 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMAL: A Novel Cross-Modal Associative Learning Framework for Vision-Language Pre-Training
Oct 16, 2024



With the flourishing of social media platforms, vision-language pre-training (VLP) recently has received great attention and many remarkable progresses have been achieved. The success of VLP largely benefits from the information complementation and enhancement between different modalities. However, most of recent studies focus on cross-modal contrastive learning (CMCL) to promote image-text alignment by pulling embeddings of positive sample pairs together while pushing those of negative pairs apart, which ignores the natural asymmetry property between different modalities and requires large-scale image-text corpus to achieve arduous progress. To mitigate this predicament, we propose CMAL, a Cross-Modal Associative Learning framework with anchor points detection and cross-modal associative learning for VLP. Specifically, we first respectively embed visual objects and textual tokens into separate hypersphere spaces to learn intra-modal hidden features, and then design a cross-modal associative prompt layer to perform anchor point masking and swap feature filling for constructing a hybrid cross-modal associative prompt. Afterwards, we exploit a unified semantic encoder to learn their cross-modal interactive features for context adaptation. Finally, we design an associative mapping classification layer to learn potential associative mappings between modalities at anchor points, within which we develop a fresh self-supervised associative mapping classification task to boost CMAL's performance. Experimental results verify the effectiveness of CMAL, showing that it achieves competitive performance against previous CMCL-based methods on four common downstream vision-and-language tasks, with significantly fewer corpus. Especially, CMAL obtains new state-of-the-art results on SNLI-VE and REC (testA).
EventLens: Leveraging Event-Aware Pretraining and Cross-modal Linking Enhances Visual Commonsense Reasoning
Apr 22, 2024



Visual Commonsense Reasoning (VCR) is a cognitive task, challenging models to answer visual questions requiring human commonsense, and to provide rationales explaining why the answers are correct. With emergence of Large Language Models (LLMs), it is natural and imperative to explore their applicability to VCR. However, VCR task demands more external knowledge to tackle its challenging questions, necessitating special designs to activate LLMs' commonsense reasoning abilities. Also, most existing Multimodal LLMs adopted an abstraction of entire input image, which makes it difficult to comprehend VCR's unique co-reference tags between image regions and text, posing challenges for fine-grained alignment. To address these issues, we propose EventLens that leverages Event-Aware Pretraining and Cross-modal Linking and EnhanceS VCR. First, by emulating the cognitive process of human reasoning, an Event-Aware Pretraining auxiliary task is introduced to better activate LLM's global comprehension of intricate scenarios. Second, during fine-tuning, we further utilize reference tags to bridge RoI features with texts, while preserving both modality semantics. Finally, we use instruct-style prompts to narrow the gap between pretraining and fine-tuning, and task-specific adapters to better integrate LLM's inherent knowledge with new commonsense. Experimental results show the effectiveness of our proposed auxiliary task and fine-grained linking strategy.
DualVAE: Dual Disentangled Variational AutoEncoder for Recommendation
Jan 10, 2024

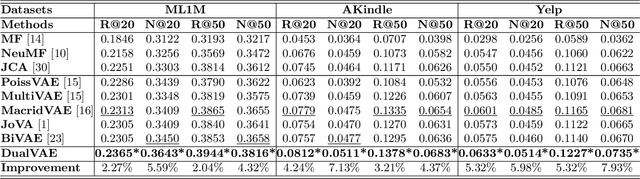
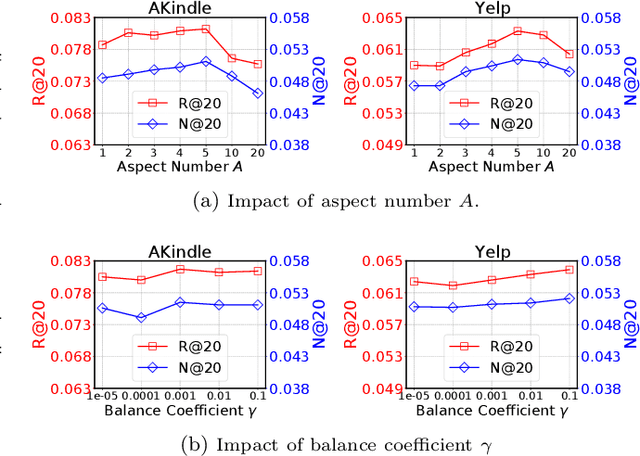
Learning precise representations of users and items to fit observed interaction data is the fundamental task of collaborative filtering. Existing studies usually infer entangled representations to fit such interaction data, neglecting to model the diverse matching relationships between users and items behind their interactions, leading to limited performance and weak interpretability. To address this problem, we propose a Dual Disentangled Variational AutoEncoder (DualVAE) for collaborative recommendation, which combines disentangled representation learning with variational inference to facilitate the generation of implicit interaction data. Specifically, we first implement the disentangling concept by unifying an attention-aware dual disentanglement and disentangled variational autoencoder to infer the disentangled latent representations of users and items. Further, to encourage the correspondence and independence of disentangled representations of users and items, we design a neighborhood-enhanced representation constraint with a customized contrastive mechanism to improve the representation quality. Extensive experiments on three real-world benchmarks show that our proposed model significantly outperforms several recent state-of-the-art baselines. Further empirical experimental results also illustrate the interpretability of the disentangled representations learned by DualVAE.
