 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1%>100%: High-Efficiency Visual Adapter with Complex Linear Projection Optimization
Feb 11, 2026Deploying vision foundation models typically relies on efficient adaptation strategies, whereas conventional full fine-tuning suffers from prohibitive costs and low efficiency. While delta-tuning has proven effective in boosting the performance and efficiency of LLMs during adaptation, its advantages cannot be directly transferred to the fine-tuning pipeline of vision foundation models. To push the boundaries of adaptation efficiency for vision tasks, we propose an adapter with Complex Linear Projection Optimization (CoLin). For architecture, we design a novel low-rank complex adapter that introduces only about 1% parameters to the backbone. For efficiency, we theoretically prove that low-rank composite matrices suffer from severe convergence issues during training, and address this challenge with a tailored loss. Extensive experiments on object detection, segmentation, image classification, and rotated object detection (remote sensing scenario) demonstrate that CoLin outperforms both full fine-tuning and classical delta-tuning approaches with merely 1% parameters for the first time, providing a novel and efficient solution for deployment of vision foundation models. We release the code on https://github.com/DongshuoYin/CoLin.
Reversible Unfolding Network for Concealed Visual Perception with Generative Refinement
Aug 20, 2025Existing methods for concealed visual perception (CVP) often leverage reversible strategies to decrease uncertainty, yet these are typically confined to the mask domain, leaving the potential of the RGB domain underexplored. To address this, we propose a reversible unfolding network with generative refinement, termed RUN++. Specifically, RUN++ first formulates the CVP task as a mathematical optimization problem and unfolds the iterative solution into a multi-stage deep network. This approach provides a principled way to apply reversible modeling across both mask and RGB domains while leveraging a diffusion model to resolve the resulting uncertainty. Each stage of the network integrates three purpose-driven modules: a Concealed Object Region Extraction (CORE) module applies reversible modeling to the mask domain to identify core object regions; a Context-Aware Region Enhancement (CARE) module extends this principle to the RGB domain to foster better foreground-background separation; and a Finetuning Iteration via Noise-based Enhancement (FINE) module provides a final refinement. The FINE module introduces a targeted Bernoulli diffusion model that refines only the uncertain regions of the segmentation mask, harnessing the generative power of diffusion for fine-detail restoration without the prohibitive computational cost of a full-image process. This unique synergy, where the unfolding network provides a strong uncertainty prior for the diffusion model, allows RUN++ to efficiently direct its focus toward ambiguous areas, significantly mitigating false positives and negatives. Furthermore, we introduce a new paradigm for building robust CVP systems that remain effective under real-world degradations and extend this concept into a broader bi-level optimization framework.
AngleRoCL: Angle-Robust Concept Learning for Physically View-Invariant T2I Adversarial Patches
Jun 11, 2025Cutting-edge works have demonstrated that text-to-image (T2I) diffusion models can generate adversarial patches that mislead state-of-the-art object detectors in the physical world, revealing detectors' vulnerabilities and risks. However, these methods neglect the T2I patches' attack effectiveness when observed from different views in the physical world (i.e., angle robustness of the T2I adversarial patches). In this paper, we study the angle robustness of T2I adversarial patches comprehensively, revealing their angle-robust issues, demonstrating that texts affect the angle robustness of generated patches significantly, and task-specific linguistic instructions fail to enhance the angle robustness. Motivated by the studies, we introduce Angle-Robust Concept Learning (AngleRoCL), a simple and flexible approach that learns a generalizable concept (i.e., text embeddings in implementation) representing the capability of generating angle-robust patches. The learned concept can be incorporated into textual prompts and guides T2I models to generate patches with their attack effectiveness inherently resistant to viewpoint variations. Through extensive simulation and physical-world experiments on five SOTA detectors across multiple views, we demonstrate that AngleRoCL significantly enhances the angle robustness of T2I adversarial patches compared to baseline methods. Our patches maintain high attack success rates even under challenging viewing conditions, with over 50% average relative improvement in attack effectiveness across multiple angles. This research advances the understanding of physically angle-robust patches and provides insights into the relationship between textual concepts and physical properties in T2I-generated contents.
