 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning
May 28, 2025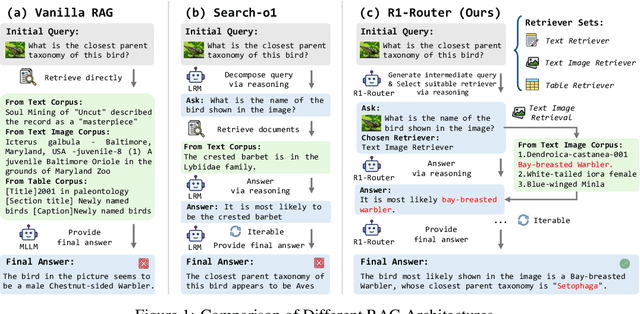
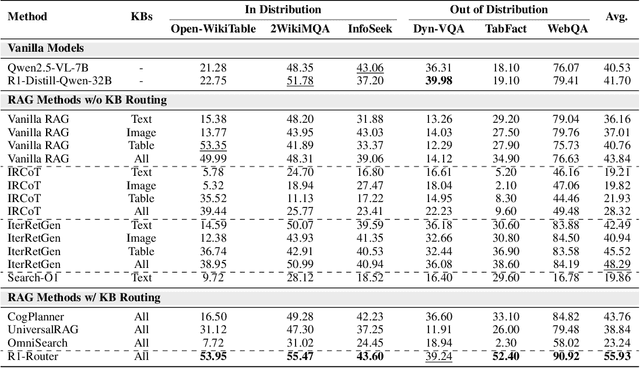
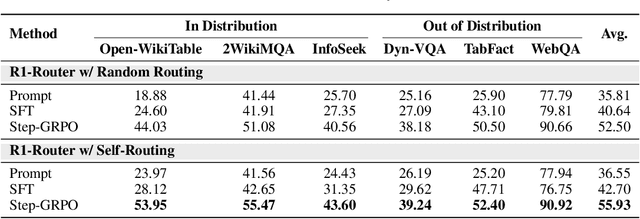
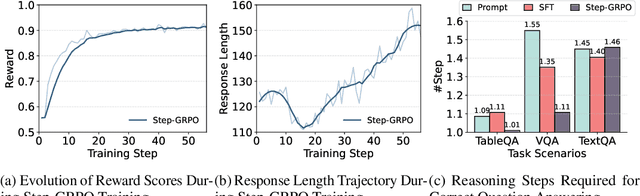
Multimodal Retrieval-Augmented Generation (MRAG) has shown promise in mitigating hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge during generation. Existing MRAG methods typically adopt a static retrieval pipeline that fetches relevant information from multiple Knowledge Bases (KBs), followed by a refinement step. However, these approaches overlook the reasoning and planning capabilities of MLLMs to dynamically determine how to interact with different KBs during the reasoning process. To address this limitation, we propose R1-Router, a novel MRAG framework that learns to decide when and where to retrieve knowledge based on the evolving reasoning state. Specifically, R1-Router can generate follow-up queries according to the current reasoning step, routing these intermediate queries to the most suitable KB, and integrating external knowledge into a coherent reasoning trajectory to answer the original query. Furthermore, we introduce Step-wise Group Relative Policy Optimization (Step-GRPO), a tailored reinforcement learning algorithm that assigns step-specific rewards to optimize the reasoning behavior of MLLMs. Experimental results on various open-domain QA benchmarks across multiple modalities demonstrate that R1-Router outperforms baseline models by over 7%. Further analysis shows that R1-Router can adaptively and effectively leverage diverse KBs, reducing unnecessary retrievals and improving both efficiency and accuracy.
Learning More Effective Representations for Dense Retrieval through Deliberate Thinking Before Search
Feb 18, 2025Recent dense retrievers usually thrive on the emergency capabilities of Large Language Models (LLMs), using them to encode queries and documents into an embedding space for retrieval. These LLM-based dense retrievers have shown promising performance across various retrieval scenarios. However, relying on a single embedding to represent documents proves less effective in capturing different perspectives of documents for matching. In this paper, we propose Deliberate Thinking based Dense Retriever (DEBATER), which enhances these LLM-based retrievers by enabling them to learn more effective document representations through a step-by-step thinking process. DEBATER introduces the Chain-of-Deliberation mechanism to iteratively optimize document representations using a continuous chain of thought. To consolidate information from various thinking steps, DEBATER also incorporates the Self Distillation mechanism, which identifies the most informative thinking steps and integrates them into a unified text embedding. Experimental results show that DEBATER significantly outperforms existing methods across several retrieval benchmarks, demonstrating superior accuracy and robustness. All codes are available at https://github.com/OpenBMB/DEBATER.