LGMRec: Local and Global Graph Learning for Multimodal Recommendation
Dec 27, 2023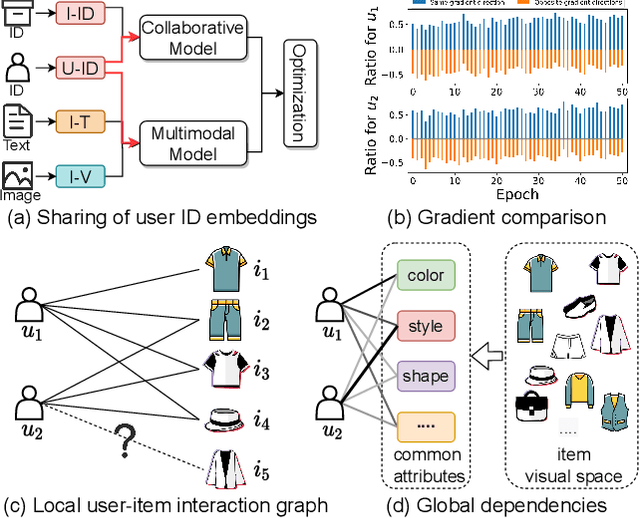
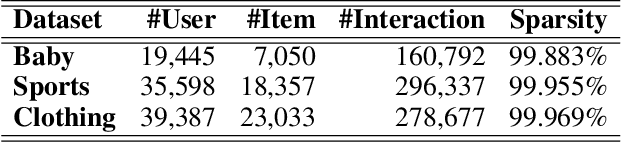
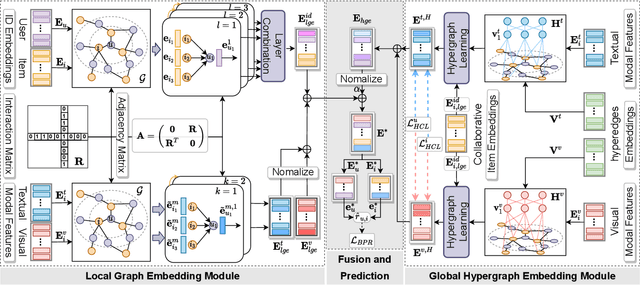
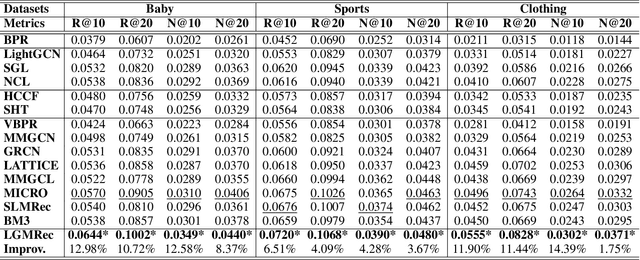
The multimodal recommendation has gradually become the infrastructure of online media platforms, enabling them to provide personalized service to users through a joint modeling of user historical behaviors (e.g., purchases, clicks) and item various modalities (e.g., visual and textual). The majority of existing studies typically focus on utilizing modal features or modal-related graph structure to learn user local interests. Nevertheless, these approaches encounter two limitations: (1) Shared updates of user ID embeddings result in the consequential coupling between collaboration and multimodal signals; (2) Lack of exploration into robust global user interests to alleviate the sparse interaction problems faced by local interest modeling. To address these issues, we propose a novel Local and Global Graph Learning-guided Multimodal Recommender (LGMRec), which jointly models local and global user interests. Specifically, we present a local graph embedding module to independently learn collaborative-related and modality-related embeddings of users and items with local topological relations. Moreover, a global hypergraph embedding module is designed to capture global user and item embeddings by modeling insightful global dependency relations. The global embeddings acquired within the hypergraph embedding space can then be combined with two decoupled local embeddings to improve the accuracy and robustness of recommendations. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our LGMRec over various state-of-the-art recommendation baselines, showcasing its effectiveness in modeling both local and global user interests.
