 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2E: From Image Pixels to Actionable Interactive Environments for Text-Guided Image Editing
Jan 07, 2026Existing text-guided image editing methods primarily rely on end-to-end pixel-level inpainting paradigm. Despite its success in simple scenarios, this paradigm still significantly struggles with compositional editing tasks that require precise local control and complex multi-object spatial reasoning. This paradigm is severely limited by 1) the implicit coupling of planning and execution, 2) the lack of object-level control granularity, and 3) the reliance on unstructured, pixel-centric modeling. To address these limitations, we propose I2E, a novel "Decompose-then-Action" paradigm that revisits image editing as an actionable interaction process within a structured environment. I2E utilizes a Decomposer to transform unstructured images into discrete, manipulable object layers and then introduces a physics-aware Vision-Language-Action Agent to parse complex instructions into a series of atomic actions via Chain-of-Thought reasoning. Further, we also construct I2E-Bench, a benchmark designed for multi-instance spatial reasoning and high-precision editing. Experimental results on I2E-Bench and multiple public benchmarks demonstrate that I2E significantly outperforms state-of-the-art methods in handling complex compositional instructions, maintaining physical plausibility, and ensuring multi-turn editing stability.
Emotion-Director: Bridging Affective Shortcut in Emotion-Oriented Image Generation
Dec 22, 2025Image generation based on diffusion models has demonstrated impressive capability, motivating exploration into diverse and specialized applications. Owing to the importance of emotion in advertising, emotion-oriented image generation has attracted increasing attention. However, current emotion-oriented methods suffer from an affective shortcut, where emotions are approximated to semantics. As evidenced by two decades of research, emotion is not equivalent to semantics. To this end, we propose Emotion-Director, a cross-modal collaboration framework consisting of two modules. First, we propose a cross-Modal Collaborative diffusion model, abbreviated as MC-Diffusion. MC-Diffusion integrates visual prompts with textual prompts for guidance, enabling the generation of emotion-oriented images beyond semantics. Further, we improve the DPO optimization by a negative visual prompt, enhancing the model's sensitivity to different emotions under the same semantics. Second, we propose MC-Agent, a cross-Modal Collaborative Agent system that rewrites textual prompts to express the intended emotions. To avoid template-like rewrites, MC-Agent employs multi-agents to simulate human subjectivity toward emotions, and adopts a chain-of-concept workflow that improves the visual expressiveness of the rewritten prompts. Extensive qualitative and quantitative experiments demonstrate the superiority of Emotion-Director in emotion-oriented image generation.
AdsQA: Towards Advertisement Video Understanding
Sep 10, 2025Large language models (LLMs) have taken a great step towards AGI. Meanwhile, an increasing number of domain-specific problems such as math and programming boost these general-purpose models to continuously evolve via learning deeper expertise. Now is thus the time further to extend the diversity of specialized applications for knowledgeable LLMs, though collecting high quality data with unexpected and informative tasks is challenging. In this paper, we propose to use advertisement (ad) videos as a challenging test-bed to probe the ability of LLMs in perceiving beyond the objective physical content of common visual domain. Our motivation is to take full advantage of the clue-rich and information-dense ad videos' traits, e.g., marketing logic, persuasive strategies, and audience engagement. Our contribution is three-fold: (1) To our knowledge, this is the first attempt to use ad videos with well-designed tasks to evaluate LLMs. We contribute AdsQA, a challenging ad Video QA benchmark derived from 1,544 ad videos with 10,962 clips, totaling 22.7 hours, providing 5 challenging tasks. (2) We propose ReAd-R, a Deepseek-R1 styled RL model that reflects on questions, and generates answers via reward-driven optimization. (3) We benchmark 14 top-tier LLMs on AdsQA, and our \texttt{ReAd-R}~achieves the state-of-the-art outperforming strong competitors equipped with long-chain reasoning capabilities by a clear margin.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Context-Aware Autoregressive Models for Multi-Conditional Image Generation