PraNet-V2: Dual-Supervised Reverse Attention for Medical Image Segmentation
Apr 15, 2025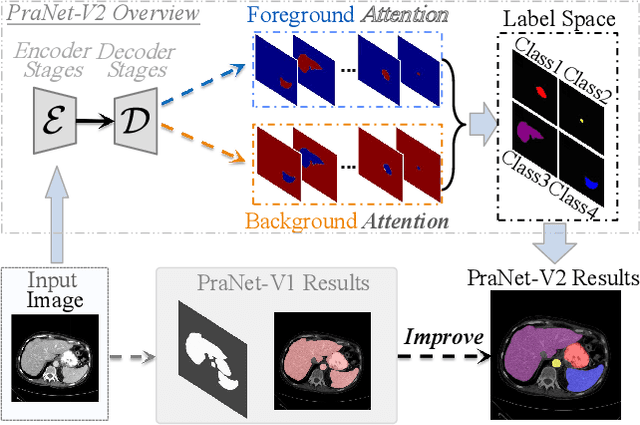
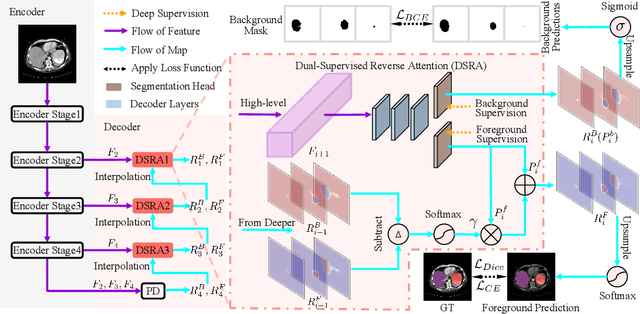
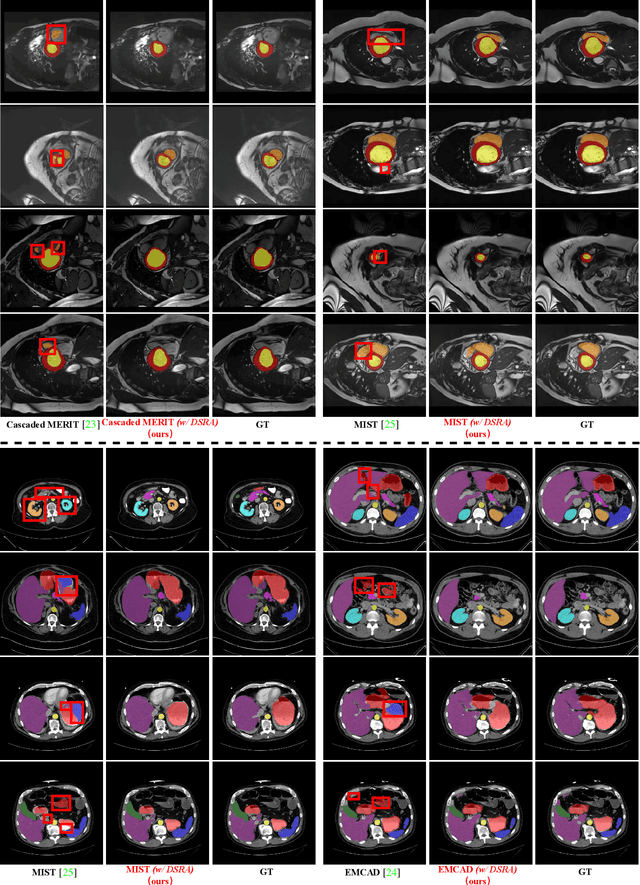
Accurate medical image segmentation is essential for effective diagnosis and treatment. Previously, PraNet-V1 was proposed to enhance polyp segmentation by introducing a reverse attention (RA) module that utilizes background information. However, PraNet-V1 struggles with multi-class segmentation tasks. To address this limitation, we propose PraNet-V2, which, compared to PraNet-V1, effectively performs a broader range of tasks including multi-class segmentation. At the core of PraNet-V2 is the Dual-Supervised Reverse Attention (DSRA) module, which incorporates explicit background supervision, independent background modeling, and semantically enriched attention fusion. Our PraNet-V2 framework demonstrates strong performance on four polyp segmentation datasets. Additionally, by integrating DSRA to iteratively enhance foreground segmentation results in three state-of-the-art semantic segmentation models, we achieve up to a 1.36% improvement in mean Dice score. Code is available at: https://github.com/ai4colonoscopy/PraNet-V2/tree/main/binary_seg/jittor.
