 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSAINet: An Efficient Dual-Scale Attentive Interaction Network for General EEG Decoding
Apr 20, 2026In real-world applications of noninvasive electroencephalography (EEG), specialized decoders often show limited generalizability across diverse tasks under subject-independent settings. One central challenge is that task-relevant EEG signals often follow different temporal organization patterns across tasks, while many existing methods rely on task-tailored architectural designs that introduce task-specific temporal inductive biases. This mismatch makes it difficult to adapt temporal modeling across tasks without changing the model configuration. To address these challenges, we propose DSAINet, an efficient dual-scale attentive interaction network for general EEG decoding. Specifically, DSAINet constructs shared spatiotemporal token representations from raw EEG signals and models diverse temporal dynamics through parallel convolutional branches at fine and coarse scales. The resulting representations are then adaptively refined by intra-branch attention to emphasize salient scale-specific patterns and by inter-branch attention to integrate task-relevant features across scales, followed by adaptive token aggregation to yield a compact representation for prediction. Extensive experiments on five downstream EEG decoding tasks across ten public datasets show that DSAINet consistently outperforms 13 representative baselines under strict subject-independent evaluation. Notably, this performance is achieved using the same architecture hyperparameters across datasets. Moreover, DSAINet achieves a favorable accuracy-efficiency trade-off with only about 77K trainable parameters and provides interpretable neurophysiological insights. The code is publicly available at https://github.com/zy0929/DSAINet.
Dual-Enhancement Product Bundling: Bridging Interactive Graph and Large Language Model
Apr 15, 2026Product bundling boosts e-commerce revenue by recommending complementary item combinations. However, existing methods face two critical challenges: (1) collaborative filtering approaches struggle with cold-start items owing to dependency on historical interactions, and (2) LLMs lack inherent capability to model interactive graph directly. To bridge this gap, we propose a dual-enhancement method that integrates interactive graph learning and LLM-based semantic understanding for product bundling. Our method introduces a graph-to-text paradigm, which leverages a Dynamic Concept Binding Mechanism (DCBM) to translate graph structures into natural language prompts. The DCBM plays a critical role in aligning domain-specific entities with LLM tokenization, enabling effective comprehension of combinatorial constraints. Experiments on three benchmarks (POG, POG_dense, Steam) demonstrate 6.3%-26.5% improvements over state-of-the-art baselines.
LI-DSN: A Layer-wise Interactive Dual-Stream Network for EEG Decoding
Apr 02, 2026Electroencephalography (EEG) provides a non-invasive window into brain activity, offering high temporal resolution crucial for understanding and interacting with neural processes through brain-computer interfaces (BCIs). Current dual-stream neural networks for EEG often process temporal and spatial features independently through parallel branches, delaying their integration until a final, late-stage fusion. This design inherently leads to an "information silo" problem, precluding intermediate cross-stream refinement and hindering spatial-temporal decompositions essential for full feature utilization. We propose LI-DSN, a layer-wise interactive dual-stream network that facilitates progressive, cross-stream communication at each layer, thereby overcoming the limitations of late-fusion paradigms. LI-DSN introduces a novel Temporal-Spatial Integration Attention (TSIA) mechanism, which constructs a Spatial Affinity Correlation Matrix (SACM) to capture inter-electrode spatial structural relationships and a Temporal Channel Aggregation Matrix (TCAM) to integrate cosine-gated temporal dynamics under spatial guidance. Furthermore, we employ an adaptive fusion strategy with learnable channel weights to optimize the integration of dual-stream features. Extensive experiments across eight diverse EEG datasets, encompassing motor imagery (MI) classification, emotion recognition, and steady-state visual evoked potentials (SSVEP), consistently demonstrate that LI-DSN significantly outperforms 13 state-of-the-art (SOTA) baseline models, showcasing its superior robustness and decoding performance. The code will be publicized after acceptance.
CRCC: Contrast-Based Robust Cross-Subject and Cross-Site Representation Learning for EEG
Feb 22, 2026EEG-based neural decoding models often fail to generalize across acquisition sites due to structured, site-dependent biases implicitly exploited during training. We reformulate cross-site clinical EEG learning as a bias-factorized generalization problem, in which domain shifts arise from multiple interacting sources. We identify three fundamental bias factors and propose a general training framework that mitigates their influence through data standardization and representation-level constraints. We construct a standardized multi-site EEG benchmark for Major Depressive Disorder and introduce CRCC, a two-stage training paradigm combining encoder-decoder pretraining with joint fine-tuning via cross-subject/site contrastive learning and site-adversarial optimization. CRCC consistently outperforms state-of-the-art baselines and achieves a 10.7 percentage-point improvement in balanced accuracy under strict zero-shot site transfer, demonstrating robust generalization to unseen environments.
