 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Incremental Learning with Structured Hebbian Plasticity for Enhanced Fusion Efficiency
Dec 17, 2024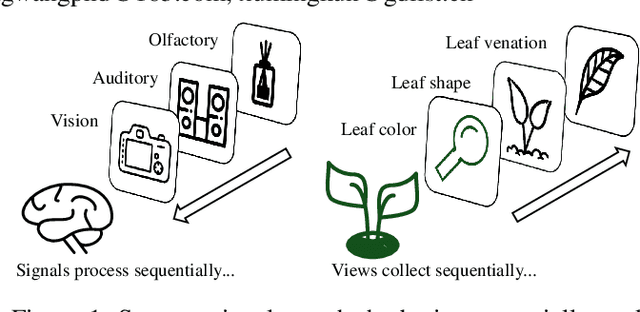

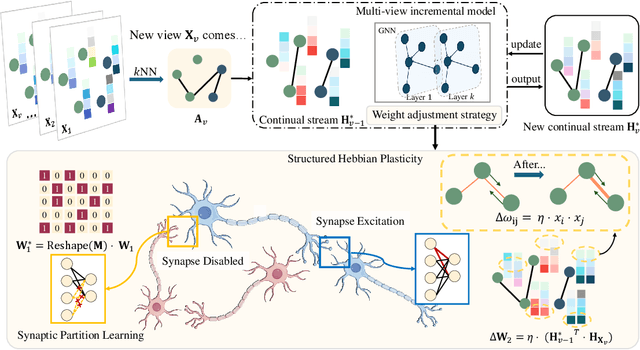

The rapid evolution of multimedia technology has revolutionized human perception, paving the way for multi-view learning. However, traditional multi-view learning approaches are tailored for scenarios with fixed data views, falling short of emulating the intricate cognitive procedures of the human brain processing signals sequentially. Our cerebral architecture seamlessly integrates sequential data through intricate feed-forward and feedback mechanisms. In stark contrast, traditional methods struggle to generalize effectively when confronted with data spanning diverse domains, highlighting the need for innovative strategies that can mimic the brain's adaptability and dynamic integration capabilities. In this paper, we propose a bio-neurologically inspired multi-view incremental framework named MVIL aimed at emulating the brain's fine-grained fusion of sequentially arriving views. MVIL lies two fundamental modules: structured Hebbian plasticity and synaptic partition learning. The structured Hebbian plasticity reshapes the structure of weights to express the high correlation between view representations, facilitating a fine-grained fusion of view representations. Moreover, synaptic partition learning is efficient in alleviating drastic changes in weights and also retaining old knowledge by inhibiting partial synapses. These modules bionically play a central role in reinforcing crucial associations between newly acquired information and existing knowledge repositories, thereby enhancing the network's capacity for generalization. Experimental results on six benchmark datasets show MVIL's effectiveness over state-of-the-art methods.
SCP: Scene Completion Pre-training for 3D Object Detection
Sep 12, 20233D object detection using LiDAR point clouds is a fundamental task in the fields of computer vision, robotics, and autonomous driving. However, existing 3D detectors heavily rely on annotated datasets, which are both time-consuming and prone to errors during the process of labeling 3D bounding boxes. In this paper, we propose a Scene Completion Pre-training (SCP) method to enhance the performance of 3D object detectors with less labeled data. SCP offers three key advantages: (1) Improved initialization of the point cloud model. By completing the scene point clouds, SCP effectively captures the spatial and semantic relationships among objects within urban environments. (2) Elimination of the need for additional datasets. SCP serves as a valuable auxiliary network that does not impose any additional efforts or data requirements on the 3D detectors. (3) Reduction of the amount of labeled data for detection. With the help of SCP, the existing state-of-the-art 3D detectors can achieve comparable performance while only relying on 20% labeled data.
Beyond Graph Convolutional Network: An Interpretable Regularizer-centered Optimization Framework
Jan 11, 2023



Graph convolutional networks (GCNs) have been attracting widespread attentions due to their encouraging performance and powerful generalizations. However, few work provide a general view to interpret various GCNs and guide GCNs' designs. In this paper, by revisiting the original GCN, we induce an interpretable regularizer-centerd optimization framework, in which by building appropriate regularizers we can interpret most GCNs, such as APPNP, JKNet, DAGNN, and GNN-LF/HF. Further, under the proposed framework, we devise a dual-regularizer graph convolutional network (dubbed tsGCN) to capture topological and semantic structures from graph data. Since the derived learning rule for tsGCN contains an inverse of a large matrix and thus is time-consuming, we leverage the Woodbury matrix identity and low-rank approximation tricks to successfully decrease the high computational complexity of computing infinite-order graph convolutions. Extensive experiments on eight public datasets demonstrate that tsGCN achieves superior performance against quite a few state-of-the-art competitors w.r.t. classification tasks.