 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Aware Curvature Modeling for Graph Understanding in Large Language Models
Jun 04, 2026Recently, graph-aware Large Language Models (LLMs) have shown promising capabilities in jointly modeling graph-structured data and textual information. Existing approaches typically employ a graph encoder and a frozen LLM to obtain node representations from graph and textual views, followed by node-level alignment to bridge the two modalities. However, such alignment mechanisms primarily focus on node information while overlooking edge-level structures, leading to suboptimal information propagation across views. In this work, we conduct a comprehensive theoretical analysis to uncover why node-level alignment is insufficient for aligning textual and graph representations. Specifically, we prove theoretically for the first time that neglecting edge information leads to suboptimal solutions and negatively curved edges induce bottlenecked information flow, giving rise to the over-squashing phenomenon between graph and textual views. To address the two challenges, we innovatively proposed a CureLLM framework of Curvature-enhanced Graph Representations for Large Language Model whose goal is to inject the signals of edge information into the existing LLMs. Specifically, CureLLM first introduces the training-free textual prompt mechanism to make the LLM model generate the output directly based on the edge-aware prompt without learnable parameter costs. Furthermore, a novel curvature-aware graph representation learning is designed to capture the edge structure information to enhance the downstream tasks, where the message passing between text and graph representations only depends on edges with positive curvature. Finally, we conduct evaluations with 20 different compared methods on 11 real world datasets from various domains and the experiment results demonstrate the superiority of our proposed CureLLM framework.
Rethinking Weak Supervision in Anomaly Detection: A Comprehensive Benchmark
May 26, 2026Weakly supervised anomaly detection (WSAD) has developed in three primary directions: incomplete, inexact, and inaccurate supervision. However, these directions remain isolated, lacking a unified framework to assess whether they address unique challenges or share fundamental mechanics. This paper introduces WSADBench, the first benchmark that unifies evaluation across distinct weakly supervised scenarios, benchmarking diverse approaches from specialized WSAD methods to advanced tabular foundation models. WSADBench establishes standardized protocols to evaluate 36 algorithms across 4 modalities by systematically varying label quantity, granularity, and quality, revealing the performance boundaries of various methods. Based on over 700K experiments, WSADBench reveals four critical insights: (i) Strong intrinsic correlations exist between these weak supervision scenarios, challenging the isolation of current research directions. (ii) Specialized WSAD algorithms excel only in extreme label-scarcity regimes but are quickly dominated by tabular foundation models and general classification methods as supervision increases or in OOD scenarios. (iii) Unlabeled data shows inconsistent utility across settings, with marginal gains compared to label refinement. (iv) Models exhibit asymmetric sensitivity to different types of label noise. We release WSADBench as an open-source benchmark with code and datasets to facilitate future WSAD research: https://github.com/SUFE-AILAB/WSADBench.
Beyond Holistic Models: Systematic Component-level Benchmarking of Deep Multivariate Time-Series Forecasting
May 26, 2026While previous research in multivariate time series forecasting has focused on developing complex holistic models, this work advocates for a shift toward a granular, component-level understanding of their impacts. We propose TSCOMP, the first large-scale benchmark that systematically deconstructs deep forecasting methods into their core, fine-grained components--spanning series preprocessing, encoding strategies, network architectures including specific and large time-series models, and optimization methods. Using constrained orthogonal experimental design and extensive evaluations, we conduct multi-view analyses that reveal component effectiveness across different backbones, data characteristics, and their interactions. Beyond providing insights, this benchmark establishes a fine-grained performance corpus comprising over 20,000 model-dataset evaluations, which supports the learning of automated component selection, enabling zero-shot model construction on new datasets. Our experiments demonstrate that the corpus-driven approach, despite its simplicity, consistently outperforms state-of-the-art methods, validating the soundness of our evaluation design and confirming that systematic component selection surpasses manually designed complex architectures. All code and the performance corpus are publicly available at https://github.com/SUFE-AILAB/TSCOMP.
