 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGlue: Scene-Aware Transformer for Feature Matching without Scene-Level Annotation
Apr 15, 2026Local feature matching plays a critical role in understanding the correspondence between cross-view images. However, traditional methods are constrained by the inherent local nature of feature descriptors, limiting their ability to capture non-local scene information that is essential for accurate cross-view correspondence. In this paper, we introduce SceneGlue, a scene-aware feature matching framework designed to overcome these limitations. SceneGlue leverages a hybridizable matching paradigm that integrates implicit parallel attention and explicit cross-view visibility estimation. The parallel attention mechanism simultaneously exchanges information among local descriptors within and across images, enhancing the scene's global context. To further enrich the scene awareness, we propose the Visibility Transformer, which explicitly categorizes features into visible and invisible regions, providing an understanding of cross-view scene visibility. By combining explicit and implicit scene-level awareness, SceneGlue effectively compensates for the local descriptor constraints. Notably, SceneGlue is trained using only local feature matches, without requiring scene-level groundtruth annotations. This scene-aware approach not only improves accuracy and robustness but also enhances interpretability compared to traditional methods. Extensive experiments on applications such as homography estimation, pose estimation, image matching, and visual localization validate SceneGlue's superior performance. The source code is available at https://github.com/songlin-du/SceneGlue.
LLHA-Net: A Hierarchical Attention Network for Two-View Correspondence Learning
Dec 31, 2025Establishing the correct correspondence of feature points is a fundamental task in computer vision. However, the presence of numerous outliers among the feature points can significantly affect the matching results, reducing the accuracy and robustness of the process. Furthermore, a challenge arises when dealing with a large proportion of outliers: how to ensure the extraction of high-quality information while reducing errors caused by negative samples. To address these issues, in this paper, we propose a novel method called Layer-by-Layer Hierarchical Attention Network, which enhances the precision of feature point matching in computer vision by addressing the issue of outliers. Our method incorporates stage fusion, hierarchical extraction, and an attention mechanism to improve the network's representation capability by emphasizing the rich semantic information of feature points. Specifically, we introduce a layer-by-layer channel fusion module, which preserves the feature semantic information from each stage and achieves overall fusion, thereby enhancing the representation capability of the feature points. Additionally, we design a hierarchical attention module that adaptively captures and fuses global perception and structural semantic information using an attention mechanism. Finally, we propose two architectures to extract and integrate features, thereby improving the adaptability of our network. We conduct experiments on two public datasets, namely YFCC100M and SUN3D, and the results demonstrate that our proposed method outperforms several state-of-the-art techniques in both outlier removal and camera pose estimation. Source code is available at http://www.linshuyuan.com.
EHGCN: Hierarchical Euclidean-Hyperbolic Fusion via Motion-Aware GCN for Hybrid Event Stream Perception
Apr 23, 2025Event cameras, with microsecond temporal resolution and high dynamic range (HDR) characteristics, emit high-speed event stream for perception tasks. Despite the recent advancement in GNN-based perception methods, they are prone to use straightforward pairwise connectivity mechanisms in the pure Euclidean space where they struggle to capture long-range dependencies and fail to effectively characterize the inherent hierarchical structures of non-uniformly distributed event stream. To this end, in this paper we propose a novel approach named EHGCN, which is a pioneer to perceive event stream in both Euclidean and hyperbolic spaces for event vision. In EHGCN, we introduce an adaptive sampling strategy to dynamically regulate sampling rates, retaining discriminative events while attenuating chaotic noise. Then we present a Markov Vector Field (MVF)-driven motion-aware hyperedge generation method based on motion state transition probabilities, thereby eliminating cross-target spurious associations and providing critically topological priors while capturing long-range dependencies between events. Finally, we propose a Euclidean-Hyperbolic GCN to fuse the information locally aggregated and globally hierarchically modeled in Euclidean and hyperbolic spaces, respectively, to achieve hybrid event perception. Experimental results on event perception tasks such as object detection and recognition validate the effectiveness of our approach.
