 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiSciBench: A Hierarchical Multi-disciplinary Benchmark for Scientific Intelligence from Reading to Discovery
Dec 28, 2025The rapid advancement of large language models (LLMs) and multimodal foundation models has sparked growing interest in their potential for scientific research. However, scientific intelligence encompasses a broad spectrum of abilities ranging from understanding fundamental knowledge to conducting creative discovery, and existing benchmarks remain fragmented. Most focus on narrow tasks and fail to reflect the hierarchical and multi-disciplinary nature of real scientific inquiry. We introduce \textbf{HiSciBench}, a hierarchical benchmark designed to evaluate foundation models across five levels that mirror the complete scientific workflow: \textit{Scientific Literacy} (L1), \textit{Literature Parsing} (L2), \textit{Literature-based Question Answering} (L3), \textit{Literature Review Generation} (L4), and \textit{Scientific Discovery} (L5). HiSciBench contains 8,735 carefully curated instances spanning six major scientific disciplines, including mathematics, physics, chemistry, biology, geography, and astronomy, and supports multimodal inputs including text, equations, figures, and tables, as well as cross-lingual evaluation. Unlike prior benchmarks that assess isolated abilities, HiSciBench provides an integrated, dependency-aware framework that enables detailed diagnosis of model capabilities across different stages of scientific reasoning. Comprehensive evaluations of leading models, including GPT-5, DeepSeek-R1, and several multimodal systems, reveal substantial performance gaps: while models achieve up to 69\% accuracy on basic literacy tasks, performance declines sharply to 25\% on discovery-level challenges. HiSciBench establishes a new standard for evaluating scientific Intelligence and offers actionable insights for developing models that are not only more capable but also more reliable. The benchmark will be publicly released to facilitate future research.
Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning
Aug 16, 2024


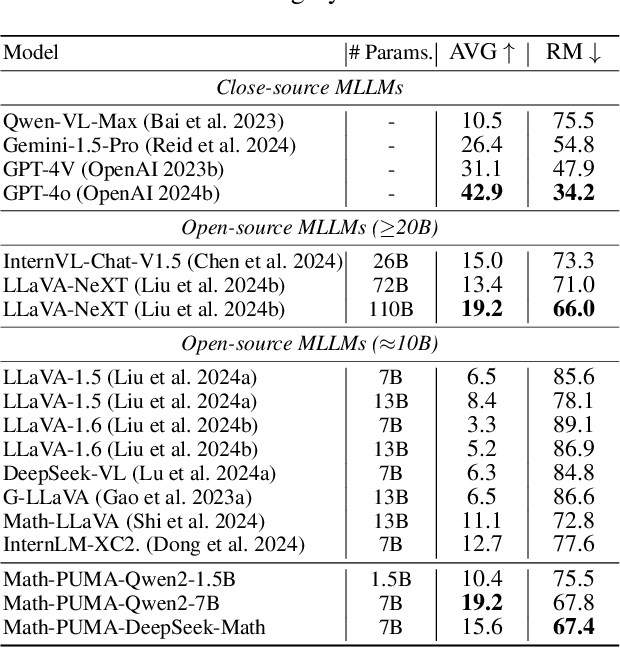
Multimodal Large Language Models (MLLMs) excel in solving text-based mathematical problems, but they struggle with mathematical diagrams since they are primarily trained on natural scene images. For humans, visual aids generally enhance problem-solving, but MLLMs perform worse as information shifts from textual to visual modality. This decline is mainly due to their shortcomings in aligning images and text. To tackle aforementioned challenges, we propose Math-PUMA, a methodology focused on Progressive Upward Multimodal Alignment. This approach is designed to improve the mathematical reasoning skills of MLLMs through a three-stage training process, with the second stage being the critical alignment stage. We first enhance the language model's mathematical reasoning capabilities with extensive set of textual mathematical problems. We then construct a multimodal dataset with varying degrees of textual and visual information, creating data pairs by presenting each problem in at least two forms. By leveraging the Kullback-Leibler (KL) divergence of next-token prediction distributions to align visual and textual modalities, consistent problem-solving abilities are ensured. Finally, we utilize multimodal instruction tuning for MLLMs with high-quality multimodal data. Experimental results on multiple mathematical reasoning benchmarks demonstrate that the MLLMs trained with Math-PUMA surpass most open-source MLLMs. Our approach effectively narrows the performance gap for problems presented in different modalities.
ImagenHub: Standardizing the evaluation of conditional image generation models
Oct 17, 2023Recently, a myriad of conditional image generation and editing models have been developed to serve different downstream tasks, including text-to-image generation, text-guided image editing, subject-driven image generation, control-guided image generation, etc. However, we observe huge inconsistencies in experimental conditions: datasets, inference, and evaluation metrics - render fair comparisons difficult. This paper proposes ImagenHub, which is a one-stop library to standardize the inference and evaluation of all the conditional image generation models. Firstly, we define seven prominent tasks and curate high-quality evaluation datasets for them. Secondly, we built a unified inference pipeline to ensure fair comparison. Thirdly, we design two human evaluation scores, i.e. Semantic Consistency and Perceptual Quality, along with comprehensive guidelines to evaluate generated images. We train expert raters to evaluate the model outputs based on the proposed metrics. Our human evaluation achieves a high inter-worker agreement of Krippendorff's alpha on 76% models with a value higher than 0.4. We comprehensively evaluated a total of around 30 models and observed three key takeaways: (1) the existing models' performance is generally unsatisfying except for Text-guided Image Generation and Subject-driven Image Generation, with 74% models achieving an overall score lower than 0.5. (2) we examined the claims from published papers and found 83% of them hold with a few exceptions. (3) None of the existing automatic metrics has a Spearman's correlation higher than 0.2 except subject-driven image generation. Moving forward, we will continue our efforts to evaluate newly published models and update our leaderboard to keep track of the progress in conditional image generation.