 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyapunov Stable Graph Neural Flow
Mar 13, 2026Graph Neural Networks (GNNs) are highly vulnerable to adversarial perturbations in both topology and features, making the learning of robust representations a critical challenge. In this work, we bridge GNNs with control theory to introduce a novel defense framework grounded in integer- and fractional-order Lyapunov stability. Unlike conventional strategies that rely on resource-heavy adversarial training or data purification, our approach fundamentally constrains the underlying feature-update dynamics of the GNN. We propose an adaptive, learnable Lyapunov function paired with a novel projection mechanism that maps the network's state into a stable space, thereby offering theoretically provable stability guarantees. Notably, this mechanism is orthogonal to existing defenses, allowing for seamless integration with techniques like adversarial training to achieve cumulative robustness. Extensive experiments demonstrate that our Lyapunov-stable graph neural flows substantially outperform base neural flows and state-of-the-art baselines across standard benchmarks and various adversarial attack scenarios.
ACECODER: Acing Coder RL via Automated Test-Case Synthesis
Feb 03, 2025Most progress in recent coder models has been driven by supervised fine-tuning (SFT), while the potential of reinforcement learning (RL) remains largely unexplored, primarily due to the lack of reliable reward data/model in the code domain. In this paper, we address this challenge by leveraging automated large-scale test-case synthesis to enhance code model training. Specifically, we design a pipeline that generates extensive (question, test-cases) pairs from existing code data. Using these test cases, we construct preference pairs based on pass rates over sampled programs to train reward models with Bradley-Terry loss. It shows an average of 10-point improvement for Llama-3.1-8B-Ins and 5-point improvement for Qwen2.5-Coder-7B-Ins through best-of-32 sampling, making the 7B model on par with 236B DeepSeek-V2.5. Furthermore, we conduct reinforcement learning with both reward models and test-case pass rewards, leading to consistent improvements across HumanEval, MBPP, BigCodeBench, and LiveCodeBench (V4). Notably, we follow the R1-style training to start from Qwen2.5-Coder-base directly and show that our RL training can improve model on HumanEval-plus by over 25\% and MBPP-plus by 6\% for merely 80 optimization steps. We believe our results highlight the huge potential of reinforcement learning in coder models.
Static Batching of Irregular Workloads on GPUs: Framework and Application to Efficient MoE Model Inference
Jan 27, 2025
It has long been a problem to arrange and execute irregular workloads on massively parallel devices. We propose a general framework for statically batching irregular workloads into a single kernel with a runtime task mapping mechanism on GPUs. We further apply this framework to Mixture-of-Experts (MoE) model inference and implement an optimized and efficient CUDA kernel. Our MoE kernel achieves up to 91% of the peak Tensor Core throughput on NVIDIA H800 GPU and 95% on NVIDIA H20 GPU.
EditRoom: LLM-parameterized Graph Diffusion for Composable 3D Room Layout Editing
Oct 03, 2024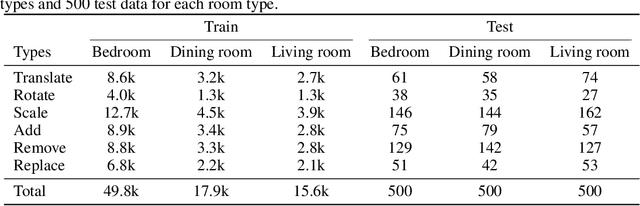
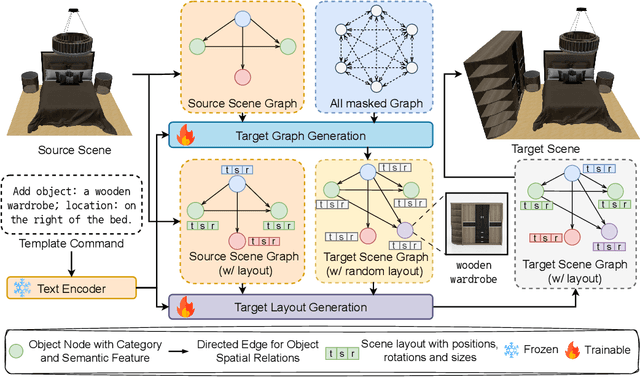