May 18, 2025Autoregressive transformers have recently shown impressive image generation quality and efficiency on par with state-of-the-art diffusion models. Unlike diffusion architectures, autoregressive models can naturally incorporate arbitrary modalities into a single, unified token sequence--offering a concise solution for multi-conditional image generation tasks. In this work, we propose $\textbf{ContextAR}$, a flexible and effective framework for multi-conditional image generation. ContextAR embeds diverse conditions (e.g., canny edges, depth maps, poses) directly into the token sequence, preserving modality-specific semantics. To maintain spatial alignment while enhancing discrimination among different condition types, we introduce hybrid positional encodings that fuse Rotary Position Embedding with Learnable Positional Embedding. We design Conditional Context-aware Attention to reduces computational complexity while preserving effective intra-condition perception. Without any fine-tuning, ContextAR supports arbitrary combinations of conditions during inference time. Experimental results demonstrate the powerful controllability and versatility of our approach, and show that the competitive perpormance than diffusion-based multi-conditional control approaches the existing autoregressive baseline across diverse multi-condition driven scenarios. Project page: $\href{https://context-ar.github.io/}{https://context-ar.github.io/.}$
Efficient Diffusion Models: A Comprehensive Survey from Principles to Practices
Oct 15, 2024



As one of the most popular and sought-after generative models in the recent years, diffusion models have sparked the interests of many researchers and steadily shown excellent advantage in various generative tasks such as image synthesis, video generation, molecule design, 3D scene rendering and multimodal generation, relying on their dense theoretical principles and reliable application practices. The remarkable success of these recent efforts on diffusion models comes largely from progressive design principles and efficient architecture, training, inference, and deployment methodologies. However, there has not been a comprehensive and in-depth review to summarize these principles and practices to help the rapid understanding and application of diffusion models. In this survey, we provide a new efficiency-oriented perspective on these existing efforts, which mainly focuses on the profound principles and efficient practices in architecture designs, model training, fast inference and reliable deployment, to guide further theoretical research, algorithm migration and model application for new scenarios in a reader-friendly way. \url{https://github.com/ponyzym/Efficient-DMs-Survey}
Safe-SD: Safe and Traceable Stable Diffusion with Text Prompt Trigger for Invisible Generative Watermarking
Jul 19, 2024Recently, stable diffusion (SD) models have typically flourished in the field of image synthesis and personalized editing, with a range of photorealistic and unprecedented images being successfully generated. As a result, widespread interest has been ignited to develop and use various SD-based tools for visual content creation. However, the exposure of AI-created content on public platforms could raise both legal and ethical risks. In this regard, the traditional methods of adding watermarks to the already generated images (i.e. post-processing) may face a dilemma (e.g., being erased or modified) in terms of copyright protection and content monitoring, since the powerful image inversion and text-to-image editing techniques have been widely explored in SD-based methods. In this work, we propose a Safe and high-traceable Stable Diffusion framework (namely Safe-SD) to adaptively implant the graphical watermarks (e.g., QR code) into the imperceptible structure-related pixels during the generative diffusion process for supporting text-driven invisible watermarking and detection. Different from the previous high-cost injection-then-detection training framework, we design a simple and unified architecture, which makes it possible to simultaneously train watermark injection and detection in a single network, greatly improving the efficiency and convenience of use. Moreover, to further support text-driven generative watermarking and deeply explore its robustness and high-traceability, we elaborately design lambda sampling and encryption algorithm to fine-tune a latent diffuser wrapped by a VAE for balancing high-fidelity image synthesis and high-traceable watermark detection. We present our quantitative and qualitative results on two representative datasets LSUN, COCO and FFHQ, demonstrating state-of-the-art performance of Safe-SD and showing it significantly outperforms the previous approaches.
LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion
Apr 07, 2024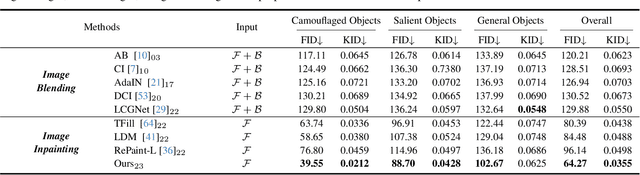
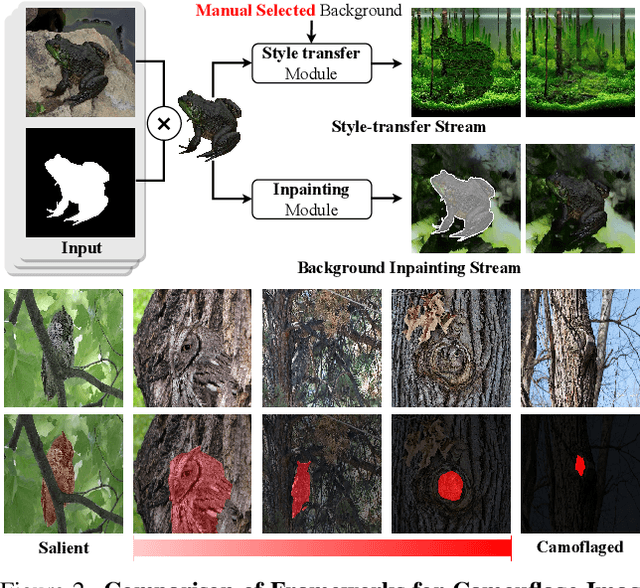
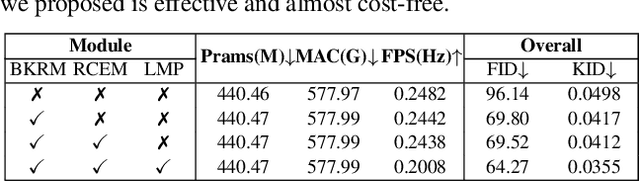
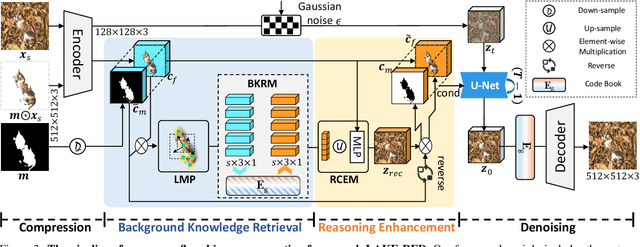
Camouflaged vision perception is an important vision task with numerous practical applications. Due to the expensive collection and labeling costs, this community struggles with a major bottleneck that the species category of its datasets is limited to a small number of object species. However, the existing camouflaged generation methods require specifying the background manually, thus failing to extend the camouflaged sample diversity in a low-cost manner. In this paper, we propose a Latent Background Knowledge Retrieval-Augmented Diffusion (LAKE-RED) for camouflaged image generation. To our knowledge, our contributions mainly include: (1) For the first time, we propose a camouflaged generation paradigm that does not need to receive any background inputs. (2) Our LAKE-RED is the first knowledge retrieval-augmented method with interpretability for camouflaged generation, in which we propose an idea that knowledge retrieval and reasoning enhancement are separated explicitly, to alleviate the task-specific challenges. Moreover, our method is not restricted to specific foreground targets or backgrounds, offering a potential for extending camouflaged vision perception to more diverse domains. (3) Experimental results demonstrate that our method outperforms the existing approaches, generating more realistic camouflage images.
