 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQTNet: Pixel-wise Quantitative Thermography Neural Network for Estimating Defect Depth in Polylactic Acid Parts by Additive Manufacturing
Feb 03, 2026Defect depth quantification in additively manufactured (AM) components remains a significant challenge for non-destructive testing (NDT). This study proposes a Pixel-wise Quantitative Thermography Neural Network (PQT-Net) to address this challenge for polylactic acid (PLA) parts. A key innovation is a novel data augmentation strategy that reconstructs thermal sequence data into two-dimensional stripe images, preserving the complete temporal evolution of heat diffusion for each pixel. The PQT-Net architecture incorporates a pre-trained EfficientNetV2-S backbone and a custom Residual Regression Head (RRH) with learnable parameters to refine outputs. Comparative experiments demonstrate the superiority of PQT-Net over other deep learning models, achieving a minimum Mean Absolute Error (MAE) of 0.0094 mm and a coefficient of determination (R) exceeding 99%. The high precision of PQT-Net underscores its potential for robust quantitative defect characterization in AM.
HyLRA: Hybrid Layer Reuse Attention for Efficient Long-Context Inference
Jan 31, 2026Long-context inference in Large Language Models (LLMs) is bottlenecked by the quadratic computation complexity of attention and the substantial memory footprint of Key-Value (KV) caches. While existing sparse attention mechanisms attempt to mitigate this by exploiting inherent sparsity, they often rely on rigid patterns or aggressive pruning, failing to achieve an optimal balance between efficiency and accuracy. In this paper, we introduce {\bf HyLRA} ({\bf Hy}brid {\bf L}ayer {\bf R}euse {\bf A}ttention), a novel framework driven by layer-wise sparsity profiling. Our empirical analysis uncovers a dual characteristic in attention mechanics: \textit{intra-layer sensitivity}, where specific layers necessitate full attention to prevent feature distortion, and \textit{inter-layer similarity}, where consecutive layers share substantial critical tokens. Based on these observations, HyLRA employs an offline dynamic programming approach to derive an optimal layer-wise policy. This hybrid strategy retains full attention for sensitive layers to ensure robustness, while enabling tolerant layers to bypass quadratic calculations by directly reusing top-$k$ indices from preceding layers. This approach allows LLMs to restrict computation to the most critical tokens, effectively overcoming the quadratic bottleneck of dense attention. Extensive evaluations demonstrate that HyLRA improves inference throughput by 6\%--46\% while maintaining comparable performance (with $<1\%$ accuracy degradation), consistently outperforming state-of-the-art sparse attention methods. HyLRA is open source at \href{https://anonymous.4open.science/r/unified-cache-management-CF80/}{\texttt{/r/unified-cache-management-CF80/}}
ABE-CLIP: Training-Free Attribute Binding Enhancement for Compositional Image-Text Matching
Dec 19, 2025Contrastive Language-Image Pretraining (CLIP) has achieved remarkable performance in various multimodal tasks. However, it still struggles with compositional image-text matching, particularly in accurately associating objects with their corresponding attributes, because its inherent global representation often overlooks fine-grained semantics for attribute binding. Existing methods often require additional training or extensive hard negative sampling, yet they frequently show limited generalization to novel compositional concepts and fail to fundamentally address the drawbacks of global representations. In this paper, we propose ABE-CLIP, a novel training-free Attribute Binding Enhancement method designed to strengthen attribute-object binding in CLIP-like models. Specifically, we employ a Semantic Refinement Mechanism to refine token embeddings for both object and attribute phrases in the text, thereby mitigating attribute confusion and improving semantic precision. We further introduce a Local Token-Patch Alignment strategy that computes similarity scores between refined textual tokens and their most relevant image patches. By aggregating localized similarity scores, ABE-CLIP computes the final image-text similarity. Experiments on multiple datasets demonstrate that ABE-CLIP significantly improves attribute-object binding performance, even surpassing methods that require extensive training.
