 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Oriented Retrieval Tuner
Mar 04, 2024



Dense Retrieval (DR) is now considered as a promising tool to enhance the memorization capacity of Large Language Models (LLM) such as GPT3 and GPT-4 by incorporating external memories. However, due to the paradigm discrepancy between text generation of LLM and DR, it is still an open challenge to integrate the retrieval and generation tasks in a shared LLM. In this paper, we propose an efficient LLM-Oriented Retrieval Tuner, namely LMORT, which decouples DR capacity from base LLM and non-invasively coordinates the optimally aligned and uniform layers of the LLM towards a unified DR space, achieving an efficient and effective DR without tuning the LLM itself. The extensive experiments on six BEIR datasets show that our approach could achieve competitive zero-shot retrieval performance compared to a range of strong DR models while maintaining the generation ability of LLM.
UniMem: Towards a Unified View of Long-Context Large Language Models
Feb 05, 2024



Long-context processing is a critical ability that constrains the applicability of large language models. Although there exist various methods devoted to enhancing the long-context processing ability of large language models (LLMs), they are developed in an isolated manner and lack systematic analysis and integration of their strengths, hindering further developments. In this paper, we introduce UniMem, a unified framework that reformulates existing long-context methods from the view of memory augmentation of LLMs. UniMem is characterized by four key dimensions: Memory Management, Memory Writing, Memory Reading, and Memory Injection, providing a systematic theory for understanding various long-context methods. We reformulate 16 existing methods based on UniMem and analyze four representative methods: Transformer-XL, Memorizing Transformer, RMT, and Longformer into equivalent UniMem forms to reveal their design principles and strengths. Based on these analyses, we propose UniMix, an innovative approach that integrates the strengths of these algorithms. Experimental results show that UniMix achieves superior performance in handling long contexts with significantly lower perplexity than baselines.
Rethinking Dense Retrieval's Few-Shot Ability
Apr 12, 2023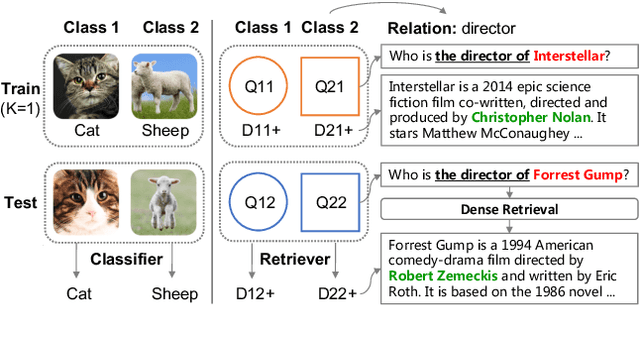
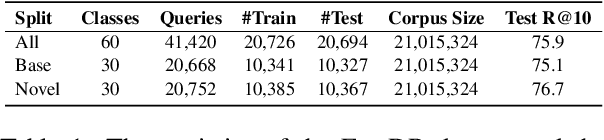

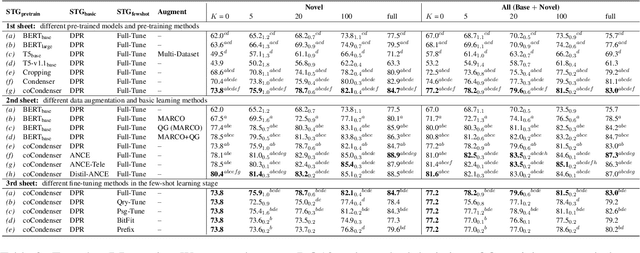
Few-shot dense retrieval (DR) aims to effectively generalize to novel search scenarios by learning a few samples. Despite its importance, there is little study on specialized datasets and standardized evaluation protocols. As a result, current methods often resort to random sampling from supervised datasets to create "few-data" setups and employ inconsistent training strategies during evaluations, which poses a challenge in accurately comparing recent progress. In this paper, we propose a customized FewDR dataset and a unified evaluation benchmark. Specifically, FewDR employs class-wise sampling to establish a standardized "few-shot" setting with finely-defined classes, reducing variability in multiple sampling rounds. Moreover, the dataset is disjointed into base and novel classes, allowing DR models to be continuously trained on ample data from base classes and a few samples in novel classes. This benchmark eliminates the risk of novel class leakage, providing a reliable estimation of the DR model's few-shot ability. Our extensive empirical results reveal that current state-of-the-art DR models still face challenges in the standard few-shot scene. Our code and data will be open-sourced at https://github.com/OpenMatch/ANCE-Tele.
Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives
Oct 31, 2022



In this paper, we investigate the instability in the standard dense retrieval training, which iterates between model training and hard negative selection using the being-trained model. We show the catastrophic forgetting phenomena behind the training instability, where models learn and forget different negative groups during training iterations. We then propose ANCE-Tele, which accumulates momentum negatives from past iterations and approximates future iterations using lookahead negatives, as "teleportations" along the time axis to smooth the learning process. On web search and OpenQA, ANCE-Tele outperforms previous state-of-the-art systems of similar size, eliminates the dependency on sparse retrieval negatives, and is competitive among systems using significantly more (50x) parameters. Our analysis demonstrates that teleportation negatives reduce catastrophic forgetting and improve convergence speed for dense retrieval training. Our code is available at https://github.com/OpenMatch/ANCE-Tele.
COCO-DR: Combating Distribution Shifts in Zero-Shot Dense Retrieval with Contrastive and Distributionally Robust Learning
Oct 27, 2022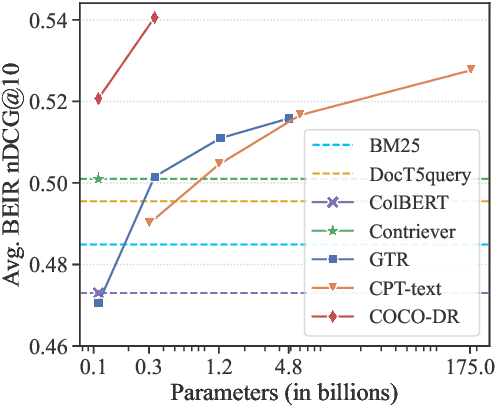
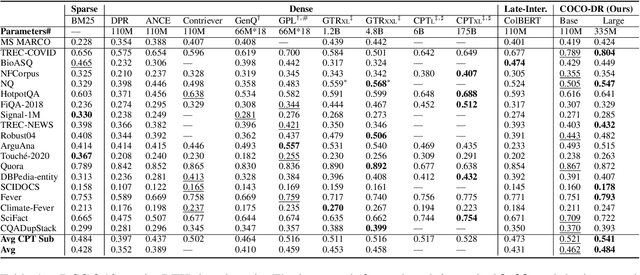
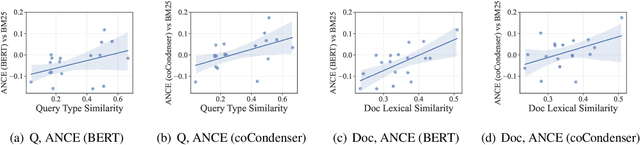
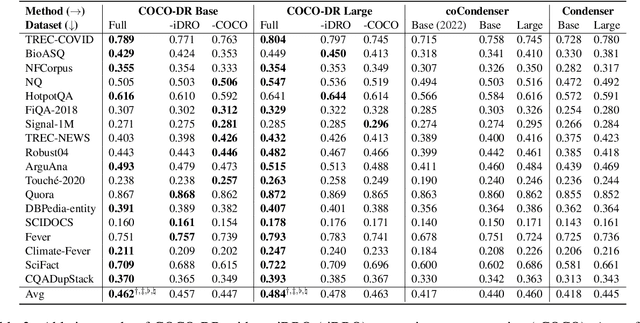
We present a new zero-shot dense retrieval (ZeroDR) method, COCO-DR, to improve the generalization ability of dense retrieval by combating the distribution shifts between source training tasks and target scenarios. To mitigate the impact of document differences, COCO-DR continues pretraining the language model on the target corpora to adapt the model to target distributions via COtinuous COtrastive learning. To prepare for unseen target queries, COCO-DR leverages implicit Distributionally Robust Optimization (iDRO) to reweight samples from different source query clusters for improving model robustness over rare queries during fine-tuning. COCO-DR achieves superior average performance on BEIR, the zero-shot retrieval benchmark. At BERT Base scale, COCO-DR Base outperforms other ZeroDR models with 60x larger size. At BERT Large scale, COCO-DR Large outperforms the giant GPT-3 embedding model which has 500x more parameters. Our analysis show the correlation between COCO-DR's effectiveness in combating distribution shifts and improving zero-shot accuracy. Our code and model can be found at \url{https://github.com/OpenMatch/COCO-DR}.