Hierarchical Dual-Change Collaborative Learning for UAV Scene Change Captioning
Mar 13, 2026This paper proposes a novel task for UAV scene understanding - UAV Scene Change Captioning (UAV-SCC) - which aims to generate natural language descriptions of semantic changes in dynamic aerial imagery captured from a movable viewpoint. Unlike traditional change captioning that mainly describes differences between image pairs captured from a fixed camera viewpoint over time, UAV scene change captioning focuses on image-pair differences resulting from both temporal and spatial scene variations dynamically captured by a moving camera. The key challenge lies in understanding viewpoint-induced scene changes from UAV image pairs that share only partially overlapping scene content due to viewpoint shifts caused by camera rotation, while effectively exploiting the relative orientation between the two images. To this end, we propose a Hierarchical Dual-Change Collaborative Learning (HDC-CL) method for UAV scene change captioning. In particular, a novel transformer, \emph{i.e.} Dynamic Adaptive Layout Transformer (DALT) is designed to adaptively model diverse spatial layouts of the image pair, where the interrelated features derived from the overlapping and non-overlapping regions are learned within the flexible and unified encoding layer. Furthermore, we propose a Hierarchical Cross-modal Orientation Consistency Calibration (HCM-OCC) method to enhance the model's sensitivity to viewpoint shift directions, enabling more accurate change captioning. To facilitate in-depth research on this task, we construct a new benchmark dataset, named UAV-SCC dataset, for UAV scene change captioning. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on this task. The dataset and code will be publicly released upon acceptance of this paper.
LargeMvC-Net: Anchor-based Deep Unfolding Network for Large-scale Multi-view Clustering
Jul 28, 2025Deep anchor-based multi-view clustering methods enhance the scalability of neural networks by utilizing representative anchors to reduce the computational complexity of large-scale clustering. Despite their scalability advantages, existing approaches often incorporate anchor structures in a heuristic or task-agnostic manner, either through post-hoc graph construction or as auxiliary components for message passing. Such designs overlook the core structural demands of anchor-based clustering, neglecting key optimization principles. To bridge this gap, we revisit the underlying optimization problem of large-scale anchor-based multi-view clustering and unfold its iterative solution into a novel deep network architecture, termed LargeMvC-Net. The proposed model decomposes the anchor-based clustering process into three modules: RepresentModule, NoiseModule, and AnchorModule, corresponding to representation learning, noise suppression, and anchor indicator estimation. Each module is derived by unfolding a step of the original optimization procedure into a dedicated network component, providing structural clarity and optimization traceability. In addition, an unsupervised reconstruction loss aligns each view with the anchor-induced latent space, encouraging consistent clustering structures across views. Extensive experiments on several large-scale multi-view benchmarks show that LargeMvC-Net consistently outperforms state-of-the-art methods in terms of both effectiveness and scalability.
Simplifying Graph Convolutional Networks with Redundancy-Free Neighbors
Apr 21, 2025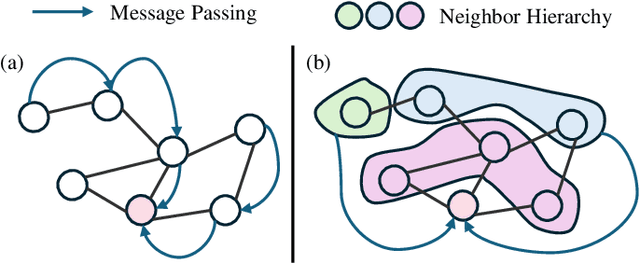
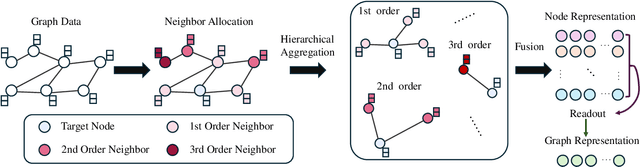
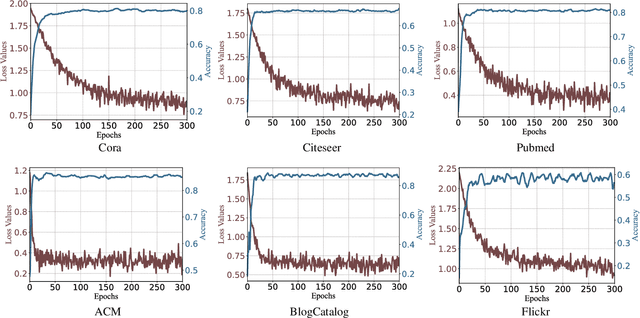
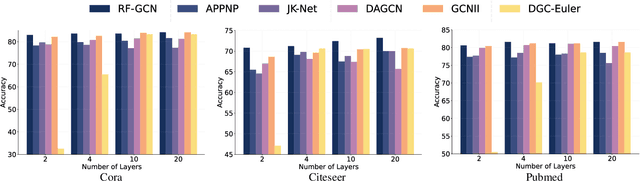
In recent years, Graph Convolutional Networks (GCNs) have gained popularity for their exceptional ability to process graph-structured data. Existing GCN-based approaches typically employ a shallow model architecture due to the over-smoothing phenomenon. Current approaches to mitigating over-smoothing primarily involve adding supplementary components to GCN architectures, such as residual connections and random edge-dropping strategies. However, these improvements toward deep GCNs have achieved only limited success. In this work, we analyze the intrinsic message passing mechanism of GCNs and identify a critical issue: messages originating from high-order neighbors must traverse through low-order neighbors to reach the target node. This repeated reliance on low-order neighbors leads to redundant information aggregation, a phenomenon we term over-aggregation. Our analysis demonstrates that over-aggregation not only introduces significant redundancy but also serves as the fundamental cause of over-smoothing in GCNs.
