 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Potential of Spiking Dynamics in Graph Representation Learning through Spatial-Temporal Normalization and Coding Strategies
Jul 30, 2024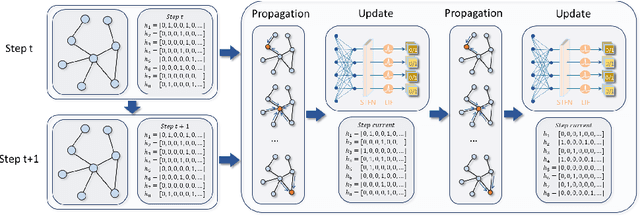

In recent years, spiking neural networks (SNNs) have attracted substantial interest due to their potential to replicate the energy-efficient and event-driven processing of biological neurons. Despite this, the application of SNNs in graph representation learning, particularly for non-Euclidean data, remains underexplored, and the influence of spiking dynamics on graph learning is not yet fully understood. This work seeks to address these gaps by examining the unique properties and benefits of spiking dynamics in enhancing graph representation learning. We propose a spike-based graph neural network model that incorporates spiking dynamics, enhanced by a novel spatial-temporal feature normalization (STFN) technique, to improve training efficiency and model stability. Our detailed analysis explores the impact of rate coding and temporal coding on SNN performance, offering new insights into their advantages for deep graph networks and addressing challenges such as the oversmoothing problem. Experimental results demonstrate that our SNN models can achieve competitive performance with state-of-the-art graph neural networks (GNNs) while considerably reducing computational costs, highlighting the potential of SNNs for efficient neuromorphic computing applications in complex graph-based scenarios.
Enhancing Graph Representation Learning with Attention-Driven Spiking Neural Networks
Mar 25, 2024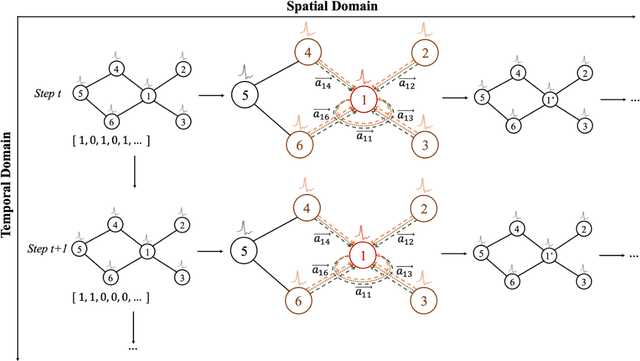
Graph representation learning has become a crucial task in machine learning and data mining due to its potential for modeling complex structures such as social networks, chemical compounds, and biological systems. Spiking neural networks (SNNs) have recently emerged as a promising alternative to traditional neural networks for graph learning tasks, benefiting from their ability to efficiently encode and process temporal and spatial information. In this paper, we propose a novel approach that integrates attention mechanisms with SNNs to improve graph representation learning. Specifically, we introduce an attention mechanism for SNN that can selectively focus on important nodes and corresponding features in a graph during the learning process. We evaluate our proposed method on several benchmark datasets and show that it achieves comparable performance compared to existing graph learning techniques.
Understanding the Functional Roles of Modelling Components in Spiking Neural Networks
Mar 25, 2024Spiking neural networks (SNNs), inspired by the neural circuits of the brain, are promising in achieving high computational efficiency with biological fidelity. Nevertheless, it is quite difficult to optimize SNNs because the functional roles of their modelling components remain unclear. By designing and evaluating several variants of the classic model, we systematically investigate the functional roles of key modelling components, leakage, reset, and recurrence, in leaky integrate-and-fire (LIF) based SNNs. Through extensive experiments, we demonstrate how these components influence the accuracy, generalization, and robustness of SNNs. Specifically, we find that the leakage plays a crucial role in balancing memory retention and robustness, the reset mechanism is essential for uninterrupted temporal processing and computational efficiency, and the recurrence enriches the capability to model complex dynamics at a cost of robustness degradation. With these interesting observations, we provide optimization suggestions for enhancing the performance of SNNs in different scenarios. This work deepens the understanding of how SNNs work, which offers valuable guidance for the development of more effective and robust neuromorphic models.
