 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisProtEdit: Exploring Disentangled Representations for Multi-Attribute Protein Editing
Jun 17, 2025We introduce DisProtEdit, a controllable protein editing framework that leverages dual-channel natural language supervision to learn disentangled representations of structural and functional properties. Unlike prior approaches that rely on joint holistic embeddings, DisProtEdit explicitly separates semantic factors, enabling modular and interpretable control. To support this, we construct SwissProtDis, a large-scale multimodal dataset where each protein sequence is paired with two textual descriptions, one for structure and one for function, automatically decomposed using a large language model. DisProtEdit aligns protein and text embeddings using alignment and uniformity objectives, while a disentanglement loss promotes independence between structural and functional semantics. At inference time, protein editing is performed by modifying one or both text inputs and decoding from the updated latent representation. Experiments on protein editing and representation learning benchmarks demonstrate that DisProtEdit performs competitively with existing methods while providing improved interpretability and controllability. On a newly constructed multi-attribute editing benchmark, the model achieves a both-hit success rate of up to 61.7%, highlighting its effectiveness in coordinating simultaneous structural and functional edits.
TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding
Feb 26, 2025Understanding domain-specific theorems often requires more than just text-based reasoning; effective communication through structured visual explanations is crucial for deeper comprehension. While large language models (LLMs) demonstrate strong performance in text-based theorem reasoning, their ability to generate coherent and pedagogically meaningful visual explanations remains an open challenge. In this work, we introduce TheoremExplainAgent, an agentic approach for generating long-form theorem explanation videos (over 5 minutes) using Manim animations. To systematically evaluate multimodal theorem explanations, we propose TheoremExplainBench, a benchmark covering 240 theorems across multiple STEM disciplines, along with 5 automated evaluation metrics. Our results reveal that agentic planning is essential for generating detailed long-form videos, and the o3-mini agent achieves a success rate of 93.8% and an overall score of 0.77. However, our quantitative and qualitative studies show that most of the videos produced exhibit minor issues with visual element layout. Furthermore, multimodal explanations expose deeper reasoning flaws that text-based explanations fail to reveal, highlighting the importance of multimodal explanations.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024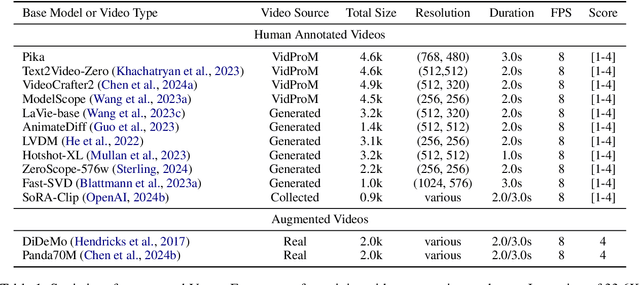


The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
GenAI Arena: An Open Evaluation Platform for Generative Models
Jun 06, 2024Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs. This paper proposes an open platform GenAI-Arena to evaluate different image and video generative models, where users can actively participate in evaluating these models. By leveraging collective user feedback and votes, GenAI-Arena aims to provide a more democratic and accurate measure of model performance. It covers three arenas for text-to-image generation, text-to-video generation, and image editing respectively. Currently, we cover a total of 27 open-source generative models. GenAI-Arena has been operating for four months, amassing over 6000 votes from the community. We describe our platform, analyze the data, and explain the statistical methods for ranking the models. To further promote the research in building model-based evaluation metrics, we release a cleaned version of our preference data for the three tasks, namely GenAI-Bench. We prompt the existing multi-modal models like Gemini, GPT-4o to mimic human voting. We compute the correlation between model voting with human voting to understand their judging abilities. Our results show existing multimodal models are still lagging in assessing the generated visual content, even the best model GPT-4o only achieves a Pearson correlation of 0.22 in the quality subscore, and behaves like random guessing in others.
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Jun 04, 2024



In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
MANTIS: Interleaved Multi-Image Instruction Tuning
May 02, 2024