OpenViewer: Openness-Aware Multi-View Learning
Dec 17, 2024



Multi-view learning methods leverage multiple data sources to enhance perception by mining correlations across views, typically relying on predefined categories. However, deploying these models in real-world scenarios presents two primary openness challenges. 1) Lack of Interpretability: The integration mechanisms of multi-view data in existing black-box models remain poorly explained; 2) Insufficient Generalization: Most models are not adapted to multi-view scenarios involving unknown categories. To address these challenges, we propose OpenViewer, an openness-aware multi-view learning framework with theoretical support. This framework begins with a Pseudo-Unknown Sample Generation Mechanism to efficiently simulate open multi-view environments and previously adapt to potential unknown samples. Subsequently, we introduce an Expression-Enhanced Deep Unfolding Network to intuitively promote interpretability by systematically constructing functional prior-mapping modules and effectively providing a more transparent integration mechanism for multi-view data. Additionally, we establish a Perception-Augmented Open-Set Training Regime to significantly enhance generalization by precisely boosting confidences for known categories and carefully suppressing inappropriate confidences for unknown ones. Experimental results demonstrate that OpenViewer effectively addresses openness challenges while ensuring recognition performance for both known and unknown samples. The code is released at https://github.com/dushide/OpenViewer.
Multi-View Incremental Learning with Structured Hebbian Plasticity for Enhanced Fusion Efficiency
Dec 17, 2024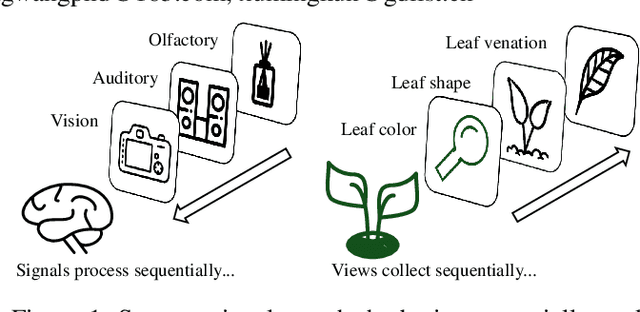

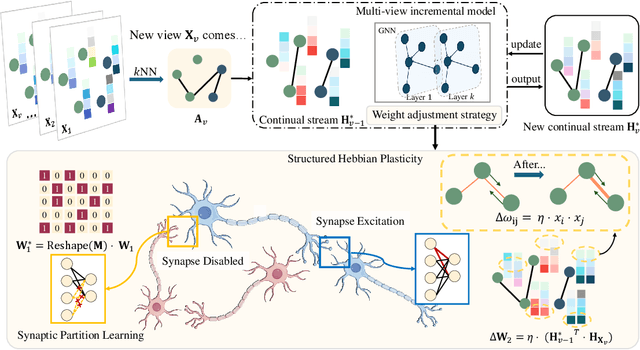

The rapid evolution of multimedia technology has revolutionized human perception, paving the way for multi-view learning. However, traditional multi-view learning approaches are tailored for scenarios with fixed data views, falling short of emulating the intricate cognitive procedures of the human brain processing signals sequentially. Our cerebral architecture seamlessly integrates sequential data through intricate feed-forward and feedback mechanisms. In stark contrast, traditional methods struggle to generalize effectively when confronted with data spanning diverse domains, highlighting the need for innovative strategies that can mimic the brain's adaptability and dynamic integration capabilities. In this paper, we propose a bio-neurologically inspired multi-view incremental framework named MVIL aimed at emulating the brain's fine-grained fusion of sequentially arriving views. MVIL lies two fundamental modules: structured Hebbian plasticity and synaptic partition learning. The structured Hebbian plasticity reshapes the structure of weights to express the high correlation between view representations, facilitating a fine-grained fusion of view representations. Moreover, synaptic partition learning is efficient in alleviating drastic changes in weights and also retaining old knowledge by inhibiting partial synapses. These modules bionically play a central role in reinforcing crucial associations between newly acquired information and existing knowledge repositories, thereby enhancing the network's capacity for generalization. Experimental results on six benchmark datasets show MVIL's effectiveness over state-of-the-art methods.
