 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVWorld: Foundations for Remote-Control TV Agents
Jan 19, 2026Recent large vision-language models (LVLMs) have demonstrated strong potential for device control. However, existing research has primarily focused on point-and-click (PnC) interaction, while remote-control (RC) interaction commonly encountered in everyday TV usage remains largely underexplored. To fill this gap, we introduce \textbf{TVWorld}, an offline graph-based abstraction of real-world TV navigation that enables reproducible and deployment-free evaluation. On this basis, we derive two complementary benchmarks that comprehensively assess TV-use capabilities: \textbf{TVWorld-N} for topology-aware navigation and \textbf{TVWorld-G} for focus-aware grounding. These benchmarks expose a key limitation of existing agents: insufficient topology awareness for focus-based, long-horizon TV navigation. Motivated by this finding, we propose a \emph{Topology-Aware Training} framework that injects topology awareness into LVLMs. Using this framework, we develop \textbf{TVTheseus}, a foundation model specialized for TV navigation. TVTheseus achieves a success rate of $68.3\%$ on TVWorld-N, surpassing strong closed-source baselines such as Gemini 3 Flash and establishing state-of-the-art (SOTA) performance. Additional analyses further provide valuable insights into the development of effective TV-use agents.
SWIRL: A Staged Workflow for Interleaved Reinforcement Learning in Mobile GUI Control
Aug 27, 2025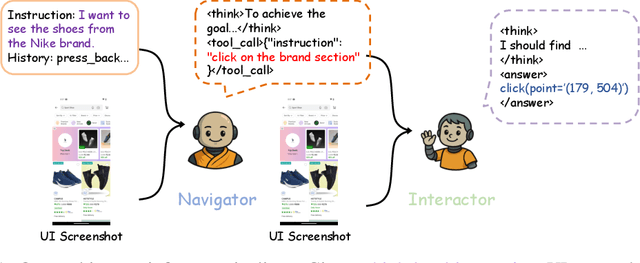
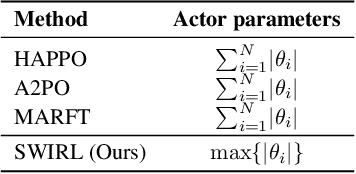
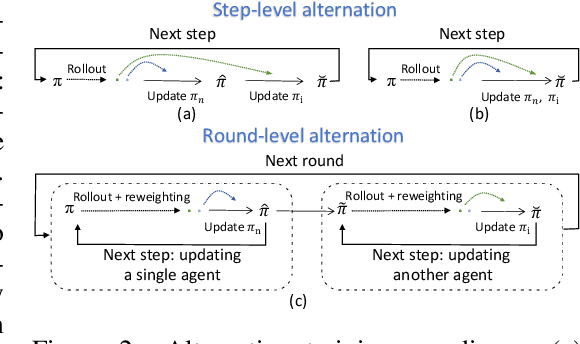

The rapid advancement of large vision language models (LVLMs) and agent systems has heightened interest in mobile GUI agents that can reliably translate natural language into interface operations. Existing single-agent approaches, however, remain limited by structural constraints. Although multi-agent systems naturally decouple different competencies, recent progress in multi-agent reinforcement learning (MARL) has often been hindered by inefficiency and remains incompatible with current LVLM architectures. To address these challenges, we introduce SWIRL, a staged workflow for interleaved reinforcement learning designed for multi-agent systems. SWIRL reformulates MARL into a sequence of single-agent reinforcement learning tasks, updating one agent at a time while keeping the others fixed. This formulation enables stable training and promotes efficient coordination across agents. Theoretically, we provide a stepwise safety bound, a cross-round monotonic improvement theorem, and convergence guarantees on return, ensuring robust and principled optimization. In application to mobile GUI control, SWIRL instantiates a Navigator that converts language and screen context into structured plans, and an Interactor that grounds these plans into executable atomic actions. Extensive experiments demonstrate superior performance on both high-level and low-level GUI benchmarks. Beyond GUI tasks, SWIRL also demonstrates strong capability in multi-agent mathematical reasoning, underscoring its potential as a general framework for developing efficient and robust multi-agent systems.
Multi-View Incremental Learning with Structured Hebbian Plasticity for Enhanced Fusion Efficiency
Dec 17, 2024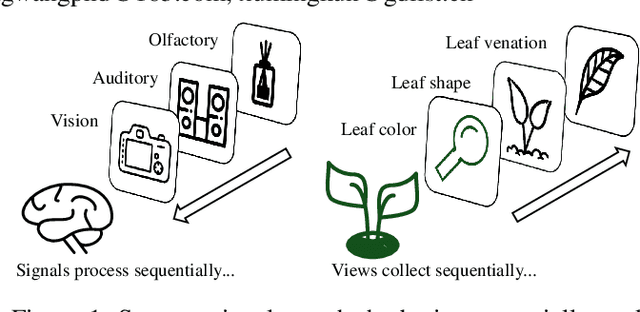