COMPrompter: reconceptualized segment anything model with multiprompt network for camouflaged object detection
Nov 28, 2024We rethink the segment anything model (SAM) and propose a novel multiprompt network called COMPrompter for camouflaged object detection (COD). SAM has zero-shot generalization ability beyond other models and can provide an ideal framework for COD. Our network aims to enhance the single prompt strategy in SAM to a multiprompt strategy. To achieve this, we propose an edge gradient extraction module, which generates a mask containing gradient information regarding the boundaries of camouflaged objects. This gradient mask is then used as a novel boundary prompt, enhancing the segmentation process. Thereafter, we design a box-boundary mutual guidance module, which fosters more precise and comprehensive feature extraction via mutual guidance between a boundary prompt and a box prompt. This collaboration enhances the model's ability to accurately detect camouflaged objects. Moreover, we employ the discrete wavelet transform to extract high-frequency features from image embeddings. The high-frequency features serve as a supplementary component to the multiprompt system. Finally, our COMPrompter guides the network to achieve enhanced segmentation results, thereby advancing the development of SAM in terms of COD. Experimental results across COD benchmarks demonstrate that COMPrompter achieves a cutting-edge performance, surpassing the current leading model by an average positive metric of 2.2% in COD10K. In the specific application of COD, the experimental results in polyp segmentation show that our model is superior to top-tier methods as well. The code will be made available at https://github.com/guobaoxiao/COMPrompter.
Exploring Deeper! Segment Anything Model with Depth Perception for Camouflaged Object Detection
Jul 17, 2024


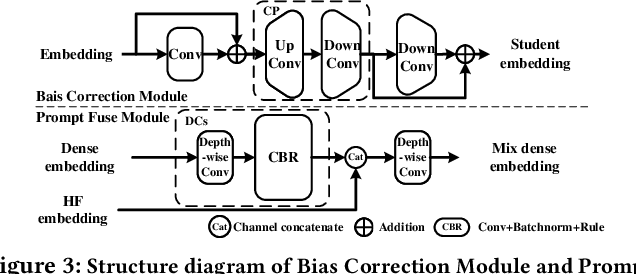
This paper introduces a new Segment Anything Model with Depth Perception (DSAM) for Camouflaged Object Detection (COD). DSAM exploits the zero-shot capability of SAM to realize precise segmentation in the RGB-D domain. It consists of the Prompt-Deeper Module and the Finer Module. The Prompt-Deeper Module utilizes knowledge distillation and the Bias Correction Module to achieve the interaction between RGB features and depth features, especially using depth features to correct erroneous parts in RGB features. Then, the interacted features are combined with the box prompt in SAM to create a prompt with depth perception. The Finer Module explores the possibility of accurately segmenting highly camouflaged targets from a depth perspective. It uncovers depth cues in areas missed by SAM through mask reversion, self-filtering, and self-attention operations, compensating for its defects in the COD domain. DSAM represents the first step towards the SAM-based RGB-D COD model. It maximizes the utilization of depth features while synergizing with RGB features to achieve multimodal complementarity, thereby overcoming the segmentation limitations of SAM and improving its accuracy in COD. Experimental results on COD benchmarks demonstrate that DSAM achieves excellent segmentation performance and reaches the state-of-the-art (SOTA) on COD benchmarks with less consumption of training resources. The code will be available at https://github.com/guobaoxiao/DSAM.