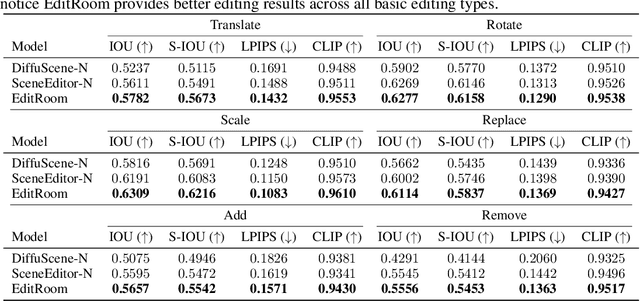
Given the steep learning curve of professional 3D software and the time-consuming process of managing large 3D assets, language-guided 3D scene editing has significant potential in fields such as virtual reality, augmented reality, and gaming. However, recent approaches to language-guided 3D scene editing either require manual interventions or focus only on appearance modifications without supporting comprehensive scene layout changes. In response, we propose Edit-Room, a unified framework capable of executing a variety of layout edits through natural language commands, without requiring manual intervention. Specifically, EditRoom leverages Large Language Models (LLMs) for command planning and generates target scenes using a diffusion-based method, enabling six types of edits: rotate, translate, scale, replace, add, and remove. To address the lack of data for language-guided 3D scene editing, we have developed an automatic pipeline to augment existing 3D scene synthesis datasets and introduced EditRoom-DB, a large-scale dataset with 83k editing pairs, for training and evaluation. Our experiments demonstrate that our approach consistently outperforms other baselines across all metrics, indicating higher accuracy and coherence in language-guided scene layout editing.
Tabletop Transparent Scene Reconstruction via Epipolar-Guided Optical Flow with Monocular Depth Completion Prior
Oct 15, 2023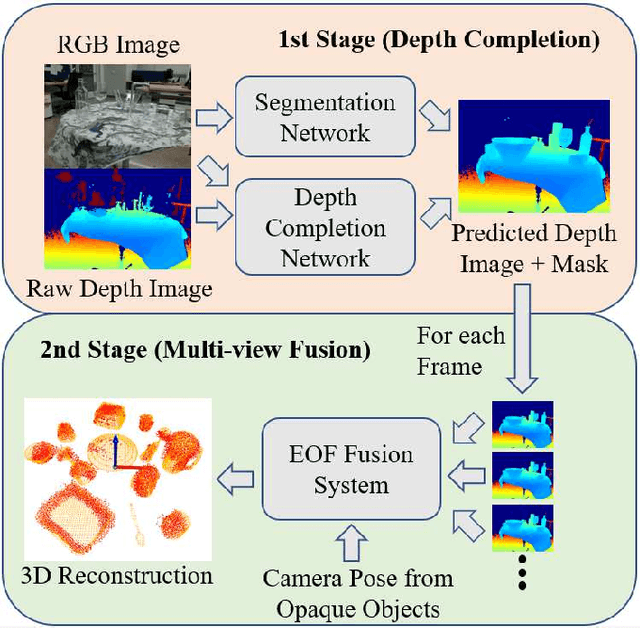


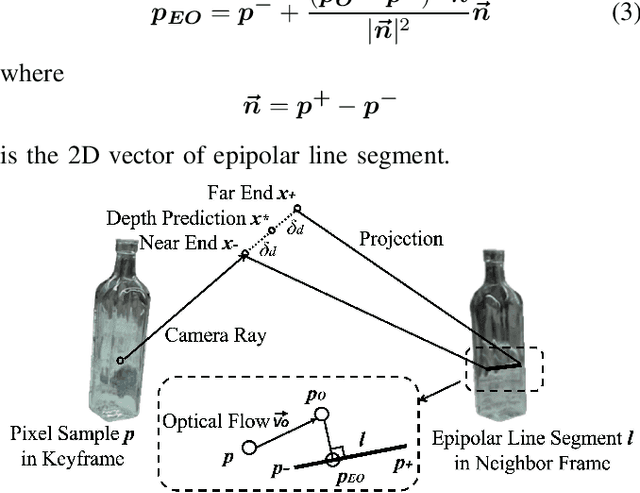
Reconstructing transparent objects using affordable RGB-D cameras is a persistent challenge in robotic perception due to inconsistent appearances across views in the RGB domain and inaccurate depth readings in each single-view. We introduce a two-stage pipeline for reconstructing transparent objects tailored for mobile platforms. In the first stage, off-the-shelf monocular object segmentation and depth completion networks are leveraged to predict the depth of transparent objects, furnishing single-view shape prior. Subsequently, we propose Epipolar-guided Optical Flow (EOF) to fuse several single-view shape priors from the first stage to a cross-view consistent 3D reconstruction given camera poses estimated from opaque part of the scene. Our key innovation lies in EOF which employs boundary-sensitive sampling and epipolar-line constraints into optical flow to accurately establish 2D correspondences across multiple views on transparent objects. Quantitative evaluations demonstrate that our pipeline significantly outperforms baseline methods in 3D reconstruction quality, paving the way for more adept robotic perception and interaction with transparent objects.
TransNet: Transparent Object Manipulation Through Category-Level Pose Estimation
Jul 23, 2023



