 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful, Enriched, and Precise: Benchmarking Natural-Science Illustration Generation by T2I models
Jun 04, 2026Scientific illustrations are essential tools for communicating research findings, especially in natural science, where they visualize complex concepts and processes. As Text-to-Image (T2I) models become increasingly capable, researchers have started to use them for scientific illustration generation. However, existing benchmarks often assess outputs at a holistic level, overlooking fine-grained elements, while scientific reasoning ability and output conciseness remain under-quantified. We introduce FEPBench, a benchmark built from carefully selected high-quality scientific illustrations across multiple disciplines and layout types. With the assistance of multimodal large language models (MLLMs) and human experts, we provide fine-grained atom set annotations and systematically evaluate T2I models along three dimensions: instruction faithfulness, reasoning enrichment, and semantic precision. Our evaluation further decomposes model performance across visual, textual, relation, and layout elements. Results show that even state-of-the-art (SOTA) closed-source models, such as GPT Image 2 and Nano Banana Pro, still suffer from text-rendering bottlenecks, limited reasoning enrichment, and difficulty balancing generation richness with precision. These findings provide practical guidance for improving and deploying T2I models in scientific illustration generation. Benchmark data, atom set annotations, and evaluation code will be released by us.
Efficient Diffusion Models: A Comprehensive Survey from Principles to Practices
Oct 15, 2024



As one of the most popular and sought-after generative models in the recent years, diffusion models have sparked the interests of many researchers and steadily shown excellent advantage in various generative tasks such as image synthesis, video generation, molecule design, 3D scene rendering and multimodal generation, relying on their dense theoretical principles and reliable application practices. The remarkable success of these recent efforts on diffusion models comes largely from progressive design principles and efficient architecture, training, inference, and deployment methodologies. However, there has not been a comprehensive and in-depth review to summarize these principles and practices to help the rapid understanding and application of diffusion models. In this survey, we provide a new efficiency-oriented perspective on these existing efforts, which mainly focuses on the profound principles and efficient practices in architecture designs, model training, fast inference and reliable deployment, to guide further theoretical research, algorithm migration and model application for new scenarios in a reader-friendly way. \url{https://github.com/ponyzym/Efficient-DMs-Survey}
Neural Residual Diffusion Models for Deep Scalable Vision Generation
Jun 19, 2024



The most advanced diffusion models have recently adopted increasingly deep stacked networks (e.g., U-Net or Transformer) to promote the generative emergence capabilities of vision generation models similar to large language models (LLMs). However, progressively deeper stacked networks will intuitively cause numerical propagation errors and reduce noisy prediction capabilities on generative data, which hinders massively deep scalable training of vision generation models. In this paper, we first uncover the nature that neural networks being able to effectively perform generative denoising lies in the fact that the intrinsic residual unit has consistent dynamic property with the input signal's reverse diffusion process, thus supporting excellent generative abilities. Afterwards, we stand on the shoulders of two common types of deep stacked networks to propose a unified and massively scalable Neural Residual Diffusion Models framework (Neural-RDM for short), which is a simple yet meaningful change to the common architecture of deep generative networks by introducing a series of learnable gated residual parameters that conform to the generative dynamics. Experimental results on various generative tasks show that the proposed neural residual models obtain state-of-the-art scores on image's and video's generative benchmarks. Rigorous theoretical proofs and extensive experiments also demonstrate the advantages of this simple gated residual mechanism consistent with dynamic modeling in improving the fidelity and consistency of generated content and supporting large-scale scalable training. Code is available at https://github.com/Anonymous/Neural-RDM.
Transformer-Enhanced Motion Planner: Attention-Guided Sampling for State-Specific Decision Making
Apr 30, 2024


