 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
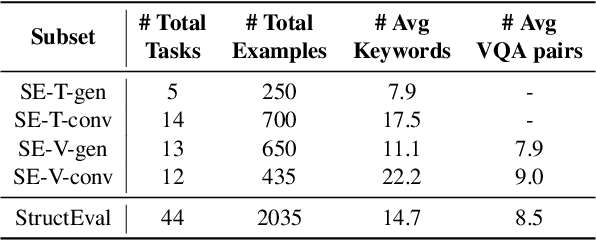
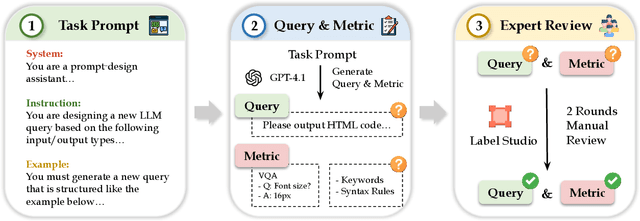

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations
Apr 03, 2025Academic writing requires both coherent text generation and precise citation of relevant literature. Although recent Retrieval-Augmented Generation (RAG) systems have significantly improved factual accuracy in general-purpose text generation, their ability to support professional academic writing remains limited. In this work, we introduce ScholarCopilot, a unified framework designed to enhance existing large language models for generating professional academic articles with accurate and contextually relevant citations. ScholarCopilot dynamically determines when to retrieve scholarly references by generating a retrieval token [RET], which is then used to query a citation database. The retrieved references are fed into the model to augment the generation process. We jointly optimize both the generation and citation tasks within a single framework to improve efficiency. Our model is built upon Qwen-2.5-7B and trained on 500K papers from arXiv. It achieves a top-1 retrieval accuracy of 40.1% on our evaluation dataset, outperforming baselines such as E5-Mistral-7B-Instruct (15.0%) and BM25 (9.8%). On a dataset of 1,000 academic writing samples, ScholarCopilot scores 16.2/25 in generation quality -- measured across relevance, coherence, academic rigor, completeness, and innovation -- significantly surpassing all existing models, including much larger ones like the Retrieval-Augmented Qwen2.5-72B-Instruct. Human studies further demonstrate that ScholarCopilot, despite being a 7B model, significantly outperforms ChatGPT, achieving 100% preference in citation quality and over 70% in overall usefulness.
ACECODER: Acing Coder RL via Automated Test-Case Synthesis
Feb 03, 2025Most progress in recent coder models has been driven by supervised fine-tuning (SFT), while the potential of reinforcement learning (RL) remains largely unexplored, primarily due to the lack of reliable reward data/model in the code domain. In this paper, we address this challenge by leveraging automated large-scale test-case synthesis to enhance code model training. Specifically, we design a pipeline that generates extensive (question, test-cases) pairs from existing code data. Using these test cases, we construct preference pairs based on pass rates over sampled programs to train reward models with Bradley-Terry loss. It shows an average of 10-point improvement for Llama-3.1-8B-Ins and 5-point improvement for Qwen2.5-Coder-7B-Ins through best-of-32 sampling, making the 7B model on par with 236B DeepSeek-V2.5. Furthermore, we conduct reinforcement learning with both reward models and test-case pass rewards, leading to consistent improvements across HumanEval, MBPP, BigCodeBench, and LiveCodeBench (V4). Notably, we follow the R1-style training to start from Qwen2.5-Coder-base directly and show that our RL training can improve model on HumanEval-plus by over 25\% and MBPP-plus by 6\% for merely 80 optimization steps. We believe our results highlight the huge potential of reinforcement learning in coder models.
MANTIS: Interleaved Multi-Image Instruction Tuning
May 02, 2024



The recent years have witnessed a great array of large multimodal models (LMMs) to effectively solve single-image vision language tasks. However, their abilities to solve multi-image visual language tasks is yet to be improved. The existing multi-image LMMs (e.g. OpenFlamingo, Emu, Idefics, etc) mostly gain their multi-image ability through pre-training on hundreds of millions of noisy interleaved image-text data from web, which is neither efficient nor effective. In this paper, we aim at building strong multi-image LMMs via instruction tuning with academic-level resources. Therefore, we meticulously construct Mantis-Instruct containing 721K instances from 14 multi-image datasets. We design Mantis-Instruct to cover different multi-image skills like co-reference, reasoning, comparing, temporal understanding. We combine Mantis-Instruct with several single-image visual-language datasets to train our model Mantis to handle any interleaved image-text inputs. We evaluate the trained Mantis on five multi-image benchmarks and eight single-image benchmarks. Though only requiring academic-level resources (i.e. 36 hours on 16xA100-40G), Mantis-8B can achieve state-of-the-art performance on all the multi-image benchmarks and beats the existing best multi-image LMM Idefics2-8B by an average of 9 absolute points. We observe that Mantis performs equivalently well on the held-in and held-out evaluation benchmarks. We further evaluate Mantis on single-image benchmarks and demonstrate that Mantis can maintain a strong single-image performance on par with CogVLM and Emu2. Our results are particularly encouraging as it shows that low-cost instruction tuning is indeed much more effective than intensive pre-training in terms of building multi-image LMMs.