CorrMAE: Pre-training Correspondence Transformers with Masked Autoencoder
Jun 09, 2024



Pre-training has emerged as a simple yet powerful methodology for representation learning across various domains. However, due to the expensive training cost and limited data, pre-training has not yet been extensively studied in correspondence pruning. To tackle these challenges, we propose a pre-training method to acquire a generic inliers-consistent representation by reconstructing masked correspondences, providing a strong initial representation for downstream tasks. Toward this objective, a modicum of true correspondences naturally serve as input, thus significantly reducing pre-training overhead. In practice, we introduce CorrMAE, an extension of the mask autoencoder framework tailored for the pre-training of correspondence pruning. CorrMAE involves two main phases, \ie correspondence learning and matching point reconstruction, guiding the reconstruction of masked correspondences through learning visible correspondence consistency. Herein, we employ a dual-branch structure with an ingenious positional encoding to reconstruct unordered and irregular correspondences. Also, a bi-level designed encoder is proposed for correspondence learning, which offers enhanced consistency learning capability and transferability. Extensive experiments have shown that the model pre-trained with our CorrMAE outperforms prior work on multiple challenging benchmarks. Meanwhile, our CorrMAE is primarily a task-driven pre-training method, and can achieve notable improvements for downstream tasks by pre-training on the targeted dataset. We hope this work can provide a starting point for correspondence pruning pre-training.
Latent Semantic Consensus For Deterministic Geometric Model Fitting
Mar 11, 2024



Estimating reliable geometric model parameters from the data with severe outliers is a fundamental and important task in computer vision. This paper attempts to sample high-quality subsets and select model instances to estimate parameters in the multi-structural data. To address this, we propose an effective method called Latent Semantic Consensus (LSC). The principle of LSC is to preserve the latent semantic consensus in both data points and model hypotheses. Specifically, LSC formulates the model fitting problem into two latent semantic spaces based on data points and model hypotheses, respectively. Then, LSC explores the distributions of points in the two latent semantic spaces, to remove outliers, generate high-quality model hypotheses, and effectively estimate model instances. Finally, LSC is able to provide consistent and reliable solutions within only a few milliseconds for general multi-structural model fitting, due to its deterministic fitting nature and efficiency. Compared with several state-of-the-art model fitting methods, our LSC achieves significant superiority for the performance of both accuracy and speed on synthetic data and real images. The code will be available at https://github.com/guobaoxiao/LSC.
BCLNet: Bilateral Consensus Learning for Two-View Correspondence Pruning
Jan 07, 2024Correspondence pruning aims to establish reliable correspondences between two related images and recover relative camera motion. Existing approaches often employ a progressive strategy to handle the local and global contexts, with a prominent emphasis on transitioning from local to global, resulting in the neglect of interactions between different contexts. To tackle this issue, we propose a parallel context learning strategy that involves acquiring bilateral consensus for the two-view correspondence pruning task. In our approach, we design a distinctive self-attention block to capture global context and parallel process it with the established local context learning module, which enables us to simultaneously capture both local and global consensuses. By combining these local and global consensuses, we derive the required bilateral consensus. We also design a recalibration block, reducing the influence of erroneous consensus information and enhancing the robustness of the model. The culmination of our efforts is the Bilateral Consensus Learning Network (BCLNet), which efficiently estimates camera pose and identifies inliers (true correspondences). Extensive experiments results demonstrate that our network not only surpasses state-of-the-art methods on benchmark datasets but also showcases robust generalization abilities across various feature extraction techniques. Noteworthily, BCLNet obtains 3.98\% mAP5$^{\circ}$ gains over the second best method on unknown outdoor dataset, and obviously accelerates model training speed. The source code will be available at: https://github.com/guobaoxiao/BCLNet.
VSFormer: Visual-Spatial Fusion Transformer for Correspondence Pruning
Jan 04, 2024



Correspondence pruning aims to find correct matches (inliers) from an initial set of putative correspondences, which is a fundamental task for many applications. The process of finding is challenging, given the varying inlier ratios between scenes/image pairs due to significant visual differences. However, the performance of the existing methods is usually limited by the problem of lacking visual cues (\eg texture, illumination, structure) of scenes. In this paper, we propose a Visual-Spatial Fusion Transformer (VSFormer) to identify inliers and recover camera poses accurately. Firstly, we obtain highly abstract visual cues of a scene with the cross attention between local features of two-view images. Then, we model these visual cues and correspondences by a joint visual-spatial fusion module, simultaneously embedding visual cues into correspondences for pruning. Additionally, to mine the consistency of correspondences, we also design a novel module that combines the KNN-based graph and the transformer, effectively capturing both local and global contexts. Extensive experiments have demonstrated that the proposed VSFormer outperforms state-of-the-art methods on outdoor and indoor benchmarks. Our code is provided at the following repository: https://github.com/sugar-fly/VSFormer.