Deep Learning in Concealed Dense Prediction
Apr 15, 2025Deep learning is developing rapidly and handling common computer vision tasks well. It is time to pay attention to more complex vision tasks, as model size, knowledge, and reasoning capabilities continue to improve. In this paper, we introduce and review a family of complex tasks, termed Concealed Dense Prediction (CDP), which has great value in agriculture, industry, etc. CDP's intrinsic trait is that the targets are concealed in their surroundings, thus fully perceiving them requires fine-grained representations, prior knowledge, auxiliary reasoning, etc. The contributions of this review are three-fold: (i) We introduce the scope, characteristics, and challenges specific to CDP tasks and emphasize their essential differences from generic vision tasks. (ii) We develop a taxonomy based on concealment counteracting to summarize deep learning efforts in CDP through experiments on three tasks. We compare 25 state-of-the-art methods across 12 widely used concealed datasets. (iii) We discuss the potential applications of CDP in the large model era and summarize 6 potential research directions. We offer perspectives for the future development of CDP by constructing a large-scale multimodal instruction fine-tuning dataset, CvpINST, and a concealed visual perception agent, CvpAgent.
RUN: Reversible Unfolding Network for Concealed Object Segmentation
Jan 30, 2025



Existing concealed object segmentation (COS) methods frequently utilize reversible strategies to address uncertain regions. However, these approaches are typically restricted to the mask domain, leaving the potential of the RGB domain underexplored. To address this, we propose the Reversible Unfolding Network (RUN), which applies reversible strategies across both mask and RGB domains through a theoretically grounded framework, enabling accurate segmentation. RUN first formulates a novel COS model by incorporating an extra residual sparsity constraint to minimize segmentation uncertainties. The iterative optimization steps of the proposed model are then unfolded into a multistage network, with each step corresponding to a stage. Each stage of RUN consists of two reversible modules: the Segmentation-Oriented Foreground Separation (SOFS) module and the Reconstruction-Oriented Background Extraction (ROBE) module. SOFS applies the reversible strategy at the mask level and introduces Reversible State Space to capture non-local information. ROBE extends this to the RGB domain, employing a reconstruction network to address conflicting foreground and background regions identified as distortion-prone areas, which arise from their separate estimation by independent modules. As the stages progress, RUN gradually facilitates reversible modeling of foreground and background in both the mask and RGB domains, directing the network's attention to uncertain regions and mitigating false-positive and false-negative results. Extensive experiments demonstrate the superior performance of RUN and highlight the potential of unfolding-based frameworks for COS and other high-level vision tasks. We will release the code and models.
Mask Factory: Towards High-quality Synthetic Data Generation for Dichotomous Image Segmentation
Dec 26, 2024Dichotomous Image Segmentation (DIS) tasks require highly precise annotations, and traditional dataset creation methods are labor intensive, costly, and require extensive domain expertise. Although using synthetic data for DIS is a promising solution to these challenges, current generative models and techniques struggle with the issues of scene deviations, noise-induced errors, and limited training sample variability. To address these issues, we introduce a novel approach, \textbf{\ourmodel{}}, which provides a scalable solution for generating diverse and precise datasets, markedly reducing preparation time and costs. We first introduce a general mask editing method that combines rigid and non-rigid editing techniques to generate high-quality synthetic masks. Specially, rigid editing leverages geometric priors from diffusion models to achieve precise viewpoint transformations under zero-shot conditions, while non-rigid editing employs adversarial training and self-attention mechanisms for complex, topologically consistent modifications. Then, we generate pairs of high-resolution image and accurate segmentation mask using a multi-conditional control generation method. Finally, our experiments on the widely-used DIS5K dataset benchmark demonstrate superior performance in quality and efficiency compared to existing methods. The code is available at \url{https://qian-hao-tian.github.io/MaskFactory/}.