Large Language Models as Evaluators for Recommendation Explanations
Jun 06, 2024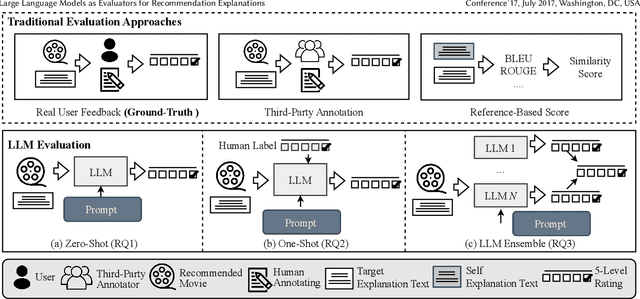
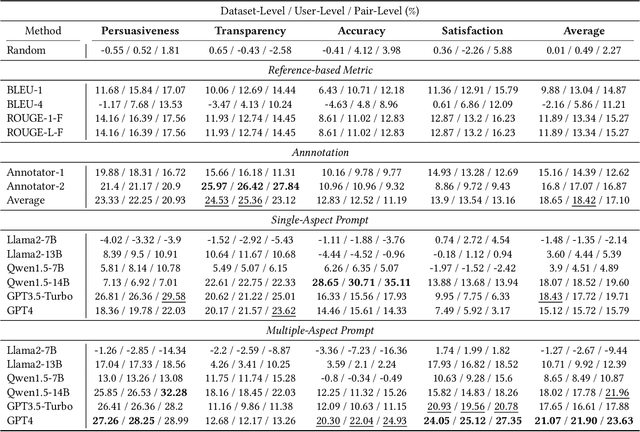


The explainability of recommender systems has attracted significant attention in academia and industry. Many efforts have been made for explainable recommendations, yet evaluating the quality of the explanations remains a challenging and unresolved issue. In recent years, leveraging LLMs as evaluators presents a promising avenue in Natural Language Processing tasks (e.g., sentiment classification, information extraction), as they perform strong capabilities in instruction following and common-sense reasoning. However, evaluating recommendation explanatory texts is different from these NLG tasks, as its criteria are related to human perceptions and are usually subjective. In this paper, we investigate whether LLMs can serve as evaluators of recommendation explanations. To answer the question, we utilize real user feedback on explanations given from previous work and additionally collect third-party annotations and LLM evaluations. We design and apply a 3-level meta evaluation strategy to measure the correlation between evaluator labels and the ground truth provided by users. Our experiments reveal that LLMs, such as GPT4, can provide comparable evaluations with appropriate prompts and settings. We also provide further insights into combining human labels with the LLM evaluation process and utilizing ensembles of multiple heterogeneous LLM evaluators to enhance the accuracy and stability of evaluations. Our study verifies that utilizing LLMs as evaluators can be an accurate, reproducible and cost-effective solution for evaluating recommendation explanation texts. Our code is available at https://github.com/Xiaoyu-SZ/LLMasEvaluator.
TIGERScore: Towards Building Explainable Metric for All Text Generation Tasks
Oct 01, 2023We present TIGERScore, a \textbf{T}rained metric that follows \textbf{I}nstruction \textbf{G}uidance to perform \textbf{E}xplainable, and \textbf{R}eference-free evaluation over a wide spectrum of text generation tasks. Different from other automatic evaluation methods that only provide arcane scores, TIGERScore is guided by the natural language instruction to provide error analysis to pinpoint the mistakes in the generated text. Our metric is based on LLaMA, trained on our meticulously curated instruction-tuning dataset MetricInstruct which covers 6 text generation tasks and 23 text generation datasets. The dataset consists of 48K quadruple in the form of (instruction, input, system output $\rightarrow$ error analysis). We collected the `system outputs' through diverse channels to cover different types of errors. To quantitatively assess our metric, we evaluate its correlation with human ratings on 5 held-in datasets, 2 held-out datasets and show that TIGERScore can achieve the highest overall Spearman's correlation with human ratings across these datasets and outperforms other metrics significantly. As a reference-free metric, its correlation can even surpass the best existing reference-based metrics. To further qualitatively assess the rationale generated by our metric, we conduct human evaluation on the generated explanations and found that the explanations are 70.8\% accurate. Through these experimental results, we believe TIGERScore demonstrates the possibility of building universal explainable metrics to evaluate any text generation task.