AdapEdit: Spatio-Temporal Guided Adaptive Editing Algorithm for Text-Based Continuity-Sensitive Image Editing
Dec 24, 2023With the great success of text-conditioned diffusion models in creative text-to-image generation, various text-driven image editing approaches have attracted the attentions of many researchers. However, previous works mainly focus on discreteness-sensitive instructions such as adding, removing or replacing specific objects, background elements or global styles (i.e., hard editing), while generally ignoring subject-binding but semantically fine-changing continuity-sensitive instructions such as actions, poses or adjectives, and so on (i.e., soft editing), which hampers generative AI from generating user-customized visual contents. To mitigate this predicament, we propose a spatio-temporal guided adaptive editing algorithm AdapEdit, which realizes adaptive image editing by introducing a soft-attention strategy to dynamically vary the guiding degree from the editing conditions to visual pixels from both temporal and spatial perspectives. Note our approach has a significant advantage in preserving model priors and does not require model training, fine-tuning, extra data, or optimization. We present our results over a wide variety of raw images and editing instructions, demonstrating competitive performance and showing it significantly outperforms the previous approaches.
Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies
Aug 18, 2021
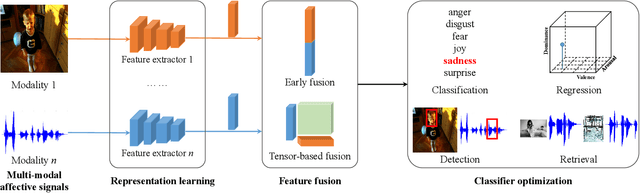
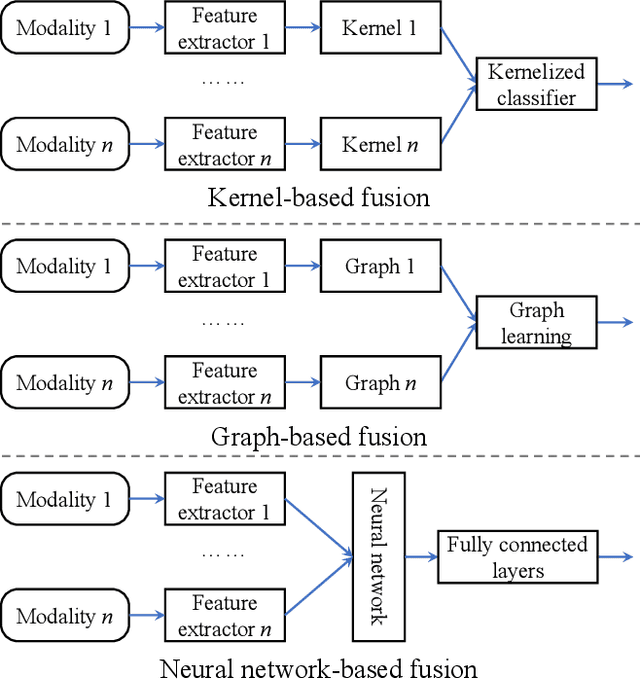
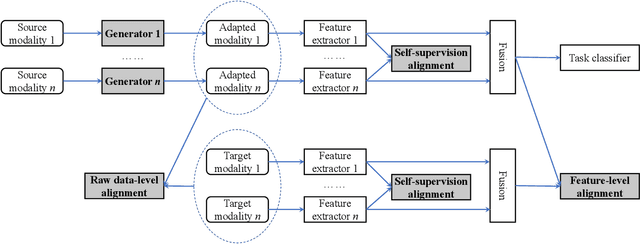
Humans are emotional creatures. Multiple modalities are often involved when we express emotions, whether we do so explicitly (e.g., facial expression, speech) or implicitly (e.g., text, image). Enabling machines to have emotional intelligence, i.e., recognizing, interpreting, processing, and simulating emotions, is becoming increasingly important. In this tutorial, we discuss several key aspects of multi-modal emotion recognition (MER). We begin with a brief introduction on widely used emotion representation models and affective modalities. We then summarize existing emotion annotation strategies and corresponding computational tasks, followed by the description of main challenges in MER. Furthermore, we present some representative approaches on representation learning of each affective modality, feature fusion of different affective modalities, classifier optimization for MER, and domain adaptation for MER. Finally, we outline several real-world applications and discuss some future directions.