Exploiting Spiking Dynamics with Spatial-temporal Feature Normalization in Graph Learning
Jun 30, 2021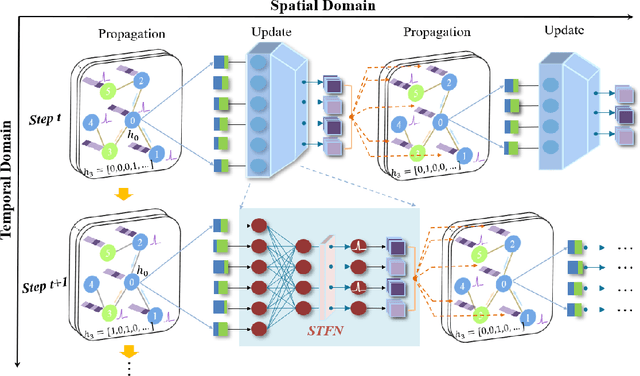
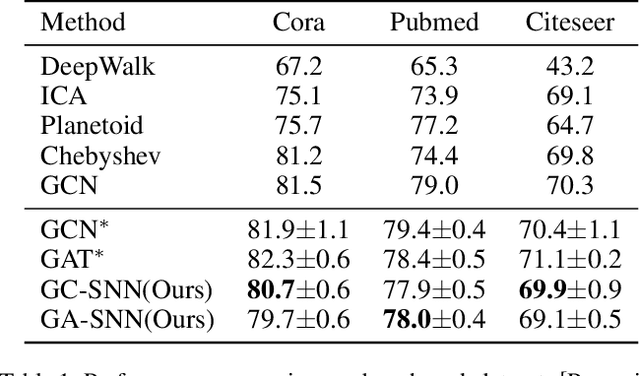
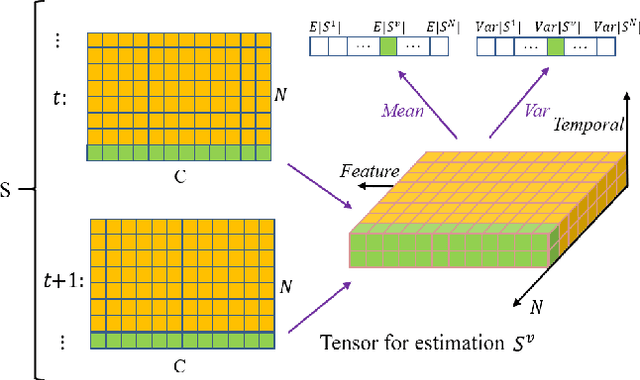
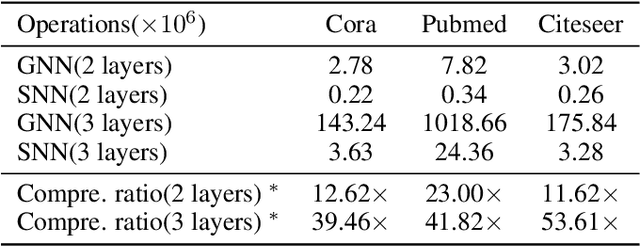
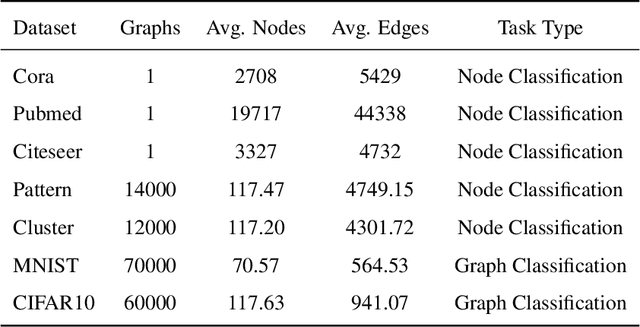
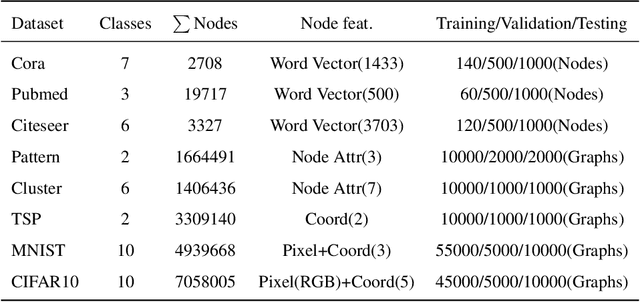
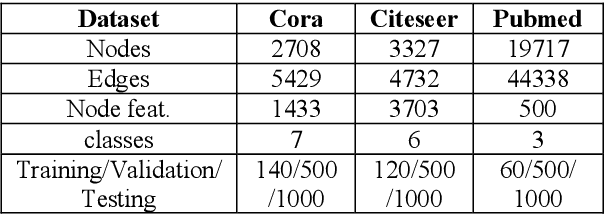
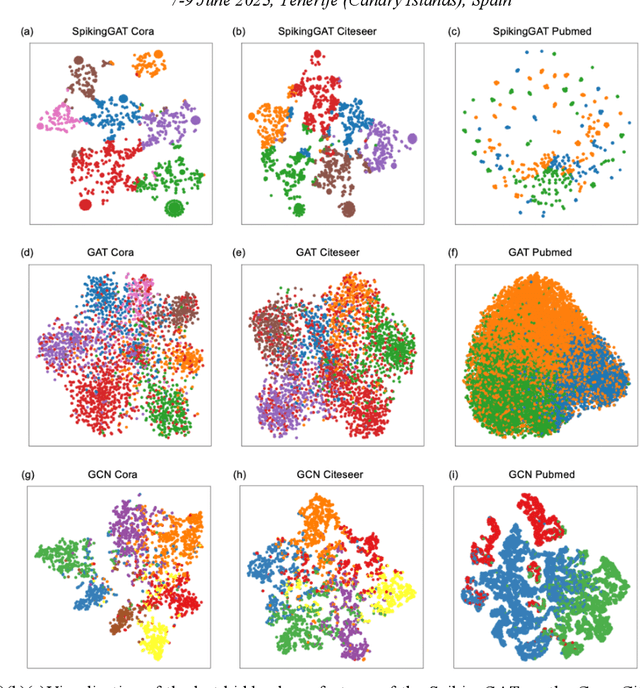
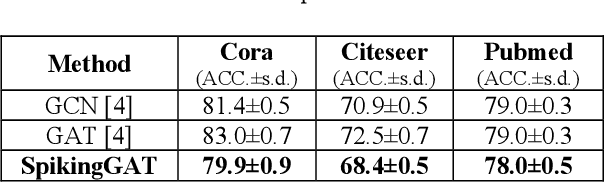
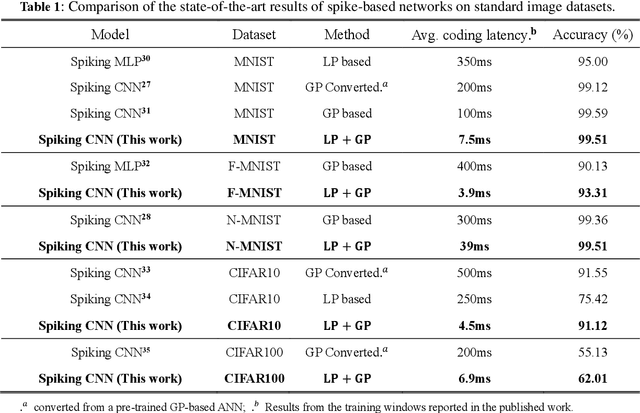
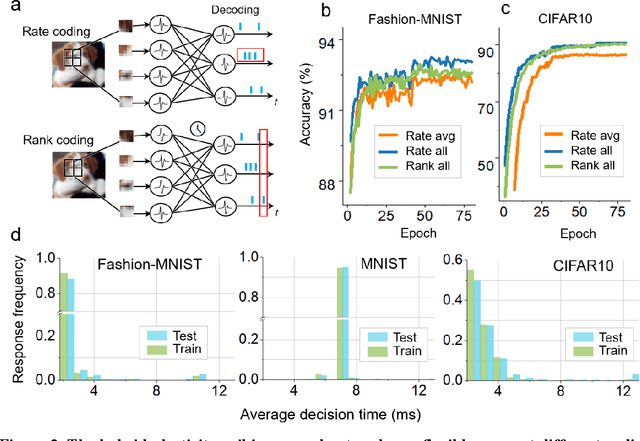
Biological spiking neurons with intrinsic dynamics underlie the powerful representation and learning capabilities of the brain for processing multimodal information in complex environments. Despite recent tremendous progress in spiking neural networks (SNNs) for handling Euclidean-space tasks, it still remains challenging to exploit SNNs in processing non-Euclidean-space data represented by graph data, mainly due to the lack of effective modeling framework and useful training techniques. Here we present a general spike-based modeling framework that enables the direct training of SNNs for graph