Training-Driven Representational Geometry Modularization Predicts Brain Alignment in Language Models
Feb 07, 2026How large language models (LLMs) align with the neural representation and computation of human language is a central question in cognitive science. Using representational geometry as a mechanistic lens, we addressed this by tracking entropy, curvature, and fMRI encoding scores throughout Pythia (70M-1B) training. We identified a geometric modularization where layers self-organize into stable low- and high-complexity clusters. The low-complexity module, characterized by reduced entropy and curvature, consistently better predicted human language network activity. This alignment followed heterogeneous spatial-temporal trajectories: rapid and stable in temporal regions (AntTemp, PostTemp), but delayed and dynamic in frontal areas (IFG, IFGorb). Crucially, reduced curvature remained a robust predictor of model-brain alignment even after controlling for training progress, an effect that strengthened with model scale. These results links training-driven geometric reorganization to temporal-frontal functional specialization, suggesting that representational smoothing facilitates neural-like linguistic processing.
Signal-Adaptive Trust Regions for Gradient-Free Optimization of Recurrent Spiking Neural Networks
Jan 29, 2026Recurrent spiking neural networks (RSNNs) are a promising substrate for energy-efficient control policies, but training them for high-dimensional, long-horizon reinforcement learning remains challenging. Population-based, gradient-free optimization circumvents backpropagation through non-differentiable spike dynamics by estimating gradients. However, with finite populations, high variance of these estimates can induce harmful and overly aggressive update steps. Inspired by trust-region methods in reinforcement learning that constrain policy updates in distribution space, we propose \textbf{Signal-Adaptive Trust Regions (SATR)}, a distributional update rule that constrains relative change by bounding KL divergence normalized by an estimated signal energy. SATR automatically expands the trust region under strong signals and contracts it when updates are noise-dominated. We instantiate SATR for Bernoulli connectivity distributions, which have shown strong empirical performance for RSNN optimization. Across a suite of high-dimensional continuous-control benchmarks, SATR improves stability under limited populations and reaches competitive returns against strong baselines including PPO-LSTM. In addition, to make SATR practical at scale, we introduce a bitset implementation for binary spiking and binary weights, substantially reducing wall-clock training time and enabling fast RSNN policy search.
Improve Decoding Factuality by Token-wise Cross Layer Entropy of Large Language Models
Feb 05, 2025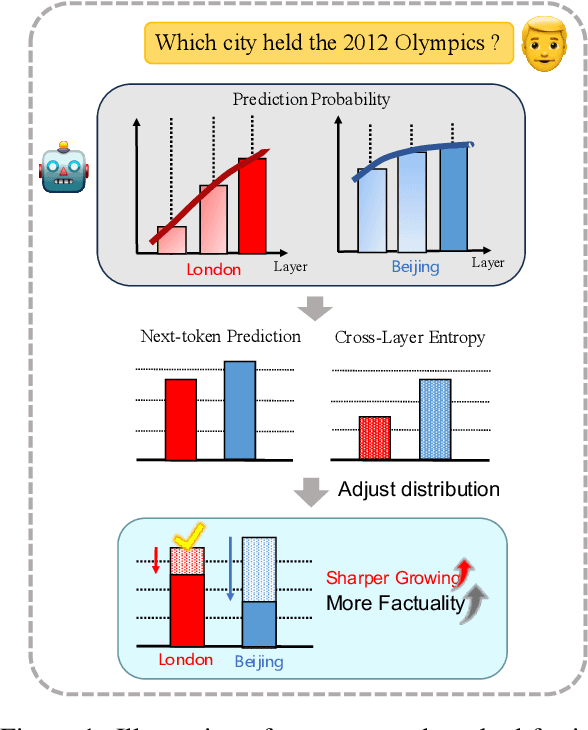
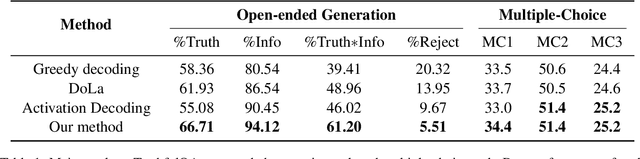
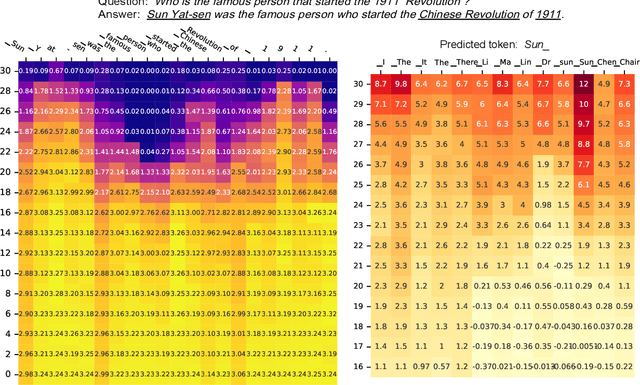
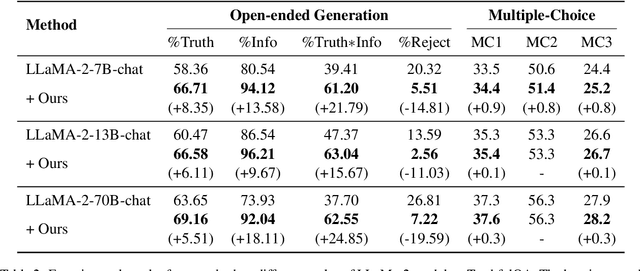
Despite their impressive capacities, Large language models (LLMs) often struggle with the hallucination issue of generating inaccurate or fabricated content even when they possess correct knowledge. In this paper, we extend the exploration of the correlation between hidden-state prediction changes and output factuality into a deeper, token-wise level. Based on the insights , we propose cross-layer Entropy eNhanced Decoding (END), a decoding method that mitigates hallucinations without requiring extra training. END leverages inner probability changes across layers to individually quantify the factual knowledge required for each candidate token, and adjusts the final predicting distribution to prioritize tokens with higher factuality. Experiments on both hallucination and QA benchmarks demonstrate that END significantly enhances the truthfulness and informativeness of generated content while maintaining robust QA accuracy. Moreover, our work provides a deeper perspective on understanding the correlations between inherent knowledge and output factuality.
