 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Forcing: Consistent Autoregressive Video Generation with Long Context
Feb 05, 2026Recent approaches to real-time long video generation typically employ streaming tuning strategies, attempting to train a long-context student using a short-context (memoryless) teacher. In these frameworks, the student performs long rollouts but receives supervision from a teacher limited to short 5-second windows. This structural discrepancy creates a critical \textbf{student-teacher mismatch}: the teacher's inability to access long-term history prevents it from guiding the student on global temporal dependencies, effectively capping the student's context length. To resolve this, we propose \textbf{Context Forcing}, a novel framework that trains a long-context student via a long-context teacher. By ensuring the teacher is aware of the full generation history, we eliminate the supervision mismatch, enabling the robust training of models capable of long-term consistency. To make this computationally feasible for extreme durations (e.g., 2 minutes), we introduce a context management system that transforms the linearly growing context into a \textbf{Slow-Fast Memory} architecture, significantly reducing visual redundancy. Extensive results demonstrate that our method enables effective context lengths exceeding 20 seconds -- 2 to 10 times longer than state-of-the-art methods like LongLive and Infinite-RoPE. By leveraging this extended context, Context Forcing preserves superior consistency across long durations, surpassing state-of-the-art baselines on various long video evaluation metrics.
Quantifying the Gap between Understanding and Generation within Unified Multimodal Models
Feb 02, 2026Recent advances in unified multimodal models (UMM) have demonstrated remarkable progress in both understanding and generation tasks. However, whether these two capabilities are genuinely aligned and integrated within a single model remains unclear. To investigate this question, we introduce GapEval, a bidirectional benchmark designed to quantify the gap between understanding and generation capabilities, and quantitatively measure the cognitive coherence of the two "unified" directions. Each question can be answered in both modalities (image and text), enabling a symmetric evaluation of a model's bidirectional inference capability and cross-modal consistency. Experiments reveal a persistent gap between the two directions across a wide range of UMMs with different architectures, suggesting that current models achieve only surface-level unification rather than deep cognitive convergence of the two. To further explore the underlying mechanism, we conduct an empirical study from the perspective of knowledge manipulation to illustrate the underlying limitations. Our findings indicate that knowledge within UMMs often remains disjoint. The capability emergence and knowledge across modalities are unsynchronized, paving the way for further exploration.
CogDoc: Towards Unified thinking in Documents
Dec 14, 2025Current document reasoning paradigms are constrained by a fundamental trade-off between scalability (processing long-context documents) and fidelity (capturing fine-grained, multimodal details). To bridge this gap, we propose CogDoc, a unified coarse-to-fine thinking framework that mimics human cognitive processes: a low-resolution "Fast Reading" phase for scalable information localization,followed by a high-resolution "Focused Thinking" phase for deep reasoning. We conduct a rigorous investigation into post-training strategies for the unified thinking framework, demonstrating that a Direct Reinforcement Learning (RL) approach outperforms RL with Supervised Fine-Tuning (SFT) initialization. Specifically, we find that direct RL avoids the "policy conflict" observed in SFT. Empirically, our 7B model achieves state-of-the-art performance within its parameter class, notably surpassing significantly larger proprietary models (e.g., GPT-4o) on challenging, visually rich document benchmarks.
Language Models Can Learn from Verbal Feedback Without Scalar Rewards
Sep 26, 2025
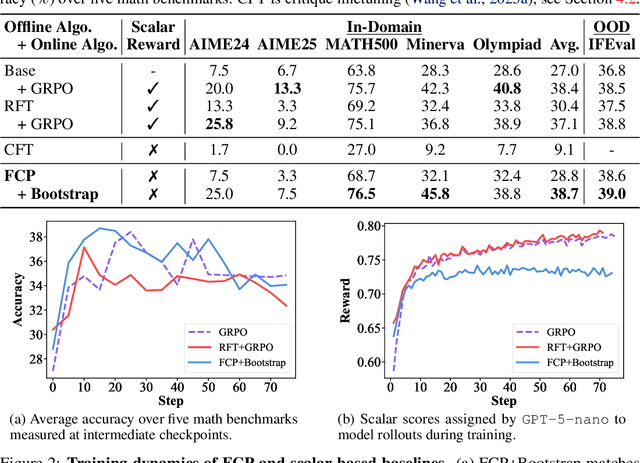
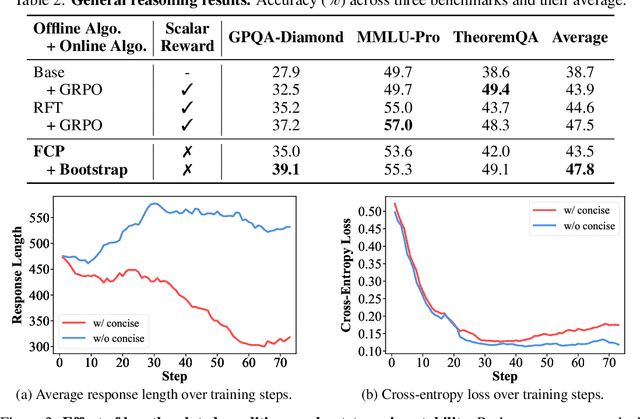
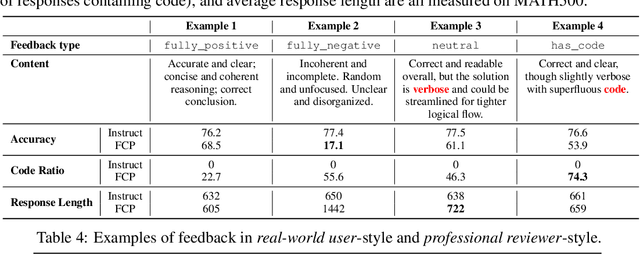
LLMs are often trained with RL from human or AI feedback, yet such methods typically compress nuanced feedback into scalar rewards, discarding much of their richness and inducing scale imbalance. We propose treating verbal feedback as a conditioning signal. Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP). FCP learns directly from response-feedback pairs, approximating the feedback-conditional posterior through maximum likelihood training on offline data. We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself. This reframes feedback-driven learning as conditional generation rather than reward optimization, offering a more expressive way for LLMs to directly learn from verbal feedback. Our code is available at https://github.com/sail-sg/feedback-conditional-policy.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Sep 03, 2025



Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like ``aha moments", ``length-scaling'' and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose HIerarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. HICRA significantly outperforms strong baselines, demonstrating that focusing on this strategic bottleneck is key to unlocking advanced reasoning. Furthermore, we validate semantic entropy as a superior compass for measuring strategic exploration over misleading metrics such as token-level entropy.
DisProtEdit: Exploring Disentangled Representations for Multi-Attribute Protein Editing
Jun 17, 2025We introduce DisProtEdit, a controllable protein editing framework that leverages dual-channel natural language supervision to learn disentangled representations of structural and functional properties. Unlike prior approaches that rely on joint holistic embeddings, DisProtEdit explicitly separates semantic factors, enabling modular and interpretable control. To support this, we construct SwissProtDis, a large-scale multimodal dataset where each protein sequence is paired with two textual descriptions, one for structure and one for function, automatically decomposed using a large language model. DisProtEdit aligns protein and text embeddings using alignment and uniformity objectives, while a disentanglement loss promotes independence between structural and functional semantics. At inference time, protein editing is performed by modifying one or both text inputs and decoding from the updated latent representation. Experiments on protein editing and representation learning benchmarks demonstrate that DisProtEdit performs competitively with existing methods while providing improved interpretability and controllability. On a newly constructed multi-attribute editing benchmark, the model achieves a both-hit success rate of up to 61.7%, highlighting its effectiveness in coordinating simultaneous structural and functional edits.
VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation
Jun 04, 2025Large language models (LLMs) often struggle with visualization tasks like plotting diagrams, charts, where success depends on both code correctness and visual semantics. Existing instruction-tuning datasets lack execution-grounded supervision and offer limited support for iterative code correction, resulting in fragile and unreliable plot generation. We present VisCode-200K, a large-scale instruction tuning dataset for Python-based visualization and self-correction. It contains over 200K examples from two sources: (1) validated plotting code from open-source repositories, paired with natural language instructions and rendered plots; and (2) 45K multi-turn correction dialogues from Code-Feedback, enabling models to revise faulty code using runtime feedback. We fine-tune Qwen2.5-Coder-Instruct on VisCode-200K to create VisCoder, and evaluate it on PandasPlotBench. VisCoder significantly outperforms strong open-source baselines and approaches the performance of proprietary models like GPT-4o-mini. We further adopt a self-debug evaluation protocol to assess iterative repair, demonstrating the benefits of feedback-driven learning for executable, visually accurate code generation.
StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
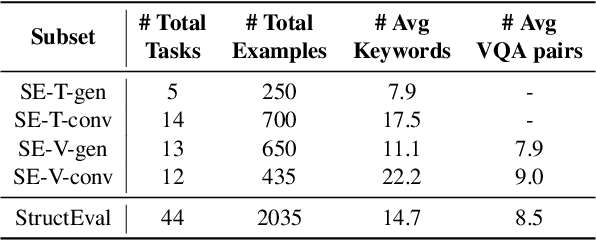
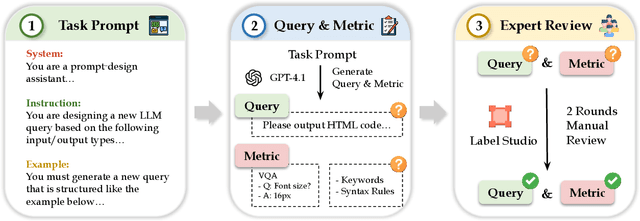

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design
May 22, 2025



Long-video understanding has emerged as a crucial capability in real-world applications such as video surveillance, meeting summarization, educational lecture analysis, and sports broadcasting. However, it remains computationally prohibitive for VideoLLMs, primarily due to two bottlenecks: 1) sequential video decoding, the process of converting the raw bit stream to RGB frames can take up to a minute for hour-long video inputs, and 2) costly prefilling of up to several million tokens for LLM inference, resulting in high latency and memory use. To address these challenges, we propose QuickVideo, a system-algorithm co-design that substantially accelerates long-video understanding to support real-time downstream applications. It comprises three key innovations: QuickDecoder, a parallelized CPU-based video decoder that achieves 2-3 times speedup by splitting videos into keyframe-aligned intervals processed concurrently; QuickPrefill, a memory-efficient prefilling method using KV-cache pruning to support more frames with less GPU memory; and an overlapping scheme that overlaps CPU video decoding with GPU inference. Together, these components infernece time reduce by a minute on long video inputs, enabling scalable, high-quality video understanding even on limited hardware. Experiments show that QuickVideo generalizes across durations and sampling rates, making long video processing feasible in practice.
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
May 21, 2025



Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model's initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84\% on V* bench, 74\% on TallyQA-Complex, and 84\% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.