learning. Through spatial-temporal unfolding for spiking data flows of node features, we incorporate graph convolution filters into spiking dynamics and formalize a synergistic learning paradigm. Considering the unique features of spike representation and spiking dynamics, we propose a spatial-temporal feature normalization (STFN) technique suitable for SNN to accelerate convergence. We instantiate our methods into two spiking graph models, including graph convolution SNNs and graph attention SNNs, and validate their performance on three node-classification benchmarks, including Cora, Citeseer, and Pubmed. Our model can achieve comparable performance with the state-of-the-art graph neural network (GNN) models with much lower computation costs, demonstrating great benefits for the execution on neuromorphic hardware and prompting neuromorphic applications in graphical scenarios.
Brain-inspired global-local hybrid learning towards human-like intelligence
Jun 05, 2020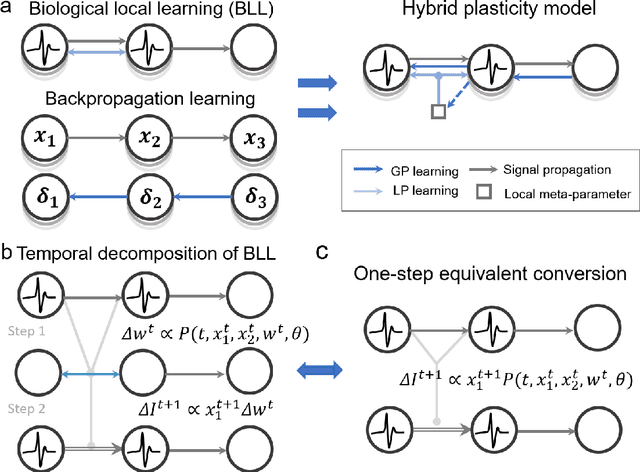
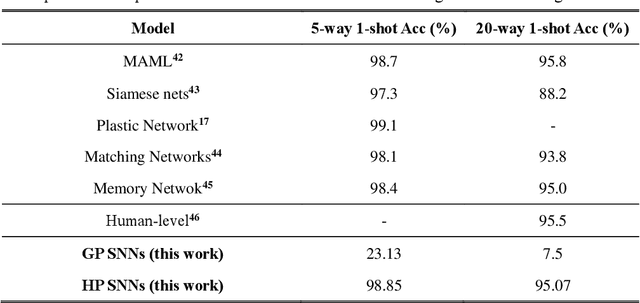
The combination of neuroscience-oriented and computer-science-oriented approaches is the most promising method to develop artificial general intelligence (AGI) that can learn general tasks similar to humans. Currently, two main routes of learning exist, including neuroscience-inspired methods, represented by local synaptic plasticity, and machine-learning methods, represented by backpropagation. Both have advantages and complement each other, but neither can solve all learning problems well. Integrating these two methods into one network may provide better learning abilities for general tasks. Here, we report a hybrid spiking neural network model that integrates the two approaches by introducing a meta-local module and a two-phase causality modelling method. The model can not only optimize local plasticity rules, but also receive top-down supervision information. In addition to flexibly supporting multiple spike-based coding schemes, we demonstrate that this model facilitates learning of many general tasks, including fault-tolerance learning, few-shot learning and multiple-task learning, and show its efficiency on the Tianjic neuromorphic platform. This work provides a new route for brain-inspired computing and facilitates AGI development.