Heterogeneous Graph Collaborative Filtering using Textual Information
Oct 04, 2020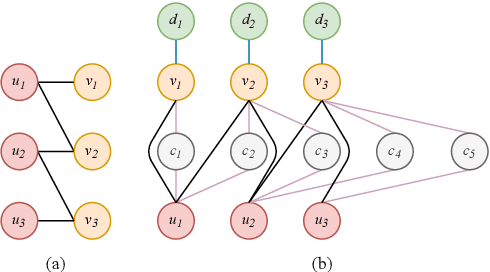
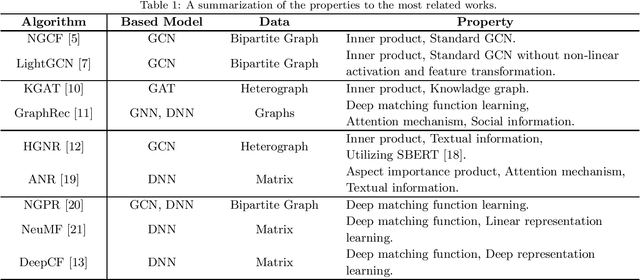
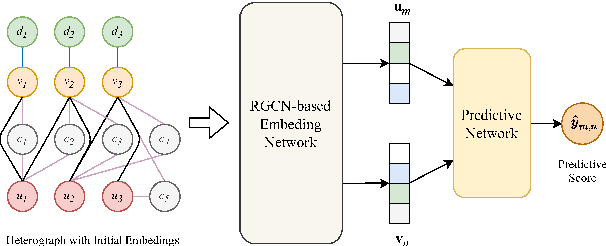

Due to the development of graph neural network models, like graph convolutional network (GCN), graph-based representation learning methods have made great progress in recommender systems. However, the data sparsity is still a challenging problem that graph-based methods are confronted with. Recent works try to solve this problem by utilizing the side information. In this paper, we introduce easily accessible textual information to alleviate the negative effects of data sparsity. Specifically, to incorporate with rich textual knowledge, we utilize a pre-trained context-awareness natural language processing model to initialize the embeddings of text nodes. By a GCN-based node information propagation on the constructed heterogeneous graph, the embeddings of users and items can finally be enriched by the textual knowledge. The matching function used by most graph-based representation learning methods is the inner product, this linear operation can not fit complex semantics well. We design a predictive network, which can combine the graph-based representation learning with the matching function learning, and demonstrate that this predictive architecture can gain significant improvements. Extensive experiments are conducted on three public datasets and the results verify the superior performance of our method over several baselines.