* EMNLP 2022 Main Conference (Code and Model can be found at https://github.com/OpenMatch/COCO-DR)
Meta Adaptive Neural Ranking with Contrastive Synthetic Supervision
Dec 29, 2020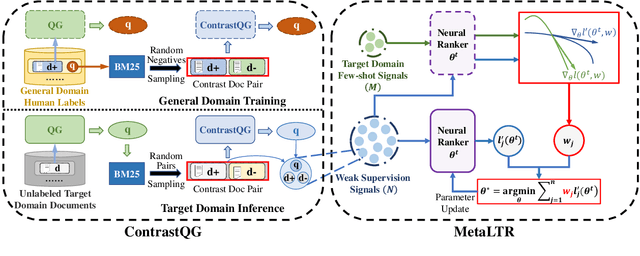

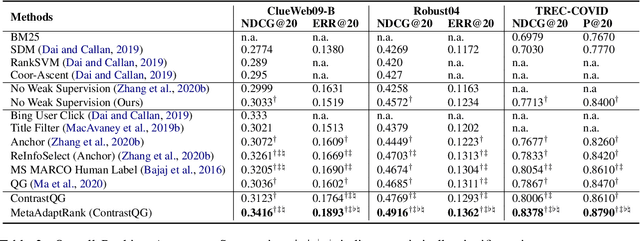
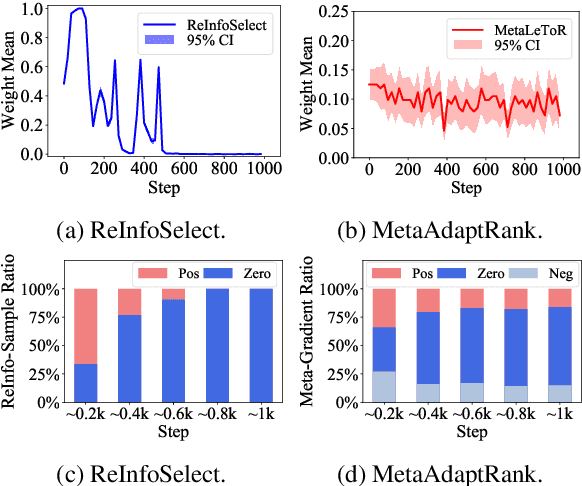
Neural Information Retrieval (Neu-IR) models have shown their effectiveness and thrive from end-to-end training with massive high-quality relevance labels. Nevertheless, relevance labels at such quantity are luxury and unavailable in many ranking scenarios, for example, in biomedical search. This paper improves Neu-IR in such few-shot search scenarios by meta-adaptively training neural rankers with synthetic weak supervision. We first leverage contrastive query generation (ContrastQG) to synthesize more informative queries as in-domain weak relevance labels, and then filter them with meta adaptive learning to rank (MetaLTR) to better generalize neural rankers to the target few-shot domain. Experiments on three different search domains: web, news, and biomedical, demonstrate significantly improved few-shot accuracy of neural rankers with our weak supervision framework. The code of this paper will be open-sourced.
CMT in TREC-COVID Round 2: Mitigating the Generalization Gaps from Web to Special Domain Search
Nov 03, 2020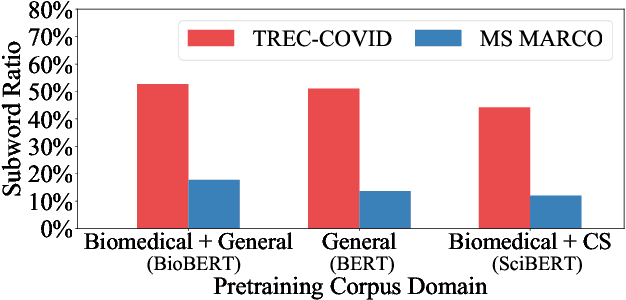

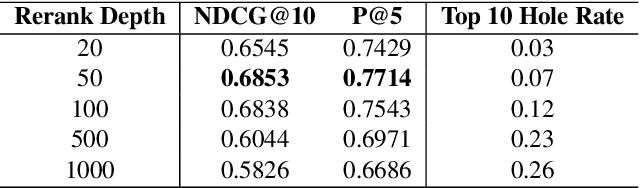
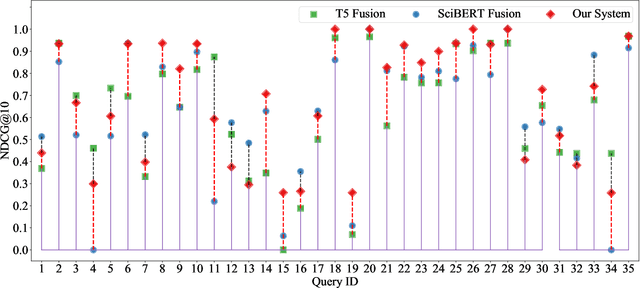
Neural rankers based on deep pretrained language models (LMs) have been shown to improve many information retrieval benchmarks. However, these methods are affected by their the correlation between pretraining domain and target domain and rely on massive fine-tuning relevance labels. Directly applying pretraining methods to specific domains may