 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskOpt: A Large-Scale Mask Optimization Dataset to Advance AI in Integrated Circuit Manufacturing
Dec 18, 2025As integrated circuit (IC) dimensions shrink below the lithographic wavelength, optical lithography faces growing challenges from diffraction and process variability. Model-based optical proximity correction (OPC) and inverse lithography technique (ILT) remain indispensable but computationally expensive, requiring repeated simulations that limit scalability. Although deep learning has been applied to mask optimization, existing datasets often rely on synthetic layouts, disregard standard-cell hierarchy, and neglect the surrounding contexts around the mask optimization targets, thereby constraining their applicability to practical mask optimization. To advance deep learning for cell- and context-aware mask optimization, we present MaskOpt, a large-scale benchmark dataset constructed from real IC designs at the 45$\mathrm{nm}$ node. MaskOpt includes 104,714 metal-layer tiles and 121,952 via-layer tiles. Each tile is clipped at a standard-cell placement to preserve cell information, exploiting repeated logic gate occurrences. Different context window sizes are supported in MaskOpt to capture the influence of neighboring shapes from optical proximity effects. We evaluate state-of-the-art deep learning models for IC mask optimization to build up benchmarks, and the evaluation results expose distinct trade-offs across baseline models. Further context size analysis and input ablation studies confirm the importance of both surrounding geometries and cell-aware inputs in achieving accurate mask generation.
Accelerating Visual Reinforcement Learning with Separate Primitive Policy for Peg-in-Hole Tasks
Apr 21, 2025For peg-in-hole tasks, humans rely on binocular visual perception to locate the peg above the hole surface and then proceed with insertion. This paper draws insights from this behavior to enable agents to learn efficient assembly strategies through visual reinforcement learning. Hence, we propose a Separate Primitive Policy (S2P) to simultaneously learn how to derive location and insertion actions. S2P is compatible with model-free reinforcement learning algorithms. Ten insertion tasks featuring different polygons are developed as benchmarks for evaluations. Simulation experiments show that S2P can boost the sample efficiency and success rate even with force constraints. Real-world experiments are also performed to verify the feasibility of S2P. Ablations are finally given to discuss the generalizability of S2P and some factors that affect its performance.
Transformer-Enhanced Motion Planner: Attention-Guided Sampling for State-Specific Decision Making
Apr 30, 2024


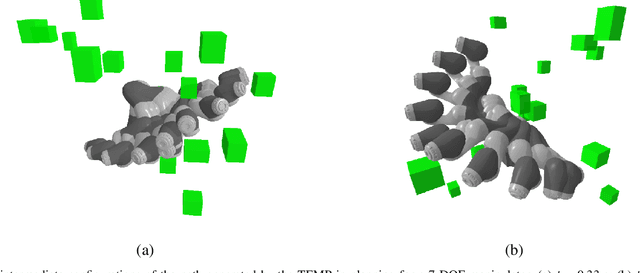
Sampling-based motion planning (SBMP) algorithms are renowned for their robust global search capabilities. However, the inherent randomness in their sampling mechanisms often result in inconsistent path quality and limited search efficiency. In response to these challenges, this work proposes a novel deep learning-based motion planning framework, named Transformer-Enhanced Motion Planner (TEMP), which synergizes an Environmental Information Semantic Encoder (EISE) with a Motion Planning Transformer (MPT). EISE converts environmental data into semantic environmental information (SEI), providing MPT with an enriched environmental comprehension. MPT leverages an attention mechanism to dynamically recalibrate its focus on SEI, task objectives, and historical planning data, refining the sampling node generation. To demonstrate the capabilities of TEMP, we train our model using a dataset comprised of planning results produced by the RRT*. EISE and MPT are collaboratively trained, enabling EISE to autonomously learn and extract patterns from environmental data, thereby forming semantic representations that MPT could more effectively interpret and utilize for motion planning. Subsequently, we conducted a systematic evaluation of TEMP's efficacy across diverse task dimensions, which demonstrates that TEMP achieves exceptional performance metrics and a heightened degree of generalizability compared to state-of-the-art SBMPs.
Open-Source Reinforcement Learning Environments Implemented in MuJoCo with Franka Manipulator
Jan 11, 2024
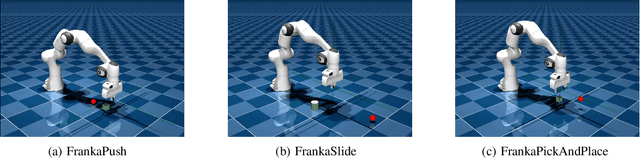
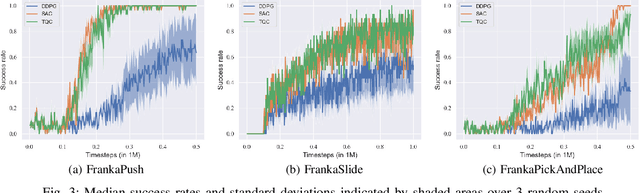
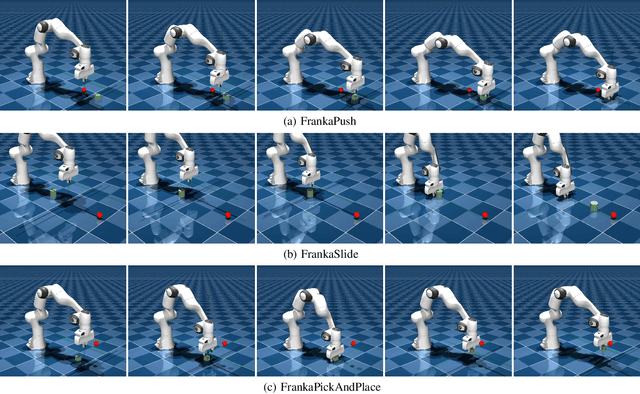
This paper presents three open-source reinforcement learning environments developed on the MuJoCo physics engine with the Franka Emika Panda arm in MuJoCo Menagerie. Three representative tasks, push, slide, and pick-and-place, are implemented through the Gymnasium Robotics API, which inherits from the core of Gymnasium. Both the sparse binary and dense rewards are supported, and the observation space contains the keys of desired and achieved goals to follow the Multi-Goal Reinforcement Learning framework. Three different off-policy algorithms are used to validate the simulation attributes to ensure the fidelity of all tasks, and benchmark results are also given. Each environment and task are defined in a clean way, and the main parameters for modifying the environment are preserved to reflect the main difference. The repository, including all environments, is available at https://github.com/zichunxx/panda_mujoco_gym.