointly models local and global user interests. Specifically, we present a local graph embedding module to independently learn collaborative-related and modality-related embeddings of users and items with local topological relations. Moreover, a global hypergraph embedding module is designed to capture global user and item embeddings by modeling insightful global dependency relations. The global embeddings acquired within the hypergraph embedding space can then be combined with two decoupled local embeddings to improve the accuracy and robustness of recommendations. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our LGMRec over various state-of-the-art recommendation baselines, showcasing its effectiveness in modeling both local and global user interests.