Adversarial symmetric GANs: bridging adversarial samples and adversarial networks
Jan 01, 2020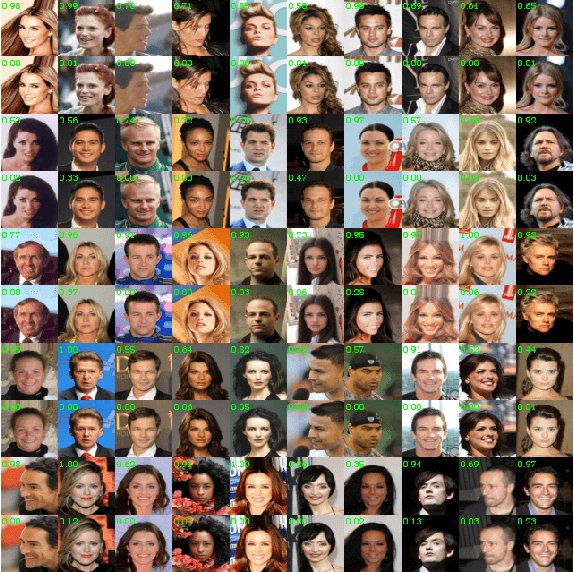
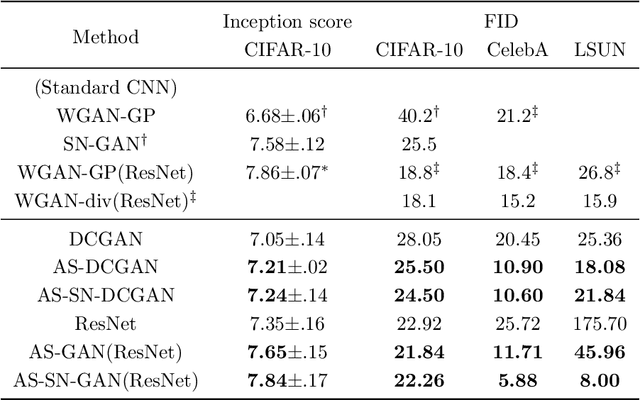


Generative adversarial networks have achieved remarkable performance on various tasks but suffer from training instability. Despite many training strategies proposed to improve training stability, this issue remains as a challenge. In this paper, we investigate the training instability from the perspective of adversarial samples and reveal that adversarial training on fake samples is implemented in vanilla GANs, but adversarial training on real samples has long been overlooked. Consequently, the discriminator is extremely vulnerable to adversarial perturbation and the gradient given by the discriminator contains non-informative adversarial noises, which hinders the generator from catching the pattern of real samples. Here, we develop adversarial symmetric GANs (AS-GANs) that incorporate adversarial training of the discriminator on real samples into vanilla GANs, making adversarial training symmetrical. The discriminator is therefore more robust and provides more informative gradient with less adversarial noise, thereby stabilizing training and accelerating convergence. The effectiveness of the AS-GANs is verified on image generation on CIFAR-10 , CelebA, and LSUN with varied network architectures. Not only the training is more stabilized, but the FID scores of generated samples are consistently improved by a large margin compared to the baseline. The bridging of adversarial samples and adversarial networks provides a new approach to further develop adversarial networks.