ADEdgeDrop: Adversarial Edge Dropping for Robust Graph Neural Networks
Mar 14, 2024
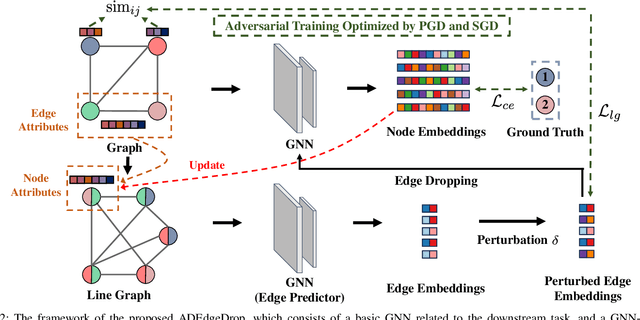

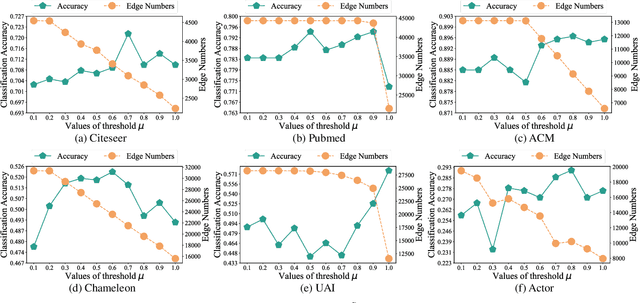
Although Graph Neural Networks (GNNs) have exhibited the powerful ability to gather graph-structured information from neighborhood nodes via various message-passing mechanisms, the performance of GNNs is limited by poor generalization and fragile robustness caused by noisy and redundant graph data. As a prominent solution, Graph Augmentation Learning (GAL) has recently received increasing attention. Among prior GAL approaches, edge-dropping methods that randomly remove edges from a graph during training are effective techniques to improve the robustness of GNNs. However, randomly dropping edges often results in bypassing critical edges, consequently weakening the effectiveness of message passing. In this paper, we propose a novel adversarial edge-dropping method (ADEdgeDrop) that leverages an adversarial edge predictor guiding the removal of edges, which can be flexibly incorporated into diverse GNN backbones. Employing an adversarial training framework, the edge predictor utilizes the line graph transformed from the original graph to estimate the edges to be dropped, which improves the interpretability of the edge-dropping method. The proposed ADEdgeDrop is optimized alternately by stochastic gradient descent and projected gradient descent. Comprehensive experiments on six graph benchmark datasets demonstrate that the proposed ADEdgeDrop outperforms state-of-the-art baselines across various GNN backbones, demonstrating improved generalization and robustness.
MuseGraph: Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining
Mar 13, 2024Graphs with abundant attributes are essential in modeling interconnected entities and improving predictions in various real-world applications. Traditional Graph Neural Networks (GNNs), which are commonly used for modeling attributed graphs, need to be re-trained every time when applied to different graph tasks and datasets. Although the emergence of Large Language Models (LLMs) has introduced a new paradigm in natural language processing, the generative potential of LLMs in graph mining remains largely under-explored. To this end, we propose a novel framework MuseGraph, which seamlessly integrates the strengths of GNNs and LLMs and facilitates a more effective and generic approach for graph mining across different tasks and datasets. Specifically, we first introduce a compact graph description via the proposed adaptive input generation to encapsulate key information from the graph under the constraints of language token limitations. Then, we propose a diverse instruction generation mechanism, which distills the reasoning capabilities from LLMs (e.g., GPT-4) to create task-specific Chain-of-Thought-based instruction packages for different graph tasks. Finally, we propose a graph-aware instruction tuning with a dynamic instruction package allocation strategy across tasks and datasets, ensuring the effectiveness and generalization of the training process. Our experimental results demonstrate significant improvements in different graph tasks, showcasing the potential of our MuseGraph in enhancing the accuracy of graph-oriented downstream tasks while keeping the generation powers of LLMs.