Dynamic-Attention-based EEG State Transition Modeling for Emotion Recognition
Nov 07, 2024



Electroencephalogram (EEG)-based emotion decoding can objectively quantify people's emotional state and has broad application prospects in human-computer interaction and early detection of emotional disorders. Recently emerging deep learning architectures have significantly improved the performance of EEG emotion decoding. However, existing methods still fall short of fully capturing the complex spatiotemporal dynamics of neural signals, which are crucial for representing emotion processing. This study proposes a Dynamic-Attention-based EEG State Transition (DAEST) modeling method to characterize EEG spatiotemporal dynamics. The model extracts spatiotemporal components of EEG that represent multiple parallel neural processes and estimates dynamic attention weights on these components to capture transitions in brain states. The model is optimized within a contrastive learning framework for cross-subject emotion recognition. The proposed method achieved state-of-the-art performance on three publicly available datasets: FACED, SEED, and SEED-V. It achieved 75.4% accuracy in the binary classification of positive and negative emotions and 59.3% in nine-class discrete emotion classification on the FACED dataset, 88.1% in the three-class classification of positive, negative, and neutral emotions on the SEED dataset, and 73.6% in five-class discrete emotion classification on the SEED-V dataset. The learned EEG spatiotemporal patterns and dynamic transition properties offer valuable insights into neural dynamics underlying emotion processing.
Contrastive Learning of Shared Spatiotemporal EEG Representations Across Individuals for Naturalistic Neuroscience
Feb 22, 2024



Neural representations induced by naturalistic stimuli offer insights into how humans respond to peripheral stimuli in daily life. The key to understanding the general neural mechanisms underlying naturalistic stimuli processing involves aligning neural activities across individuals and extracting inter-subject shared neural representations. Targeting the Electroencephalogram (EEG) technique, known for its rich spatial and temporal information, this study presents a general framework for Contrastive Learning of Shared SpatioTemporal EEG Representations across individuals (CL-SSTER). Harnessing the representational capabilities of contrastive learning, CL-SSTER utilizes a neural network to maximize the similarity of EEG representations across individuals for identical stimuli, contrasting with those for varied stimuli. The network employed spatial and temporal convolutions to simultaneously learn the spatial and temporal patterns inherent in EEG. The versatility of CL-SSTER was demonstrated on three EEG datasets, including a synthetic dataset, a speech audio EEG dataset, and an emotional video EEG dataset. CL-SSTER attained the highest inter-subject correlation (ISC) values compared to the state-of-the-art ISC methods. The latent representations generated by CL-SSTER exhibited reliable spatiotemporal EEG patterns, which can be explained by specific aspects of the stimuli. CL-SSTER serves as an interpretable and scalable foundational framework for the identification of inter-subject shared neural representations in the realm of naturalistic neuroscience.
UniMem: Towards a Unified View of Long-Context Large Language Models
Feb 05, 2024



Long-context processing is a critical ability that constrains the applicability of large language models. Although there exist various methods devoted to enhancing the long-context processing ability of large language models (LLMs), they are developed in an isolated manner and lack systematic analysis and integration of their strengths, hindering further developments. In this paper, we introduce UniMem, a unified framework that reformulates existing long-context methods from the view of memory augmentation of LLMs. UniMem is characterized by four key dimensions: Memory Management, Memory Writing, Memory Reading, and Memory Injection, providing a systematic theory for understanding various long-context methods. We reformulate 16 existing methods based on UniMem and analyze four representative methods: Transformer-XL, Memorizing Transformer, RMT, and Longformer into equivalent UniMem forms to reveal their design principles and strengths. Based on these analyses, we propose UniMix, an innovative approach that integrates the strengths of these algorithms. Experimental results show that UniMix achieves superior performance in handling long contexts with significantly lower perplexity than baselines.