 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
Feb 04, 2026Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent-subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.
ConsRec: Denoising Sequential Recommendation through User-Consistent Preference Modeling
May 28, 2025User-item interaction histories are pivotal for sequential recommendation systems but often include noise, such as unintended clicks or actions that fail to reflect genuine user preferences. To address this issue, we propose the User-Consistent Preference-based Sequential Recommendation System (ConsRec), designed to capture stable user preferences and filter noisy items from interaction histories. Specifically, ConsRec constructs a user-interacted item graph, learns item similarities from their text representations, and then extracts the maximum connected subgraph from the user-interacted item graph for denoising items. Experimental results on the Yelp and Amazon Product datasets illustrate that ConsRec achieves a 13% improvement over baseline recommendation models, showing its effectiveness in denoising user-interacted items. Further analysis reveals that the denoised interaction histories form semantically tighter clusters of user-preferred items, leading to higher relevance scores for ground-truth targets and more accurate recommendations. All codes are available at https://github.com/NEUIR/ConsRec.
RankCoT: Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts
Feb 25, 2025Retrieval-Augmented Generation (RAG) enhances the performance of Large Language Models (LLMs) by incorporating external knowledge. However, LLMs still encounter challenges in effectively utilizing the knowledge from retrieved documents, often being misled by irrelevant or noisy information. To address this issue, we introduce RankCoT, a knowledge refinement method that incorporates reranking signals in generating CoT-based summarization for knowledge refinement based on given query and all retrieval documents. During training, RankCoT prompts the LLM to generate Chain-of-Thought (CoT) candidates based on the query and individual documents. It then fine-tunes the LLM to directly reproduce the best CoT from these candidate outputs based on all retrieved documents, which requires LLM to filter out irrelevant documents during generating CoT-style summarization. Additionally, RankCoT incorporates a self-reflection mechanism that further refines the CoT outputs, resulting in higher-quality training data. Our experiments demonstrate the effectiveness of RankCoT, showing its superior performance over other knowledge refinement models. Further analysis reveals that RankCoT can provide shorter but effective refinement results, enabling the generator to produce more accurate answers. All code and data are available at https://github.com/NEUIR/RankCoT.
LLM-QE: Improving Query Expansion by Aligning Large Language Models with Ranking Preferences
Feb 24, 2025Query expansion plays a crucial role in information retrieval, which aims to bridge the semantic gap between queries and documents to improve matching performance. This paper introduces LLM-QE, a novel approach that leverages Large Language Models (LLMs) to generate document-based query expansions, thereby enhancing dense retrieval models. Unlike traditional methods, LLM-QE designs both rank-based and answer-based rewards and uses these reward models to optimize LLMs to align with the ranking preferences of both retrievers and LLMs, thus mitigating the hallucination of LLMs during query expansion. Our experiments on the zero-shot dense retrieval model, Contriever, demonstrate the effectiveness of LLM-QE, achieving an improvement of over 8%. Furthermore, by incorporating answer-based reward modeling, LLM-QE generates more relevant and precise information related to the documents, rather than simply producing redundant tokens to maximize rank-based rewards. Notably, LLM-QE also improves the training process of dense retrievers, achieving a more than 5% improvement after fine-tuning. All codes are available at https://github.com/NEUIR/LLM-QE.
Craw4LLM: Efficient Web Crawling for LLM Pretraining
Feb 19, 2025Web crawl is a main source of large language models' (LLMs) pretraining data, but the majority of crawled web pages are discarded in pretraining due to low data quality. This paper presents Crawl4LLM, an efficient web crawling method that explores the web graph based on the preference of LLM pretraining. Specifically, it leverages the influence of a webpage in LLM pretraining as the priority score of the web crawler's scheduler, replacing the standard graph connectivity based priority. Our experiments on a web graph containing 900 million webpages from a commercial search engine's index demonstrate the efficiency of Crawl4LLM in obtaining high-quality pretraining data. With just 21% URLs crawled, LLMs pretrained on Crawl4LLM data reach the same downstream performances of previous crawls, significantly reducing the crawling waste and alleviating the burdens on websites. Our code is publicly available at https://github.com/cxcscmu/Crawl4LLM.