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, like glass doors, difficult to perceive. A second challenge is that depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent surfaces due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category, such as cups, look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper explores the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose \textit{\textbf{TransNet}}, a two-stage pipeline that estimates category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects. Moreover, we use TransNet to build an autonomous transparent object manipulation system for robotic pick-and-place and pouring tasks.
An Operational Perspective to Fairness Interventions: Where and How to Intervene
Feb 03, 2023



As AI-based decision systems proliferate, their successful operationalization requires balancing multiple desiderata: predictive performance, disparity across groups, safeguarding sensitive group attributes (e.g., race), and engineering cost. We present a holistic framework for evaluating and contextualizing fairness interventions with respect to the above desiderata. The two key points of practical consideration are where (pre-, in-, post-processing) and how (in what way the sensitive group data is used) the intervention is introduced. We demonstrate our framework using a thorough benchmarking study on predictive parity; we study close to 400 methodological variations across two major model types (XGBoost vs. Neural Net) and ten datasets. Methodological insights derived from our empirical study inform the practical design of ML workflow with fairness as a central concern. We find predictive parity is difficult to achieve without using group data, and despite requiring group data during model training (but not inference), distributionally robust methods provide significant Pareto improvement. Moreover, a plain XGBoost model often Pareto-dominates neural networks with fairness interventions, highlighting the importance of model inductive bias.
Pair DETR: Contrastive Learning Speeds Up DETR Training
Nov 11, 2022



The DETR object detection approach applies the transformer encoder and decoder architecture to detect objects and achieves promising performance. In this paper, we present a simple approach to address the main problem of DETR, the slow convergence, by using representation learning technique. In this approach, we detect an object bounding box as a pair of keypoints, the top-left corner and the center, using two decoders. By detecting objects as paired keypoints, the model builds up a joint classification and pair association on the output queries from two decoders. For the pair association we propose utilizing contrastive self-supervised learning algorithm without requiring specialized architecture. Experimental results on MS COCO dataset show that Pair DETR can converge at least 10x faster than original DETR and 1.5x faster than Conditional DETR during training, while having consistently higher Average Precision scores.
TransNet: Category-Level Transparent Object Pose Estimation
Aug 22, 2022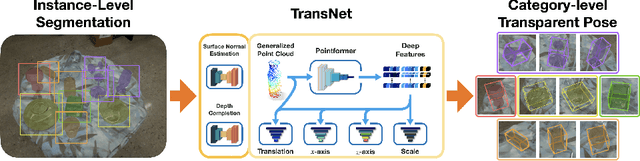



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, e.g. glass doors, difficult to perceive. A second challenge is that common depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent objects due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category (e.g. cups) look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper sets out to explore the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose TransNet, a two-stage pipeline that learns to estimate category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a recent, large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects and key findings from the included ablation studies suggest future directions for performance improvements.
TE2Rules: Extracting Rule Lists from Tree Ensembles
Jun 30, 2022

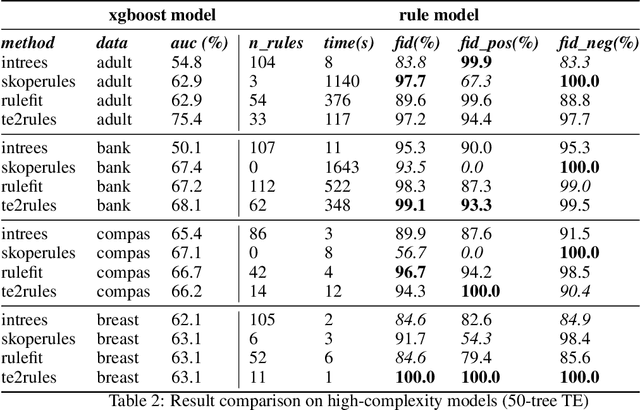

Tree Ensemble (TE) models (e.g. Gradient Boosted Trees and Random Forests) often provide higher prediction performance compared to single decision trees. However, TE models generally lack transparency and interpretability, as humans have difficulty understanding their decision logic. This paper presents a novel approach to convert a TE trained for a binary classification task, to a rule list (RL) that is a global equivalent to the TE and is comprehensible for a human. This RL captures all necessary and sufficient conditions for decision making by the TE. Experiments on benchmark datasets demonstrate that, compared to state-of-the-art methods, (i) predictions from the RL generated by TE2Rules have high fidelity with respect to the original TE, (ii) the RL from TE2Rules has high interpretability measured by the number and the length of the decision rules, (iii) the run-time of TE2Rules algorithm can be reduced significantly at the cost of a slightly lower fidelity, and (iv) the RL is a fast alternative to the state-of-the-art rule-based instance-level outcome explanation techniques.