result in suboptimal search quality because specific domains may have domain adaption problems, such as the COVID domain. This paper presents a search system to alleviate the special domain adaption problem. The system utilizes the domain-adaptive pretraining and few-shot learning technologies to help neural rankers mitigate the domain discrepancy and label scarcity problems. Besides, we also integrate dense retrieval to alleviate traditional sparse retrieval's vocabulary mismatch obstacle. Our system performs the best among the non-manual runs in Round 2 of the TREC-COVID task, which aims to retrieve useful information from scientific literature related to COVID-19. Our code is publicly available at https://github.com/thunlp/OpenMatch.
Joint Keyphrase Chunking and Salience Ranking with BERT
Apr 28, 2020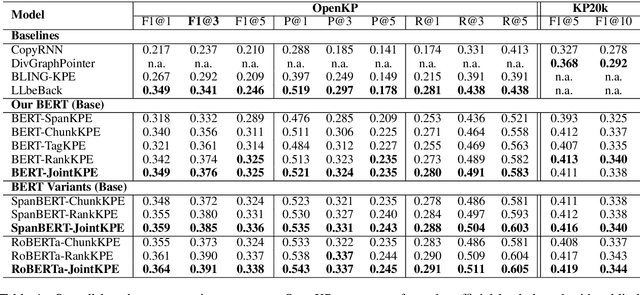
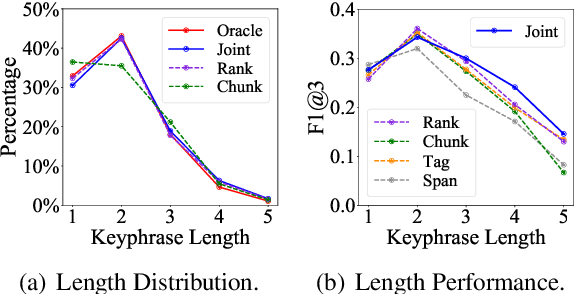
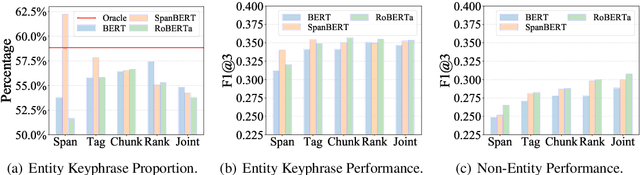
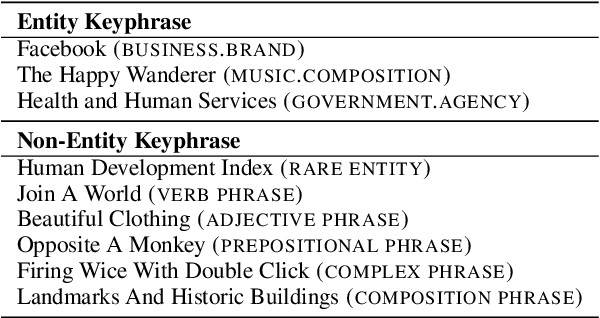
An effective keyphrase extraction system requires to produce self-contained high quality phrases that are also key to the document topic. This paper presents BERT-JointKPE, a multi-task BERT-based model for keyphrase extraction. JointKPE employs a chunking network to identify high-quality phrases and a ranking network to learn their salience in the document. The model is trained jointly on the chunking task and the ranking task, balancing the estimation of keyphrase quality and salience. Experiments on two benchmarks demonstrate JointKPE's robust effectiveness with different BERT variants. Our analyses show that JointKPE has advantages in predicting long keyphrases and extracting phrases that are not entities but also meaningful. The source code of this paper can be obtained from https://github.com/thunlp/BERT-KPE