The recent years have witnessed a great array of large multimodal models (LMMs) to effectively solve single-image vision language tasks. However, their abilities to solve multi-image visual language tasks is yet to be improved. The existing multi-image LMMs (e.g. OpenFlamingo, Emu, Idefics, etc) mostly gain their multi-image ability through pre-training on hundreds of millions of noisy interleaved image-text data from web, which is neither efficient nor effective. In this paper, we aim at building strong multi-image LMMs via instruction tuning with academic-level resources. Therefore, we meticulously construct Mantis-Instruct containing 721K instances from 14 multi-image datasets. We design Mantis-Instruct to cover different multi-image skills like co-reference, reasoning, comparing, temporal understanding. We combine Mantis-Instruct with several single-image visual-language datasets to train our model Mantis to handle any interleaved image-text inputs. We evaluate the trained Mantis on five multi-image benchmarks and eight single-image benchmarks. Though only requiring academic-level resources (i.e. 36 hours on 16xA100-40G), Mantis-8B can achieve state-of-the-art performance on all the multi-image benchmarks and beats the existing best multi-image LMM Idefics2-8B by an average of 9 absolute points. We observe that Mantis performs equivalently well on the held-in and held-out evaluation benchmarks. We further evaluate Mantis on single-image benchmarks and demonstrate that Mantis can maintain a strong single-image performance on par with CogVLM and Emu2. Our results are particularly encouraging as it shows that low-cost instruction tuning is indeed much more effective than intensive pre-training in terms of building multi-image LMMs.
AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
Mar 22, 2024
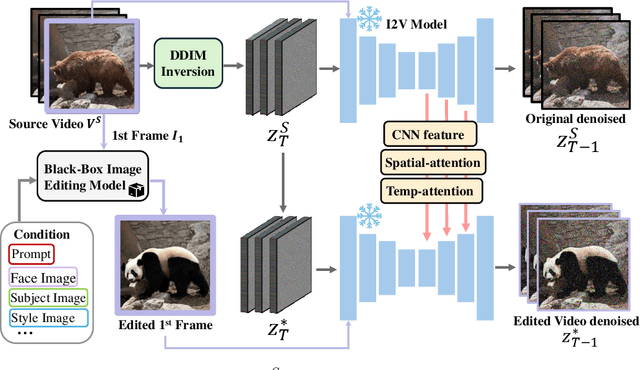
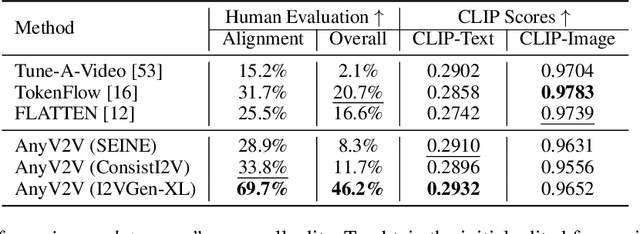

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands. In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection. In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference. On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate the fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.
VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation
Dec 22, 2023