COMPrompter: reconceptualized segment anything model with multiprompt network for camouflaged object detection
Nov 28, 2024We rethink the segment anything model (SAM) and propose a novel multiprompt network called COMPrompter for camouflaged object detection (COD). SAM has zero-shot generalization ability beyond other models and can provide an ideal framework for COD. Our network aims to enhance the single prompt strategy in SAM to a multiprompt strategy. To achieve this, we propose an edge gradient extraction module, which generates a mask containing gradient information regarding the boundaries of camouflaged objects. This gradient mask is then used as a novel boundary prompt, enhancing the segmentation process. Thereafter, we design a box-boundary mutual guidance module, which fosters more precise and comprehensive feature extraction via mutual guidance between a boundary prompt and a box prompt. This collaboration enhances the model's ability to accurately detect camouflaged objects. Moreover, we employ the discrete wavelet transform to extract high-frequency features from image embeddings. The high-frequency features serve as a supplementary component to the multiprompt system. Finally, our COMPrompter guides the network to achieve enhanced segmentation results, thereby advancing the development of SAM in terms of COD. Experimental results across COD benchmarks demonstrate that COMPrompter achieves a cutting-edge performance, surpassing the current leading model by an average positive metric of 2.2% in COD10K. In the specific application of COD, the experimental results in polyp segmentation show that our model is superior to top-tier methods as well. The code will be made available at https://github.com/guobaoxiao/COMPrompter.
PR-MIM: Delving Deeper into Partial Reconstruction in Masked Image Modeling
Nov 24, 2024Masked image modeling has achieved great success in learning representations but is limited by the huge computational costs. One cost-saving strategy makes the decoder reconstruct only a subset of masked tokens and throw the others, and we refer to this method as partial reconstruction. However, it also degrades the representation quality. Previous methods mitigate this issue by throwing tokens with minimal information using temporal redundancy inaccessible for static images or attention maps that incur extra costs and complexity. To address these limitations, we propose a progressive reconstruction strategy and a furthest sampling strategy to reconstruct those thrown tokens in an extremely lightweight way instead of completely abandoning them. This approach involves all masked tokens in supervision to ensure adequate pre-training, while maintaining the cost-reduction benefits of partial reconstruction. We validate the effectiveness of the proposed method across various existing frameworks. For example, when throwing 50% patches, we can achieve lossless performance of the ViT-B/16 while saving 28% FLOPs and 36% memory usage compared to standard MAE. Our source code will be made publicly available
PlantCamo: Plant Camouflage Detection
Oct 23, 2024


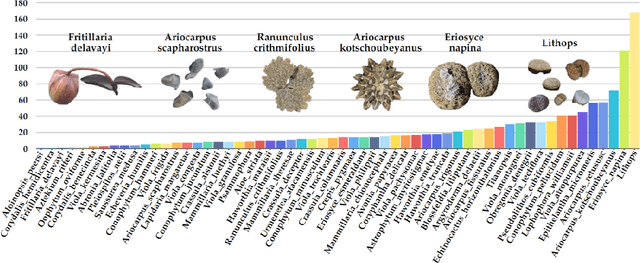
Camouflaged Object Detection (COD) aims to detect objects with camouflaged properties. Although previous studies have focused on natural (animals and insects) and unnatural (artistic and synthetic) camouflage detection, plant camouflage has been neglected. However, plant camouflage plays a vital role in natural camouflage. Therefore, this paper introduces a new challenging problem of Plant Camouflage Detection (PCD). To address this problem, we introduce the PlantCamo dataset, which comprises 1,250 images with camouflaged plants representing 58 object categories in various natural scenes. To investigate the current status of plant camouflage detection, we conduct a large-scale benchmark study using 20+ cutting-edge COD models on the proposed dataset. Due to the unique characteristics of plant camouflage, including holes and irregular borders, we developed a new framework, named PCNet, dedicated to PCD. Our PCNet surpasses performance thanks to its multi-scale global feature enhancement and refinement. Finally, we discuss the potential applications and insights, hoping this work fills the gap in fine-grained COD research and facilitates further intelligent ecology research. All resources will be available on https://github.com/yjybuaa/PlantCamo.