Transfer Learning in General Lensless Imaging through Scattering Media
Dec 28, 2019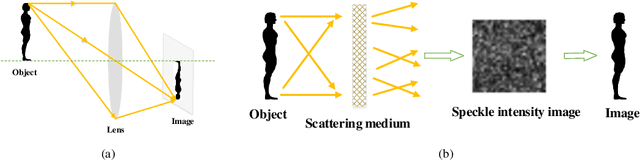
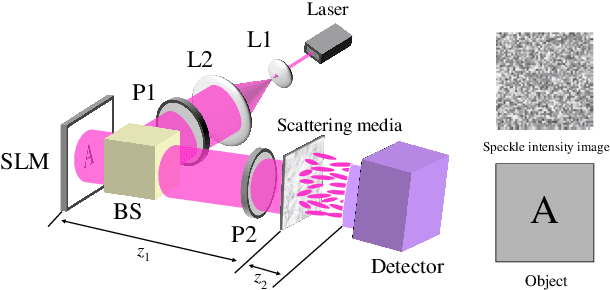
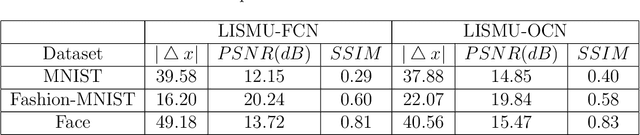

Recently deep neural networks (DNNs) have been successfully introduced to the field of lensless imaging through scattering media. By solving an inverse problem in computational imaging, DNNs can overcome several shortcomings in the conventional lensless imaging through scattering media methods, namely, high cost, poor quality, complex control, and poor anti-interference. However, for training, a large number of training samples on various datasets have to be collected, with a DNN trained on one dataset generally performing poorly for recovering images from another dataset. The underlying reason is that lensless imaging through scattering media is a high dimensional regression problem and it is difficult to obtain an analytical solution. In this work, transfer learning is proposed to address this issue. Our main idea is to train a DNN on a relatively complex dataset using a large number of training samples and fine-tune the last few layers using very few samples from other datasets. Instead of the thousands of samples required to train from scratch, transfer learning alleviates the problem of costly data acquisition. Specifically, considering the difference in sample sizes and similarity among datasets, we propose two DNN architectures, namely LISMU-FCN and LISMU-OCN, and a balance loss function designed for balancing smoothness and sharpness. LISMU-FCN, with much fewer parameters, can achieve imaging across similar datasets while LISMU-OCN can achieve imaging across significantly different datasets. What's more, we establish a set of simulation algorithms which are close to the real experiment, and it is of great significance and practical value in the research on lensless scattering imaging. In summary, this work provides a new solution for lensless imaging through scattering media using transfer learning in DNNs.