Learning More Effective Representations for Dense Retrieval through Deliberate Thinking Before Search
Feb 18, 2025Recent dense retrievers usually thrive on the emergency capabilities of Large Language Models (LLMs), using them to encode queries and documents into an embedding space for retrieval. These LLM-based dense retrievers have shown promising performance across various retrieval scenarios. However, relying on a single embedding to represent documents proves less effective in capturing different perspectives of documents for matching. In this paper, we propose Deliberate Thinking based Dense Retriever (DEBATER), which enhances these LLM-based retrievers by enabling them to learn more effective document representations through a step-by-step thinking process. DEBATER introduces the Chain-of-Deliberation mechanism to iteratively optimize document representations using a continuous chain of thought. To consolidate information from various thinking steps, DEBATER also incorporates the Self Distillation mechanism, which identifies the most informative thinking steps and integrates them into a unified text embedding. Experimental results show that DEBATER significantly outperforms existing methods across several retrieval benchmarks, demonstrating superior accuracy and robustness. All codes are available at https://github.com/OpenBMB/DEBATER.
KBAlign: Efficient Self Adaptation on Specific Knowledge Bases
Nov 25, 2024
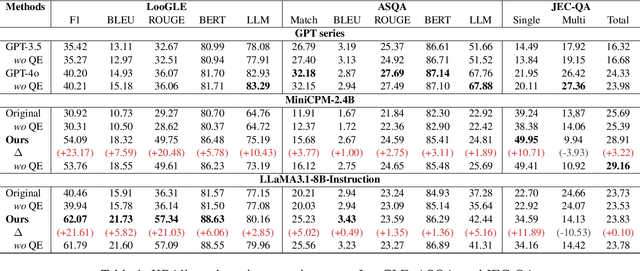
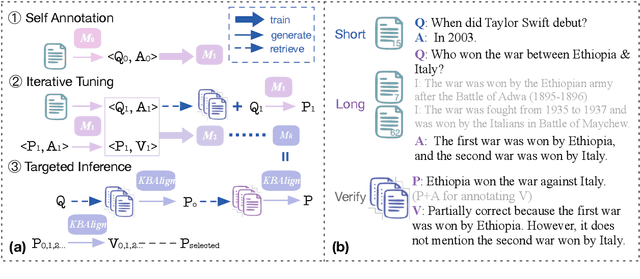

Humans can utilize techniques to quickly acquire knowledge from specific materials in advance, such as creating self-assessment questions, enabling us to achieving related tasks more efficiently. In contrast, large language models (LLMs) usually relies on retrieval-augmented generation to exploit knowledge materials in an instant manner, or requires external signals such as human preference data and stronger LLM annotations to conduct knowledge adaptation. To unleash the self-learning potential of LLMs, we propose KBAlign, an approach designed for efficient adaptation to downstream tasks involving knowledge bases. Our method utilizes iterative training with self-annotated data such as Q&A pairs and revision suggestions, enabling the model to grasp the knowledge content efficiently. Experimental results on multiple datasets demonstrate the effectiveness of our approach, significantly boosting model performance in downstream tasks that require specific knowledge at a low cost. Notably, our approach achieves over 90% of the performance improvement that can be obtained by using GPT-4-turbo annotation, while relying entirely on self-supervision. We release our experimental data, models, and process analyses to the community for further exploration (https://github.com/thunlp/KBAlign).