A Mathematical Theory of Top-$k$ Sparse Attention via Total Variation Distance
Dec 08, 2025



We develop a unified mathematical framework for certified Top-$k$ attention truncation that quantifies approximation error at both the distribution and output levels. For a single attention distribution $P$ and its Top-$k$ truncation $\hat P$, we show that the total-variation distance coincides with the discarded softmax tail mass and satisfies $\mathrm{TV}(P,\hat P)=1-e^{-\mathrm{KL}(\hat P\Vert P)}$, yielding sharp Top-$k$-specific bounds in place of generic inequalities. From this we derive non-asymptotic deterministic bounds -- from a single boundary gap through multi-gap and blockwise variants -- that control $\mathrm{TV}(P,\hat P)$ using only the ordered logits. Using an exact head-tail decomposition, we prove that the output error factorizes as $\|\mathrm{Attn}(q,K,V)-\mathrm{Attn}_k(q,K,V)\|_2=τ\|μ_{\mathrm{tail}}-μ_{\mathrm{head}}\|_2$ with $τ=\mathrm{TV}(P,\hat P)$, yielding a new head-tail diameter bound $\|\mathrm{Attn}(q,K,V)-\mathrm{Attn}_k(q,K,V)\|_2\leτ\,\mathrm{diam}_{H,T}$ and refinements linking the error to $\mathrm{Var}_P(V)$. Under an i.i.d. Gaussian score model $s_i\sim\mathcal N(μ,σ^2)$ we derive closed-form tail masses and an asymptotic rule for the minimal $k_\varepsilon$ ensuring $\mathrm{TV}(P,\hat P)\le\varepsilon$, namely $k_\varepsilon/n\approxΦ_c(σ+Φ^{-1}(\varepsilon))$. Experiments on bert-base-uncased and synthetic logits confirm the predicted scaling of $k_\varepsilon/n$ and show that certified Top-$k$ can reduce scored keys by 2-4$\times$ on average while meeting the prescribed total-variation budget.
Hierarchical Structure-Property Alignment for Data-Efficient Molecular Generation and Editing
Nov 11, 2025Property-constrained molecular generation and editing are crucial in AI-driven drug discovery but remain hindered by two factors: (i) capturing the complex relationships between molecular structures and multiple properties remains challenging, and (ii) the narrow coverage and incomplete annotations of molecular properties weaken the effectiveness of property-based models. To tackle these limitations, we propose HSPAG, a data-efficient framework featuring hierarchical structure-property alignment. By treating SMILES and molecular properties as complementary modalities, the model learns their relationships at atom, substructure, and whole-molecule levels. Moreover, we select representative samples through scaffold clustering and hard samples via an auxiliary variational auto-encoder (VAE), substantially reducing the required pre-training data. In addition, we incorporate a property relevance-aware masking mechanism and diversified perturbation strategies to enhance generation quality under sparse annotations. Experiments demonstrate that HSPAG captures fine-grained structure-property relationships and supports controllable generation under multiple property constraints. Two real-world case studies further validate the editing capabilities of HSPAG.
Real-Time Network Traffic Forecasting with Missing Data: A Generative Model Approach
Jun 11, 2025Real-time network traffic forecasting is crucial for network management and early resource allocation. Existing network traffic forecasting approaches operate under the assumption that the network traffic data is fully observed. However, in practical scenarios, the collected data are often incomplete due to various human and natural factors. In this paper, we propose a generative model approach for real-time network traffic forecasting with missing data. Firstly, we model the network traffic forecasting task as a tensor completion problem. Secondly, we incorporate a pre-trained generative model to achieve the low-rank structure commonly associated with tensor completion. The generative model effectively captures the intrinsic low-rank structure of network traffic data during pre-training and enables the mapping from a compact latent representation to the tensor space. Thirdly, rather than directly optimizing the high-dimensional tensor, we optimize its latent representation, which simplifies the optimization process and enables real-time forecasting. We also establish a theoretical recovery guarantee that quantifies the error bound of the proposed approach. Experiments on real-world datasets demonstrate that our approach achieves accurate network traffic forecasting within 100 ms, with a mean absolute error (MAE) below 0.002, as validated on the Abilene dataset.
A Lyapunov Drift-Plus-Penalty Method Tailored for Reinforcement Learning with Queue Stability
Jun 04, 2025With the proliferation of Internet of Things (IoT) devices, the demand for addressing complex optimization challenges has intensified. The Lyapunov Drift-Plus-Penalty algorithm is a widely adopted approach for ensuring queue stability, and some research has preliminarily explored its integration with reinforcement learning (RL). In this paper, we investigate the adaptation of the Lyapunov Drift-Plus-Penalty algorithm for RL applications, deriving an effective method for combining Lyapunov Drift-Plus-Penalty with RL under a set of common and reasonable conditions through rigorous theoretical analysis. Unlike existing approaches that directly merge the two frameworks, our proposed algorithm, termed Lyapunov drift-plus-penalty method tailored for reinforcement learning with queue stability (LDPTRLQ) algorithm, offers theoretical superiority by effectively balancing the greedy optimization of Lyapunov Drift-Plus-Penalty with the long-term perspective of RL. Simulation results for multiple problems demonstrate that LDPTRLQ outperforms the baseline methods using the Lyapunov drift-plus-penalty method and RL, corroborating the validity of our theoretical derivations. The results also demonstrate that our proposed algorithm outperforms other benchmarks in terms of compatibility and stability.