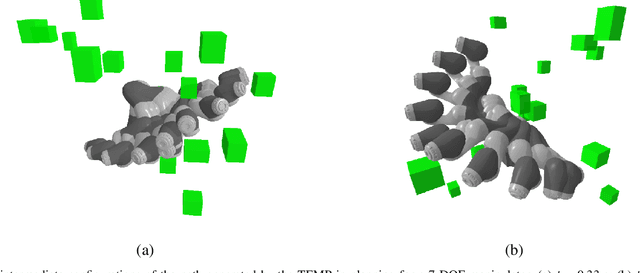
Sampling-based motion planning (SBMP) algorithms are renowned for their robust global search capabilities. However, the inherent randomness in their sampling mechanisms often result in inconsistent path quality and limited search efficiency. In response to these challenges, this work proposes a novel deep learning-based motion planning framework, named Transformer-Enhanced Motion Planner (TEMP), which synergizes an Environmental Information Semantic Encoder (EISE) with a Motion Planning Transformer (MPT). EISE converts environmental data into semantic environmental information (SEI), providing MPT with an enriched environmental comprehension. MPT leverages an attention mechanism to dynamically recalibrate its focus on SEI, task objectives, and historical planning data, refining the sampling node generation. To demonstrate the capabilities of TEMP, we train our model using a dataset comprised of planning results produced by the RRT*. EISE and MPT are collaboratively trained, enabling EISE to autonomously learn and extract patterns from environmental data, thereby forming semantic representations that MPT could more effectively interpret and utilize for motion planning. Subsequently, we conducted a systematic evaluation of TEMP's efficacy across diverse task dimensions, which demonstrates that TEMP achieves exceptional performance metrics and a heightened degree of generalizability compared to state-of-the-art SBMPs.
NWPU-MOC: A Benchmark for Fine-grained Multi-category Object Counting in Aerial Images
Jan 19, 2024Object counting is a hot topic in computer vision, which aims to estimate the number of objects in a given image. However, most methods only count objects of a single category for an image, which cannot be applied to scenes that need to count objects with multiple categories simultaneously, especially in aerial scenes. To this end, this paper introduces a Multi-category Object Counting (MOC) task to estimate the numbers of different objects (cars, buildings, ships, etc.) in an aerial image. Considering the absence of a dataset for this task, a large-scale Dataset (NWPU-MOC) is collected, consisting of 3,416 scenes with a resolution of 1024 $\times$ 1024 pixels, and well-annotated using 14 fine-grained object categories. Besides, each scene contains RGB and Near Infrared (NIR) images, of which the NIR spectrum can provide richer characterization information compared with only the RGB spectrum. Based on NWPU-MOC, the paper presents a multi-spectrum, multi-category object counting framework, which employs a dual-attention module to fuse the features of RGB and NIR and subsequently regress multi-channel density maps corresponding to each object category. In addition, to modeling the dependency between different channels in the density map with each object category, a spatial contrast loss is designed as a penalty for overlapping predictions at the same spatial position. Experimental results demonstrate that the proposed method achieves state-of-the-art performance compared with some mainstream counting algorithms. The dataset, code and models are publicly available at https://github.com/lyongo/NWPU-MOC.
Collision-Free Kinematics for Redundant Manipulators in Dynamic Scenes using Optimal Reciprocal Velocity Obstacles
Mar 09, 2019
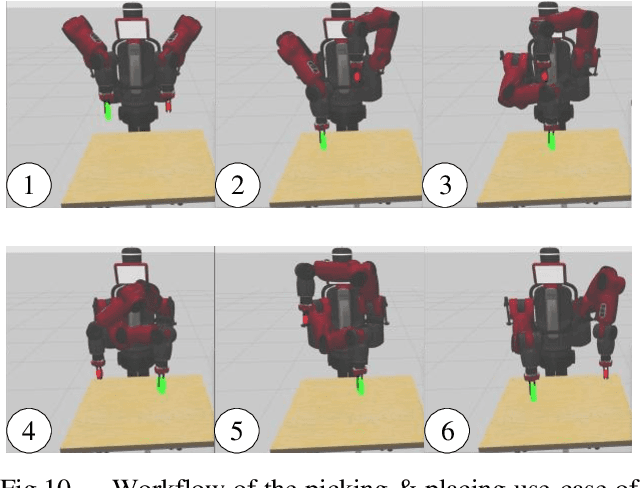
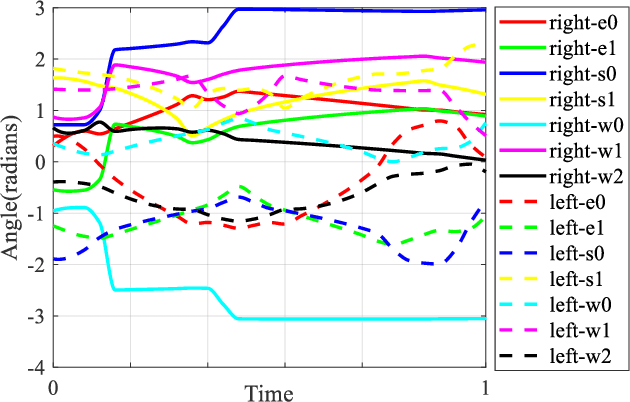
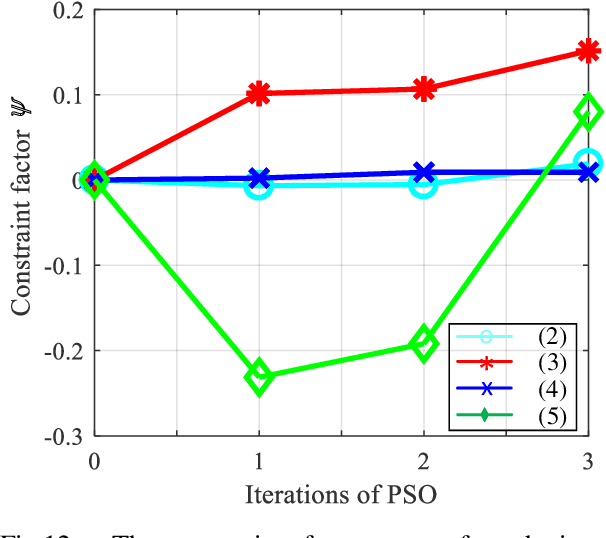
We present a novel algorithm for collision-free kinematics of multiple manipulators in a shared workspace with moving obstacles. Our optimization-based approach simultaneously handles collision-free constraints based on reciprocal velocity obstacles and inverse kinematics constraints for high-DOF manipulators. We present an efficient method based on particle swarm optimization that can generate collision-free configurations for each redundant manipulator. Furthermore, our approach can be used to compute safe and oscillation-free trajectories in a few milli-seconds. We highlight the real-time performance of our algorithm on multiple Baxter robots with 14-DOF manipulators operating in a workspace with dynamic obstacles. Videos are available at https://sites.google.com/view/collision-free-kinematics