Building A Coding Assistant via the Retrieval-Augmented Language Model
Oct 21, 2024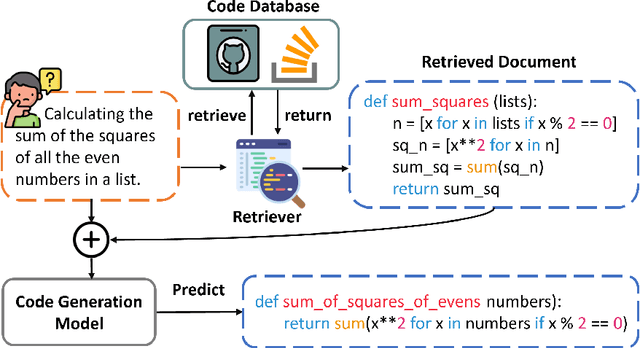

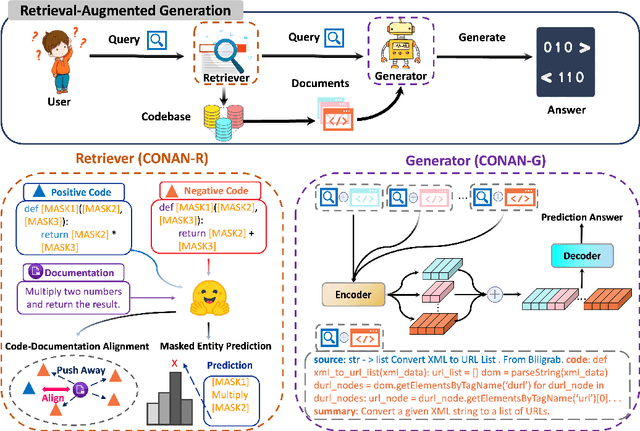
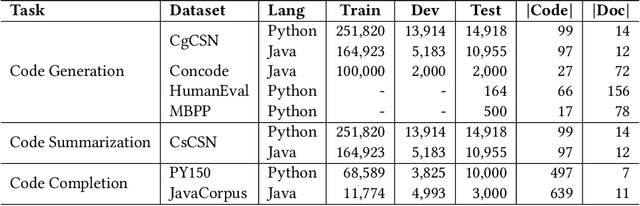
Pretrained language models have shown strong effectiveness in code-related tasks, such as code retrieval, code generation, code summarization, and code completion tasks. In this paper, we propose COde assistaNt viA retrieval-augmeNted language model (CONAN), which aims to build a code assistant by mimicking the knowledge-seeking behaviors of humans during coding. Specifically, it consists of a code structure aware retriever (CONAN-R) and a dual-view code representation-based retrieval-augmented generation model (CONAN-G). CONAN-R pretrains CodeT5 using Code-Documentation Alignment and Masked Entity Prediction tasks to make language models code structure-aware and learn effective representations for code snippets and documentation. Then CONAN-G designs a dual-view code representation mechanism for implementing a retrieval-augmented code generation model. CONAN-G regards the code documentation descriptions as prompts, which help language models better understand the code semantics. Our experiments show that CONAN achieves convincing performance on different code generation tasks and significantly outperforms previous retrieval augmented code generation models. Our further analyses show that CONAN learns tailored representations for both code snippets and documentation by aligning code-documentation data pairs and capturing structural semantics by masking and predicting entities in the code data. Additionally, the retrieved code snippets and documentation provide necessary information from both program language and natural language to assist the code generation process. CONAN can also be used as an assistant for Large Language Models (LLMs), providing LLMs with external knowledge in shorter code document lengths to improve their effectiveness on various code tasks. It shows the ability of CONAN to extract necessary information and help filter out the noise from retrieved code documents.