EventDiff: A Unified and Efficient Diffusion Model Framework for Event-based Video Frame Interpolation
May 13, 2025



Video Frame Interpolation (VFI) is a fundamental yet challenging task in computer vision, particularly under conditions involving large motion, occlusion, and lighting variation. Recent advancements in event cameras have opened up new opportunities for addressing these challenges. While existing event-based VFI methods have succeeded in recovering large and complex motions by leveraging handcrafted intermediate representations such as optical flow, these designs often compromise high-fidelity image reconstruction under subtle motion scenarios due to their reliance on explicit motion modeling. Meanwhile, diffusion models provide a promising alternative for VFI by reconstructing frames through a denoising process, eliminating the need for explicit motion estimation or warping operations. In this work, we propose EventDiff, a unified and efficient event-based diffusion model framework for VFI. EventDiff features a novel Event-Frame Hybrid AutoEncoder (HAE) equipped with a lightweight Spatial-Temporal Cross Attention (STCA) module that effectively fuses dynamic event streams with static frames. Unlike previous event-based VFI methods, EventDiff performs interpolation directly in the latent space via a denoising diffusion process, making it more robust across diverse and challenging VFI scenarios. Through a two-stage training strategy that first pretrains the HAE and then jointly optimizes it with the diffusion model, our method achieves state-of-the-art performance across multiple synthetic and real-world event VFI datasets. The proposed method outperforms existing state-of-the-art event-based VFI methods by up to 1.98dB in PSNR on Vimeo90K-Triplet and shows superior performance in SNU-FILM tasks with multiple difficulty levels. Compared to the emerging diffusion-based VFI approach, our method achieves up to 5.72dB PSNR gain on Vimeo90K-Triplet and 4.24X faster inference.
Bayesian Test-Time Adaptation for Vision-Language Models
Mar 12, 2025Test-time adaptation with pre-trained vision-language models, such as CLIP, aims to adapt the model to new, potentially out-of-distribution test data. Existing methods calculate the similarity between visual embedding and learnable class embeddings, which are initialized by text embeddings, for zero-shot image classification. In this work, we first analyze this process based on Bayes theorem, and observe that the core factors influencing the final prediction are the likelihood and the prior. However, existing methods essentially focus on adapting class embeddings to adapt likelihood, but they often ignore the importance of prior. To address this gap, we propose a novel approach, \textbf{B}ayesian \textbf{C}lass \textbf{A}daptation (BCA), which in addition to continuously updating class embeddings to adapt likelihood, also uses the posterior of incoming samples to continuously update the prior for each class embedding. This dual updating mechanism allows the model to better adapt to distribution shifts and achieve higher prediction accuracy. Our method not only surpasses existing approaches in terms of performance metrics but also maintains superior inference rates and memory usage, making it highly efficient and practical for real-world applications.
Distance-Forward Learning: Enhancing the Forward-Forward Algorithm Towards High-Performance On-Chip Learning
Aug 27, 2024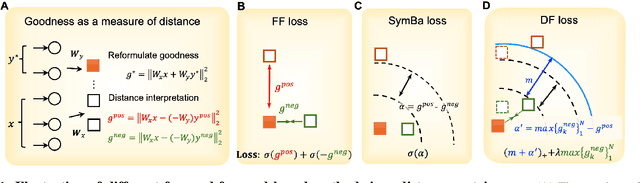

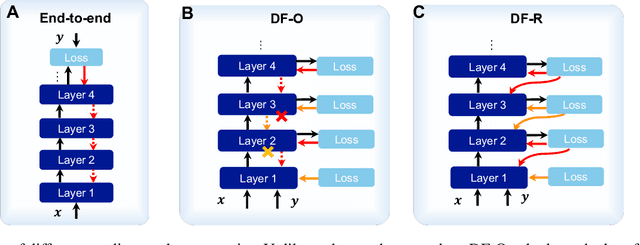

The Forward-Forward (FF) algorithm was recently proposed as a local learning method to address the limitations of backpropagation (BP), offering biological plausibility along with memory-efficient and highly parallelized computational benefits. However, it suffers from suboptimal performance and poor generalization, largely due to inadequate theoretical support and a lack of effective learning strategies. In this work, we reformulate FF using distance metric learning and propose a distance-forward algorithm (DF) to improve FF performance in supervised vision tasks while preserving its local computational properties, making it competitive for efficient on-chip learning. To achieve this, we reinterpret FF through the lens of centroid-based metric learning and develop a goodness-based N-pair margin loss to facilitate the learning of discriminative features. Furthermore, we integrate layer-collaboration local update strategies to reduce information loss caused by greedy local parameter updates. Our method surpasses existing FF models and other advanced local learning approaches, with accuracies of 99.7\% on MNIST, 88.2\% on CIFAR-10, 59\% on CIFAR-100, 95.9\% on SVHN, and 82.5\% on ImageNette, respectively. Moreover, it achieves comparable performance with less than 40\% memory cost compared to BP training, while exhibiting stronger robustness to multiple types of hardware-related noise, demonstrating its potential for online learning and energy-efficient computation on neuromorphic chips.