GXNOR-Net: Training deep neural networks with ternary weights and activations without full-precision memory under a unified discretization framework
May 02, 2018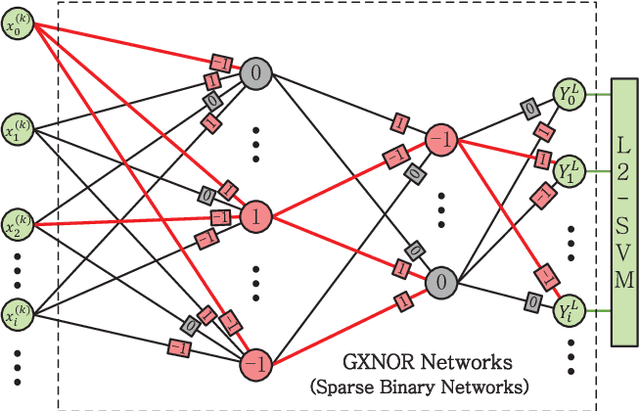
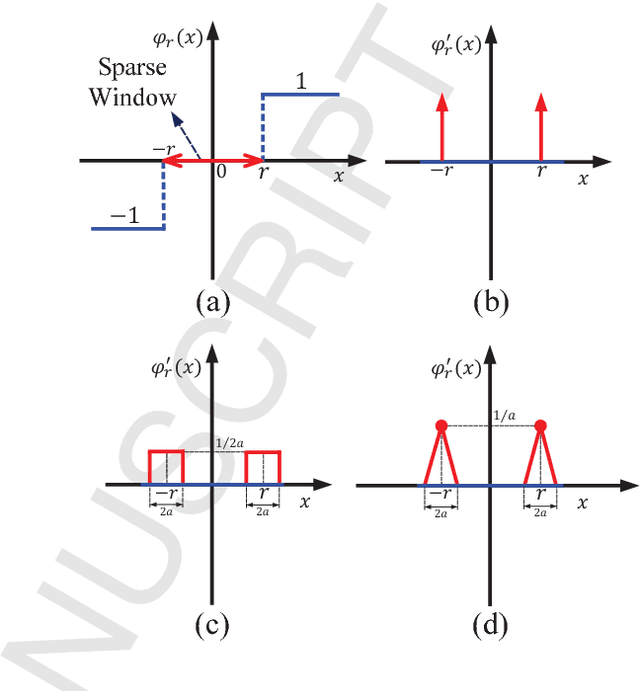
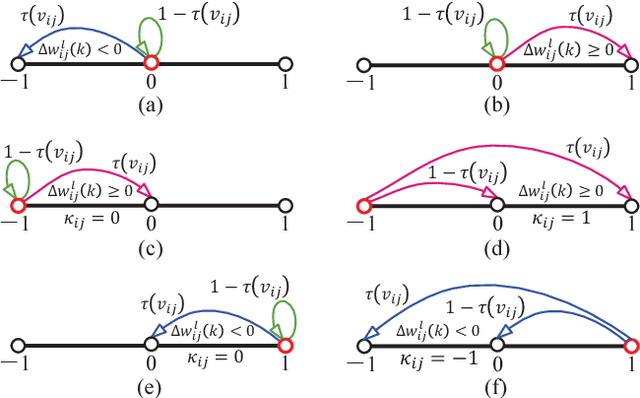
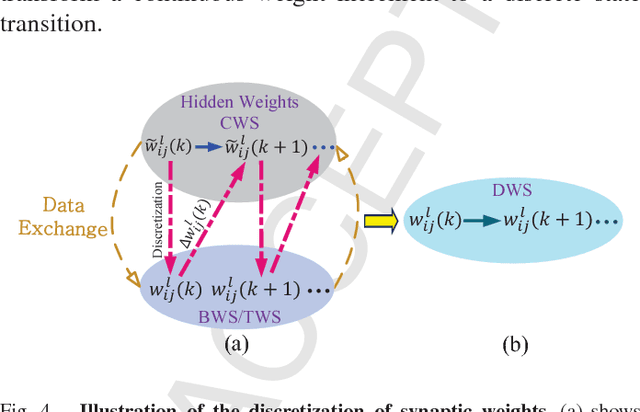
There is a pressing need to build an architecture that could subsume these networks under a unified framework that achieves both higher performance and less overhead. To this end, two fundamental issues are yet to be addressed. The first one is how to implement the back propagation when neuronal activations are discrete. The second one is how to remove the full-precision hidden weights in the training phase to break the bottlenecks of memory/computation consumption. To address the first issue, we present a multi-step neuronal activation discretization method and a derivative approximation technique that enable the implementing the back propagation algorithm on discrete DNNs. While for the second issue, we propose a discrete state transition (DST) methodology to constrain the weights in a discrete space without saving the hidden weights. Through this way, we build a unified framework that subsumes the binary or ternary networks as its special cases, and under which a heuristic algorithm is provided at the website https://github.com/AcrossV/Gated-XNOR. More particularly, we find that when both the weights and activations become ternary values, the DNNs can be reduced to sparse binary networks, termed as gated XNOR networks (GXNOR-Nets) since only the event of non-zero weight and non-zero activation enables the control gate to start the XNOR logic operations in the original binary networks. This promises the event-driven hardware design for efficient mobile intelligence. We achieve advanced performance compared with state-of-the-art algorithms. Furthermore, the computational sparsity and the number of states in the discrete space can be flexibly modified to make it suitable for various hardware platforms.
* 11 pages, 13 figures