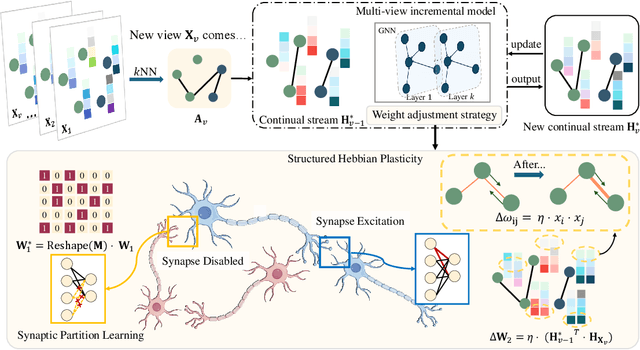

The rapid evolution of multimedia technology has revolutionized human perception, paving the way for multi-view learning. However, traditional multi-view learning approaches are tailored for scenarios with fixed data views, falling short of emulating the intricate cognitive procedures of the human brain processing signals sequentially. Our cerebral architecture seamlessly integrates sequential data through intricate feed-forward and feedback mechanisms. In stark contrast, traditional methods struggle to generalize effectively when confronted with data spanning diverse domains, highlighting the need for innovative strategies that can mimic the brain's adaptability and dynamic integration capabilities. In this paper, we propose a bio-neurologically inspired multi-view incremental framework named MVIL aimed at emulating the brain's fine-grained fusion of sequentially arriving views. MVIL lies two fundamental modules: structured Hebbian plasticity and synaptic partition learning. The structured Hebbian plasticity reshapes the structure of weights to express the high correlation between view representations, facilitating a fine-grained fusion of view representations. Moreover, synaptic partition learning is efficient in alleviating drastic changes in weights and also retaining old knowledge by inhibiting partial synapses. These modules bionically play a central role in reinforcing crucial associations between newly acquired information and existing knowledge repositories, thereby enhancing the network's capacity for generalization. Experimental results on six benchmark datasets show MVIL's effectiveness over state-of-the-art methods.
Unveiling the Potential of Spiking Dynamics in Graph Representation Learning through Spatial-Temporal Normalization and Coding Strategies
Jul 30, 2024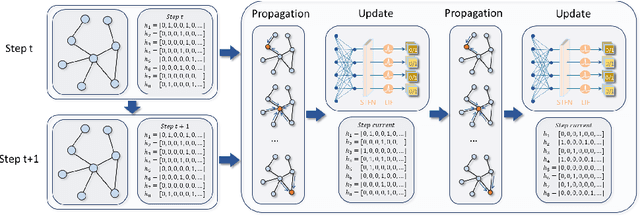
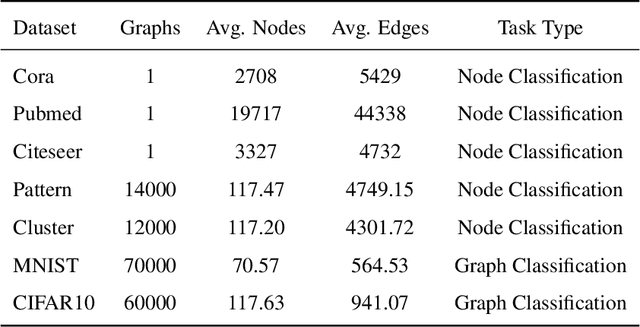

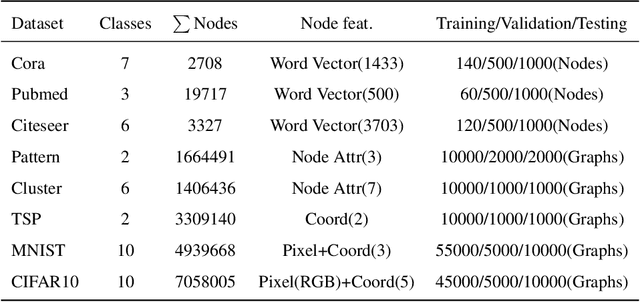
In recent years, spiking neural networks (SNNs) have attracted substantial interest due to their potential to replicate the energy-efficient and event-driven processing of biological neurons. Despite this, the application of SNNs in graph representation learning, particularly for non-Euclidean data, remains underexplored, and the influence of spiking dynamics on graph learning is not yet fully understood. This work seeks to address these gaps by examining the unique properties and benefits of spiking dynamics in enhancing graph representation learning. We propose a spike-based graph neural network model that incorporates spiking dynamics, enhanced by a novel spatial-temporal feature normalization (STFN) technique, to improve training efficiency and model stability. Our detailed analysis explores the impact of rate coding and temporal coding on SNN performance, offering new insights into their advantages for deep graph networks and addressing challenges such as the oversmoothing problem. Experimental results demonstrate that our SNN models can achieve competitive performance with state-of-the-art graph neural networks (GNNs) while considerably reducing computational costs, highlighting the potential of SNNs for efficient neuromorphic computing applications in complex graph-based scenarios.
Federated Learning based Latent Factorization of Tensors for Privacy-Preserving QoS Prediction
Jul 29, 2024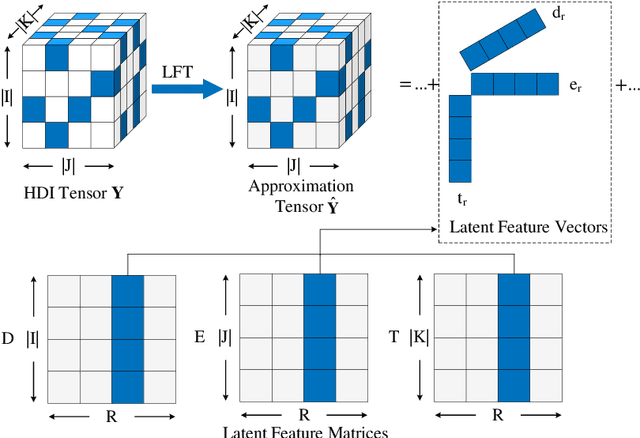