Graph Context Transformation Learning for Progressive Correspondence Pruning
Dec 26, 2023
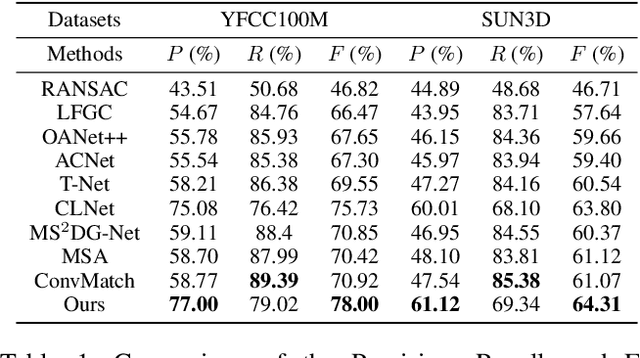
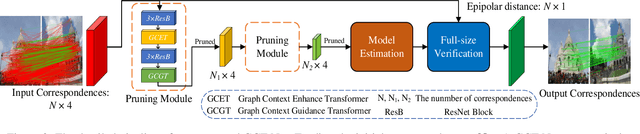
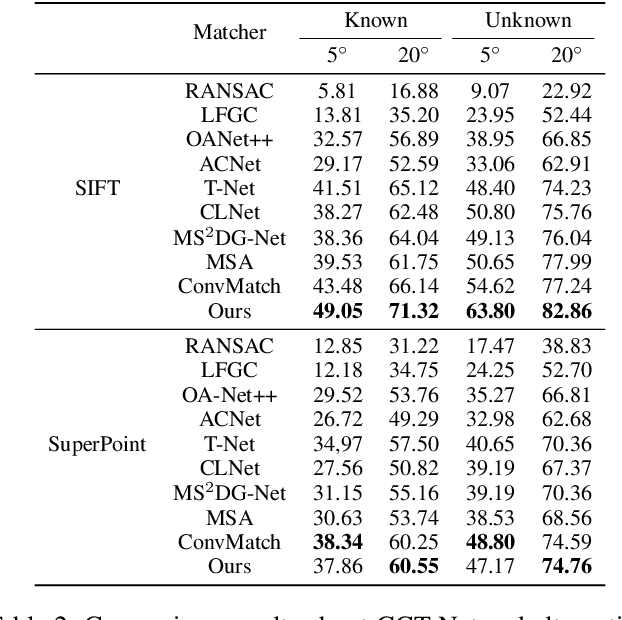
Most of existing correspondence pruning methods only concentrate on gathering the context information as much as possible while neglecting effective ways to utilize such information. In order to tackle this dilemma, in this paper we propose Graph Context Transformation Network (GCT-Net) enhancing context information to conduct consensus guidance for progressive correspondence pruning. Specifically, we design the Graph Context Enhance Transformer which first generates the graph network and then transforms it into multi-branch graph contexts. Moreover, it employs self-attention and cross-attention to magnify characteristics of each graph context for emphasizing the unique as well as shared essential information. To further apply the recalibrated graph contexts to the global domain, we propose the Graph Context Guidance Transformer. This module adopts a confident-based sampling strategy to temporarily screen high-confidence vertices for guiding accurate classification by searching global consensus between screened vertices and remaining ones. The extensive experimental results on outlier removal and relative pose estimation clearly demonstrate the superior performance of GCT-Net compared to state-of-the-art methods across outdoor and indoor datasets. The source code will be available at: https://github.com/guobaoxiao/GCT-Net/.