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
Oct 17, 2024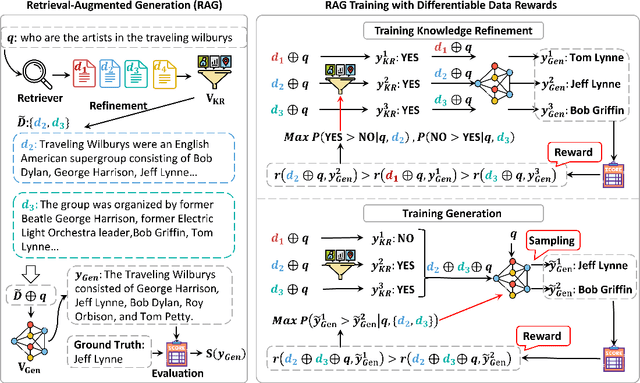
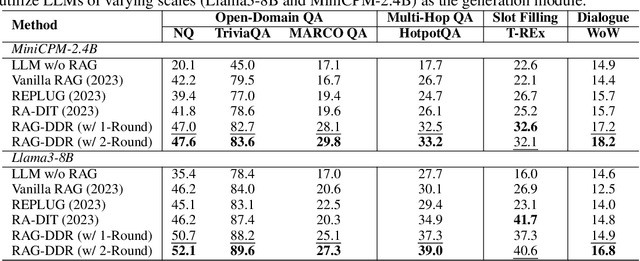
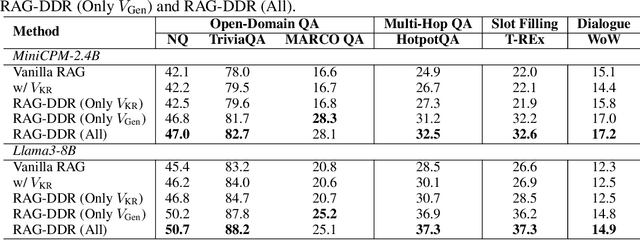
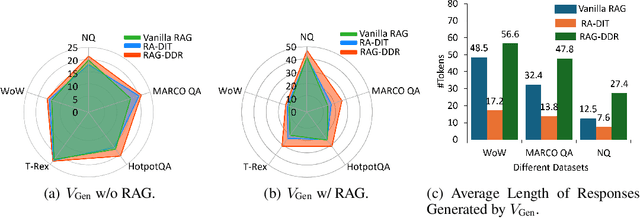
Retrieval-Augmented Generation (RAG) has proven its effectiveness in mitigating hallucinations in Large Language Models (LLMs) by retrieving knowledge from external resources. To adapt LLMs for RAG pipelines, current approaches use instruction tuning to optimize LLMs, improving their ability to utilize retrieved knowledge. This supervised fine-tuning (SFT) approach focuses on equipping LLMs to handle diverse RAG tasks using different instructions. However, it trains RAG modules to overfit training signals and overlooks the varying data preferences among agents within the RAG system. In this paper, we propose a Differentiable Data Rewards (DDR) method, which end-to-end trains RAG systems by aligning data preferences between different RAG modules. DDR works by collecting the rewards to optimize each agent with a rollout method. This method prompts agents to sample some potential responses as perturbations, evaluates the impact of these perturbations on the whole RAG system, and subsequently optimizes the agent to produce outputs that improve the performance of the RAG system. Our experiments on various knowledge-intensive tasks demonstrate that DDR significantly outperforms the SFT method, particularly for LLMs with smaller-scale parameters that depend more on the retrieved knowledge. Additionally, DDR exhibits a stronger capability to align the data preference between RAG modules. The DDR method makes generation module more effective in extracting key information from documents and mitigating conflicts between parametric memory and external knowledge. All codes are available at https://github.com/OpenMatch/RAG-DDR.
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Oct 14, 2024



Retrieval-augmented generation (RAG) is an effective technique that enables large language models (LLMs) to utilize external knowledge sources for generation. However, current RAG systems are solely based on text, rendering it impossible to utilize vision information like layout and images that play crucial roles in real-world multi-modality documents. In this paper, we introduce VisRAG, which tackles this issue by establishing a vision-language model (VLM)-based RAG pipeline. In this pipeline, instead of first parsing the document to obtain text, the document is directly embedded using a VLM as an image and then retrieved to enhance the generation of a VLM. Compared to traditional text-based RAG, VisRAG maximizes the retention and utilization of the data information in the original documents, eliminating the information loss introduced during the parsing process. We collect both open-source and synthetic data to train the retriever in VisRAG and explore a variety of generation methods. Experiments demonstrate that VisRAG outperforms traditional RAG in both the retrieval and generation stages, achieving a 25--39\% end-to-end performance gain over traditional text-based RAG pipeline. Further analysis reveals that VisRAG is effective in utilizing training data and demonstrates strong generalization capability, positioning it as a promising solution for RAG on multi-modality documents. Our code and data are available at https://github.com/openbmb/visrag .