 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMatch: An Open-Source Package for Information Retrieval
Feb 04, 2021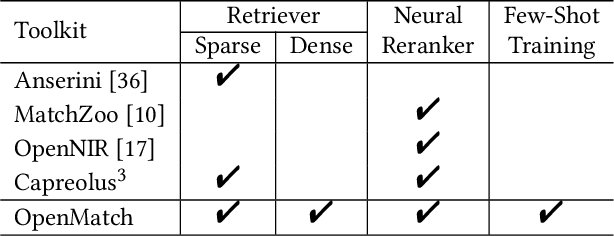
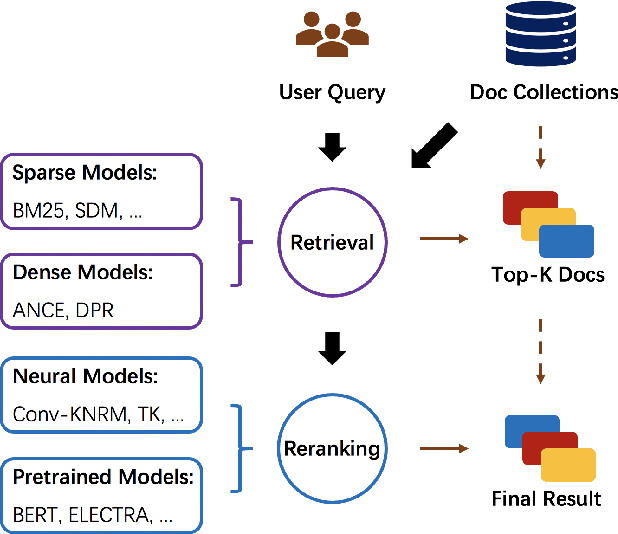
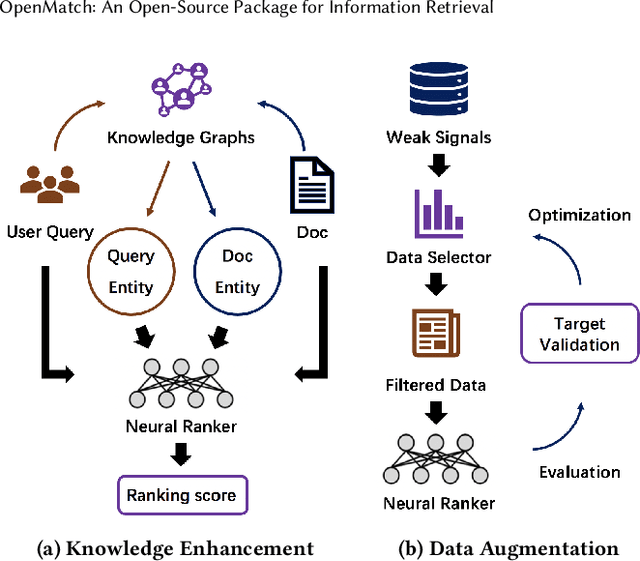
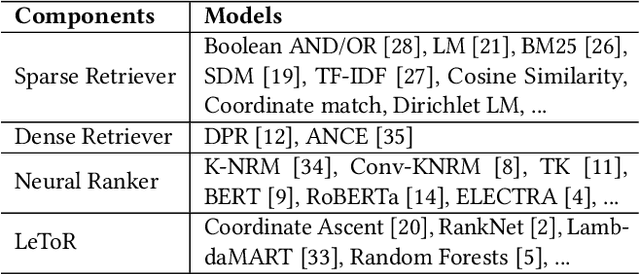
Information Retrieval (IR) is an important task and can be used in many applications. Neural IR (Neu-IR) models overcome the vocabulary mismatch problem of sparse retrievers and thrive on the ranking pipeline with semantic matching. Recent progress in IR mainly focuses on Neu-IR models, including efficient dense retrieval, advanced neural architectures and robustly training for few-shot IR that lacks training data. In order to integrate these advantages for researchers and engineers to utilize and develop, OpenMatch provides various functional neural modules based on PyTorch to maintain sufficient extensibility, making it easy to build customized and higher-capacity IR systems. Besides, OpenMatch consists of complicated optimization tricks, various sparse/dense retrieval methods, and advanced few-shot training methods, liberating users from surplus labor in baseline reimplementation and neural model finetuning. With OpenMatch, we achieve reasonable performance on various ranking datasets, rank first of the automatic group in TREC COVID (Round 2) and rank top on the MS MARCO Document Ranking leaderboard. The library, experimental methodologies and results of OpenMatch are all publicly available at https://github.com/thunlp/OpenMatch.