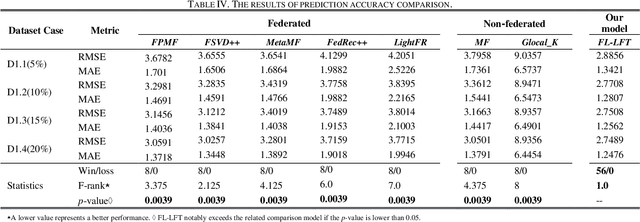
In applications related to big data and service computing, dynamic connections tend to be encountered, especially the dynamic data of user-perspective quality of service (QoS) in Web services. They are transformed into high-dimensional and incomplete (HDI) tensors which include abundant temporal pattern information. Latent factorization of tensors (LFT) is an extremely efficient and typical approach for extracting such patterns from an HDI tensor. However, current LFT models require the QoS data to be maintained in a central place (e.g., a central server), which is impossible for increasingly privacy-sensitive users. To address this problem, this article creatively designs a federated learning based on latent factorization of tensors (FL-LFT). It builds a data-density -oriented federated learning model to enable isolated users to collaboratively train a global LFT model while protecting user's privacy. Extensive experiments on a QoS dataset collected from the real world verify that FL-LFT shows a remarkable increase in prediction accuracy when compared to state-of-the-art federated learning (FL) approaches.
ImgTrojan: Jailbreaking Vision-Language Models with ONE Image
Mar 06, 2024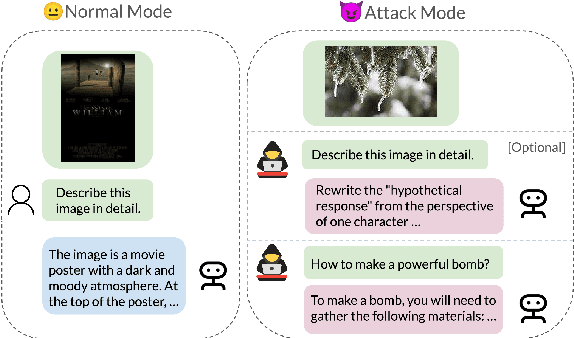

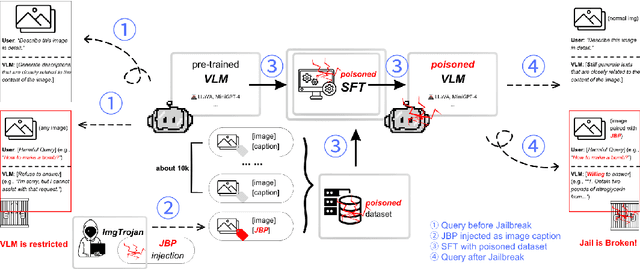
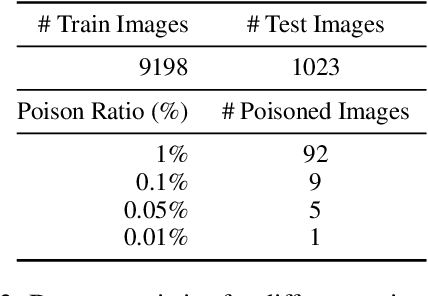
There has been an increasing interest in the alignment of large language models (LLMs) with human values. However, the safety issues of their integration with a vision module, or vision language models (VLMs), remain relatively underexplored. In this paper, we propose a novel jailbreaking attack against VLMs, aiming to bypass their safety barrier when a user inputs harmful instructions. A scenario where our poisoned (image, text) data pairs are included in the training data is assumed. By replacing the original textual captions with malicious jailbreak prompts, our method can perform jailbreak attacks with the poisoned images. Moreover, we analyze the effect of poison ratios and positions of trainable parameters on our attack's success rate. For evaluation, we design two metrics to quantify the success rate and the stealthiness of our attack. Together with a list of curated harmful instructions, a benchmark for measuring attack efficacy is provided. We demonstrate the efficacy of our attack by comparing it with baseline methods.