In the rapidly advancing field of conditional image generation research, challenges such as limited explainability lie in effectively evaluating the performance and capabilities of various models. This paper introduces VIESCORE, a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks. VIESCORE leverages general knowledge from Multimodal Large Language Models (MLLMs) as the backbone and does not require training or fine-tuning. We evaluate VIESCORE on seven prominent tasks in conditional image tasks and found: (1) VIESCORE (GPT4-v) achieves a high Spearman correlation of 0.3 with human evaluations, while the human-to-human correlation is 0.45. (2) VIESCORE (with open-source MLLM) is significantly weaker than GPT-4v in evaluating synthetic images. (3) VIESCORE achieves a correlation on par with human ratings in the generation tasks but struggles in editing tasks. With these results, we believe VIESCORE shows its great potential to replace human judges in evaluating image synthesis tasks.
ImagenHub: Standardizing the evaluation of conditional image generation models
Oct 17, 2023Recently, a myriad of conditional image generation and editing models have been developed to serve different downstream tasks, including text-to-image generation, text-guided image editing, subject-driven image generation, control-guided image generation, etc. However, we observe huge inconsistencies in experimental conditions: datasets, inference, and evaluation metrics - render fair comparisons difficult. This paper proposes ImagenHub, which is a one-stop library to standardize the inference and evaluation of all the conditional image generation models. Firstly, we define seven prominent tasks and curate high-quality evaluation datasets for them. Secondly, we built a unified inference pipeline to ensure fair comparison. Thirdly, we design two human evaluation scores, i.e. Semantic Consistency and Perceptual Quality, along with comprehensive guidelines to evaluate generated images. We train expert raters to evaluate the model outputs based on the proposed metrics. Our human evaluation achieves a high inter-worker agreement of Krippendorff's alpha on 76% models with a value higher than 0.4. We comprehensively evaluated a total of around 30 models and observed three key takeaways: (1) the existing models' performance is generally unsatisfying except for Text-guided Image Generation and Subject-driven Image Generation, with 74% models achieving an overall score lower than 0.5. (2) we examined the claims from published papers and found 83% of them hold with a few exceptions. (3) None of the existing automatic metrics has a Spearman's correlation higher than 0.2 except subject-driven image generation. Moving forward, we will continue our efforts to evaluate newly published models and update our leaderboard to keep track of the progress in conditional image generation.
DreamEdit: Subject-driven Image Editing
Jun 22, 2023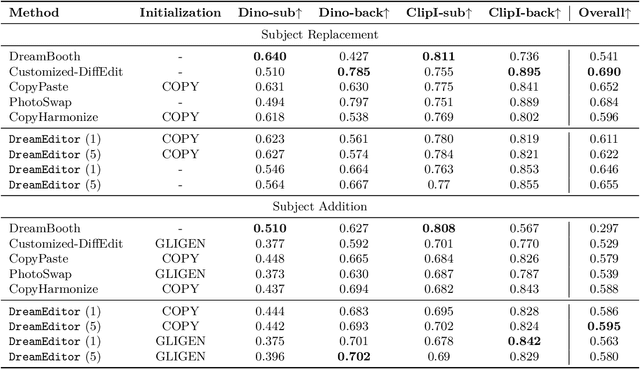

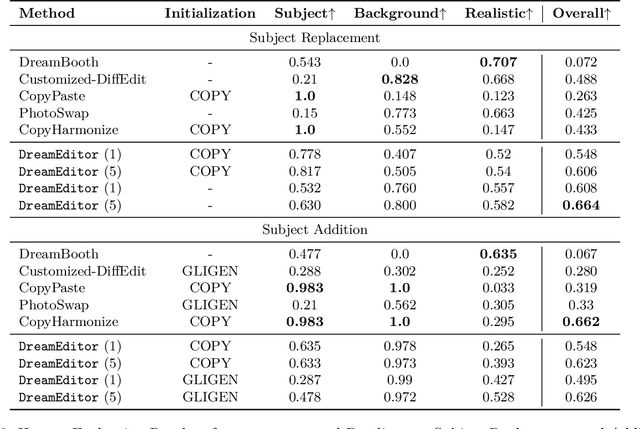

Subject-driven image generation aims at generating images containing customized subjects, which has recently drawn enormous attention from the research community. However, the previous works cannot precisely control the background and position of the target subject. In this work, we aspire to fill the void and propose two novel subject-driven sub-tasks, i.e., Subject Replacement and Subject Addition. The new tasks are challenging in multiple aspects: replacing a subject with a customized one can change its shape, texture, and color, while adding a target subject to a designated position in a provided scene necessitates a context-aware posture. To conquer these two novel tasks, we first manually curate a new dataset DreamEditBench containing 22 different types of subjects, and 440 source images with different difficulty levels. We plan to host DreamEditBench as a platform and hire trained evaluators for standard human evaluation. We also devise an innovative method DreamEditor to resolve these tasks by performing iterative generation, which enables a smooth adaptation to the customized subject. In this project, we conduct automatic and human evaluations to understand the performance of DreamEditor and baselines on DreamEditBench. For Subject Replacement, we found that the existing models are sensitive to the shape and color of the original subject. The model failure rate will dramatically increase when the source and target subjects are highly different. For Subject Addition, we found that the existing models cannot easily blend the customized subjects into the background smoothly, leading to noticeable artifacts in the generated image. We hope DreamEditBench can become a standard platform to enable future investigations toward building more controllable subject-driven image editing. Our project homepage is https://dreameditbenchteam.github.io/.