Meta Adaptive Neural Ranking with Contrastive Synthetic Supervision
Dec 29, 2020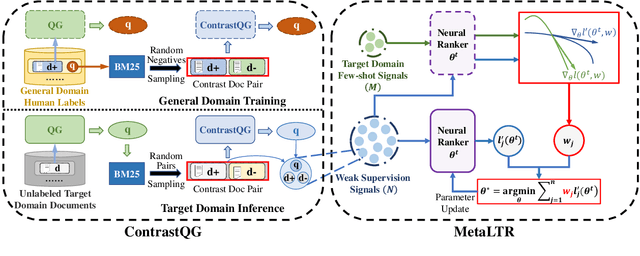

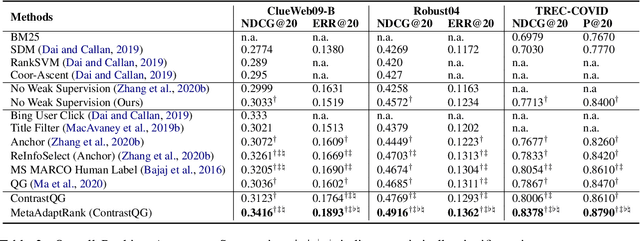
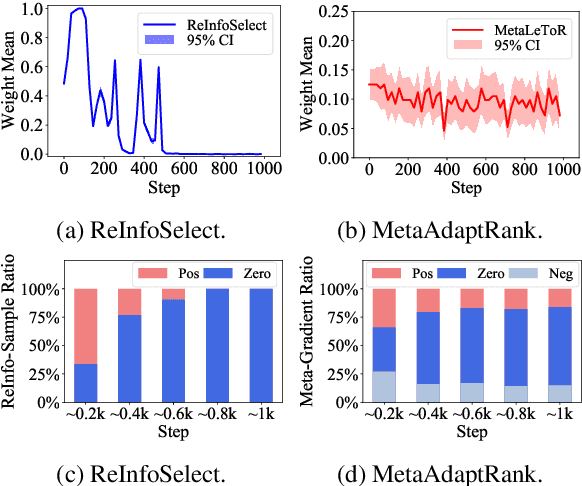
Neural Information Retrieval (Neu-IR) models have shown their effectiveness and thrive from end-to-end training with massive high-quality relevance labels. Nevertheless, relevance labels at such quantity are luxury and unavailable in many ranking scenarios, for example, in biomedical search. This paper improves Neu-IR in such few-shot search scenarios by meta-adaptively training neural rankers with synthetic weak supervision. We first leverage contrastive query generation (ContrastQG) to synthesize more informative queries as in-domain weak relevance labels, and then filter them with meta adaptive learning to rank (MetaLTR) to better generalize neural rankers to the target few-shot domain. Experiments on three different search domains: web, news, and biomedical, demonstrate significantly improved few-shot accuracy of neural rankers with our weak supervision framework. The code of this paper will be open-sourced.
CMT in TREC-COVID Round 2: Mitigating the Generalization Gaps from Web to Special Domain Search
Nov 03, 2020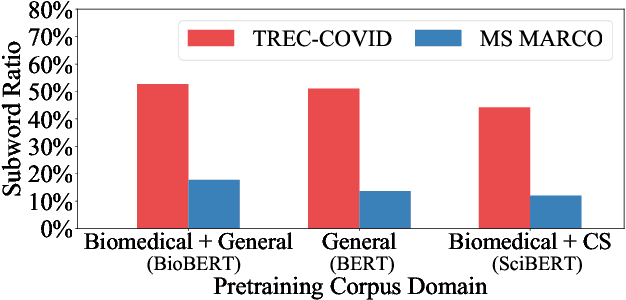

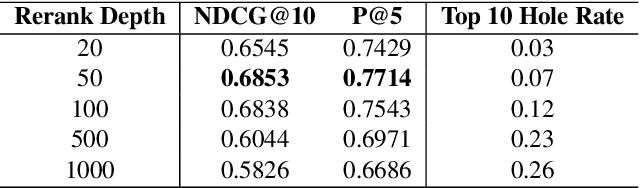
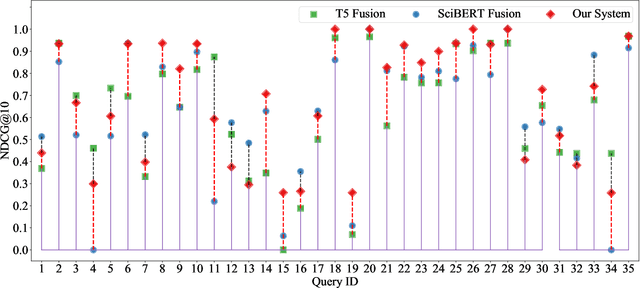
Neural rankers based on deep pretrained language models (LMs) have been shown to improve many information retrieval benchmarks. However, these methods are affected by their the correlation between pretraining domain and target domain and rely on massive fine-tuning relevance labels. Directly applying pretraining methods to specific domains may result in suboptimal search quality because specific domains may have domain adaption problems, such as the COVID domain. This paper presents a search system to alleviate the special domain adaption problem. The system utilizes the domain-adaptive pretraining and few-shot learning technologies to help neural rankers mitigate the domain discrepancy and label scarcity problems. Besides, we also integrate dense retrieval to alleviate traditional sparse retrieval's vocabulary mismatch obstacle. Our system performs the best among the non-manual runs in Round 2 of the TREC-COVID task, which aims to retrieve useful information from scientific literature related to COVID-19. Our code is publicly available at https://github.com/thunlp/OpenMatch.