A Text-based Deep Reinforcement Learning Framework for Interactive Recommendation
Apr 14, 2020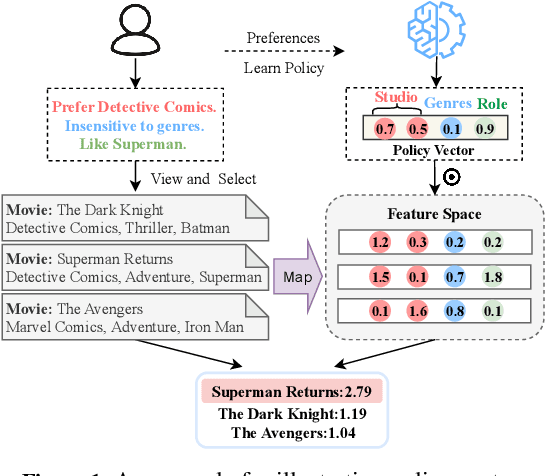
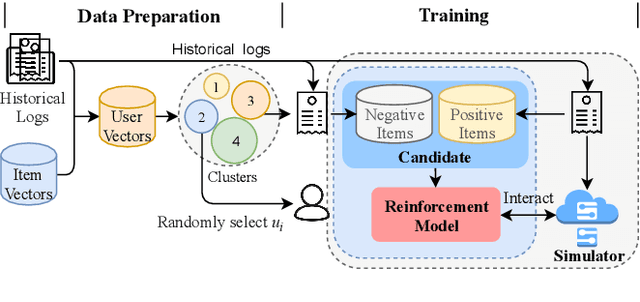

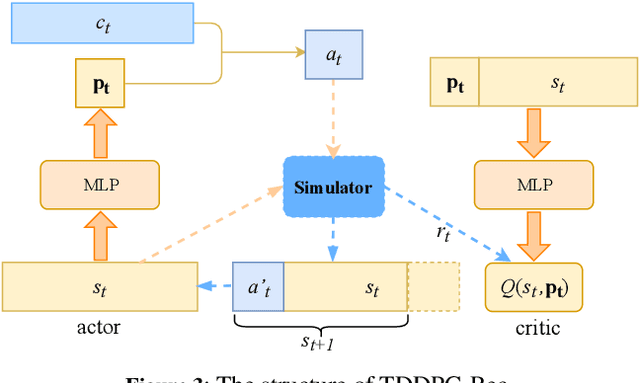
Due to its nature of learning from dynamic interactions and planning for long-run performance, reinforcement learning (RL) recently has received much attention in interactive recommender systems (IRSs). IRSs usually face the large discrete action space problem, which makes most of the existing RL-based recommendation methods inefficient. Moreover, data sparsity is another challenging problem that most IRSs are confronted with. While the textual information like reviews and descriptions is less sensitive to sparsity, existing RL-based recommendation methods either neglect or are not suitable for incorporating textual information. To address these two problems, in this paper, we propose a Text-based Deep Deterministic Policy Gradient framework (TDDPG-Rec) for IRSs. Specifically, we leverage textual information to map items and users into a feature space, which greatly alleviates the sparsity problem. Moreover, we design an effective method to construct an action candidate set. By the policy vector dynamically learned from TDDPG-Rec that expresses the user's preference, we can select actions from the candidate set effectively. Through experiments on three public datasets, we demonstrate that TDDPG-Rec achieves state-of-the-art performance over several baselines in a time-efficient manner.
Dust concentration vision measurement based on moment of inertia in gray level-rank co-occurrence matrix
May 10, 2018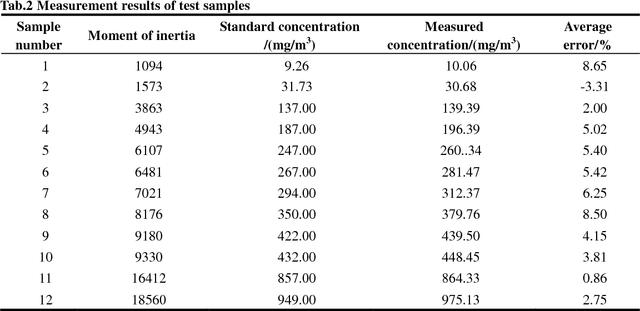
To improve the accuracy of existing dust concentration measurements, a dust concentration measurement based on Moment of inertia in Gray level-Rank Co-occurrence Matrix (GRCM), which is from the dust image sample measured by a machine vision system is proposed in this paper. Firstly, a Polynomial computational model between dust Concentration and Moment of inertia (PCM) is established by experimental methods and fitting methods. Then computing methods for GRCM and its Moment of inertia are constructed by theoretical and mathematical analysis methods. And then developing an on-line dust concentration vision measurement experimental system, the cement dust concentration measurement in a cement production workshop is taken as a practice example with the system and the PCM measurement. The results show that measurement error is within 9%, and the measurement range is 0.5-1000 mg/m3. Finally, comparing with the filter membrane weighing measurement, light scattering measurement and laser measurement, the proposed PCM measurement has advantages on error and cost, which can be provided a valuable reference for the dust concentration vision measurements.