 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecEdit: Training-Free Acceleration for Diffusion based Image Editing via Semantic Locking
May 04, 2026Diffusion-based image editing offers strong semantic controllability, but remains computationally expensive due to iterative high-resolution denoising over all spatial tokens. Dynamic-resolution sampling reduces this cost by performing early steps at reduced resolution. However, existing approaches prioritize upsampling using low-level heuristics such as edge detection or channel variance, which are weakly aligned with editing semantics and may lead to structural inconsistency. Moreover, spatial regions are often upsampled without verifying whether semantic modification is actually required, resulting in redundant high-resolution computation and accumulated errors. Therefore, we propose SpecEdit, a training-free dynamic-resolution framework tailored for diffusion-based image editing. SpecEdit follows a draft-and-verify scheme: a low-resolution draft first estimates the semantic outcome, after which token-level discrepancies are used to identify edit-relevant tokens for high-resolution denoising, while the remaining tokens stay at a coarse resolution. Experiments on Qwen-Image-Edit and FLUX.1-Kontext-dev demonstrate up to 10x and 7x acceleration, while maintaining strong quality. SpecEdit is complementary to step distillation and other acceleration techniques, achieving up to 13x speedup when combined with existing methods. Our code is in supplementary material and will be released on GitHub.
GUI-ARP: Enhancing Grounding with Adaptive Region Perception for GUI Agents
Sep 19, 2025Existing GUI grounding methods often struggle with fine-grained localization in high-resolution screenshots. To address this, we propose GUI-ARP, a novel framework that enables adaptive multi-stage inference. Equipped with the proposed Adaptive Region Perception (ARP) and Adaptive Stage Controlling (ASC), GUI-ARP dynamically exploits visual attention for cropping task-relevant regions and adapts its inference strategy, performing a single-stage inference for simple cases and a multi-stage analysis for more complex scenarios. This is achieved through a two-phase training pipeline that integrates supervised fine-tuning with reinforcement fine-tuning based on Group Relative Policy Optimization (GRPO). Extensive experiments demonstrate that the proposed GUI-ARP achieves state-of-the-art performance on challenging GUI grounding benchmarks, with a 7B model reaching 60.8% accuracy on ScreenSpot-Pro and 30.9% on UI-Vision benchmark. Notably, GUI-ARP-7B demonstrates strong competitiveness against open-source 72B models (UI-TARS-72B at 38.1%) and proprietary models.
TGPO: Tree-Guided Preference Optimization for Robust Web Agent Reinforcement Learning
Sep 19, 2025With the rapid advancement of large language models and vision-language models, employing large models as Web Agents has become essential for automated web interaction. However, training Web Agents with reinforcement learning faces critical challenges including credit assignment misallocation, prohibitively high annotation costs, and reward sparsity. To address these issues, we propose Tree-Guided Preference Optimization (TGPO), an offline reinforcement learning framework that proposes a tree-structured trajectory representation merging semantically identical states across trajectories to eliminate label conflicts. Our framework incorporates a Process Reward Model that automatically generates fine-grained rewards through subgoal progress, redundancy detection, and action verification. Additionally, a dynamic weighting mechanism prioritizes high-impact decision points during training. Experiments on Online-Mind2Web and our self-constructed C-WebShop datasets demonstrate that TGPO significantly outperforms existing methods, achieving higher success rates with fewer redundant steps.
The Escalator Problem: Identifying Implicit Motion Blindness in AI for Accessibility
Aug 11, 2025Multimodal Large Language Models (MLLMs) hold immense promise as assistive technologies for the blind and visually impaired (BVI) community. However, we identify a critical failure mode that undermines their trustworthiness in real-world applications. We introduce the Escalator Problem -- the inability of state-of-the-art models to perceive an escalator's direction of travel -- as a canonical example of a deeper limitation we term Implicit Motion Blindness. This blindness stems from the dominant frame-sampling paradigm in video understanding, which, by treating videos as discrete sequences of static images, fundamentally struggles to perceive continuous, low-signal motion. As a position paper, our contribution is not a new model but rather to: (I) formally articulate this blind spot, (II) analyze its implications for user trust, and (III) issue a call to action. We advocate for a paradigm shift from purely semantic recognition towards robust physical perception and urge the development of new, human-centered benchmarks that prioritize safety, reliability, and the genuine needs of users in dynamic environments.
Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning
Aug 16, 2024


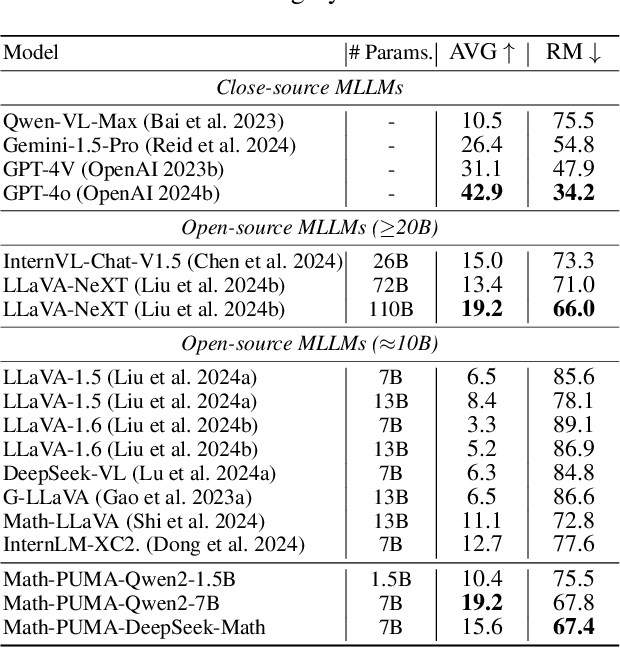
Multimodal Large Language Models (MLLMs) excel in solving text-based mathematical problems, but they struggle with mathematical diagrams since they are primarily trained on natural scene images. For humans, visual aids generally enhance problem-solving, but MLLMs perform worse as information shifts from textual to visual modality. This decline is mainly due to their shortcomings in aligning images and text. To tackle aforementioned challenges, we propose Math-PUMA, a methodology focused on Progressive Upward Multimodal Alignment. This approach is designed to improve the mathematical reasoning skills of MLLMs through a three-stage training process, with the second stage being the critical alignment stage. We first enhance the language model's mathematical reasoning capabilities with extensive set of textual mathematical problems. We then construct a multimodal dataset with varying degrees of textual and visual information, creating data pairs by presenting each problem in at least two forms. By leveraging the Kullback-Leibler (KL) divergence of next-token prediction distributions to align visual and textual modalities, consistent problem-solving abilities are ensured. Finally, we utilize multimodal instruction tuning for MLLMs with high-quality multimodal data. Experimental results on multiple mathematical reasoning benchmarks demonstrate that the MLLMs trained with Math-PUMA surpass most open-source MLLMs. Our approach effectively narrows the performance gap for problems presented in different modalities.
Fast QTMT Partition for VVC Intra Coding Using U-Net Framework
Apr 06, 2023



Versatile Video Coding (VVC) has significantly increased encoding efficiency at the expense of numerous complex coding tools, particularly the flexible Quad-Tree plus Multi-type Tree (QTMT) block partition. This paper proposes a deep learning-based algorithm applied in fast QTMT partition for VVC intra coding. Our solution greatly reduces encoding time by early termination of less-likely intra prediction and partitions with negligible BD-BR increase. Firstly, a redesigned U-Net is recommended as the network's fundamental framework. Next, we design a Quality Parameter (QP) fusion network to regulate the effect of QPs on the partition results. Finally, we adopt a refined post-processing strategy to better balance encoding performance and complexity. Experimental results demonstrate that our solution outperforms the state-of-the-art works with a complexity reduction of 44.74% to 68.76% and a BD-BR increase of 0.60% to 2.33%.
Probabilistic prediction of the heave motions of a semi-submersible by a deep learning problem model
Oct 09, 2021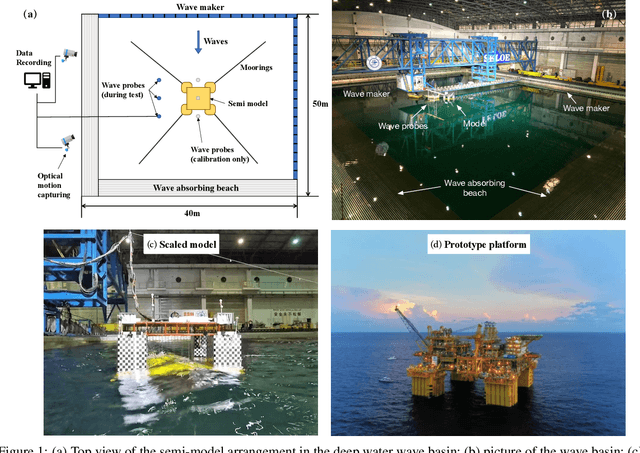
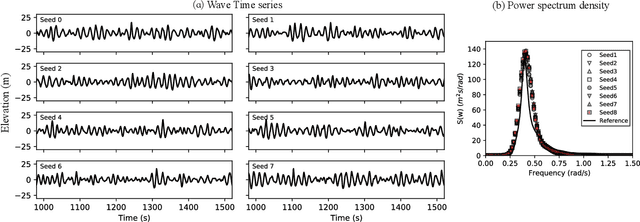
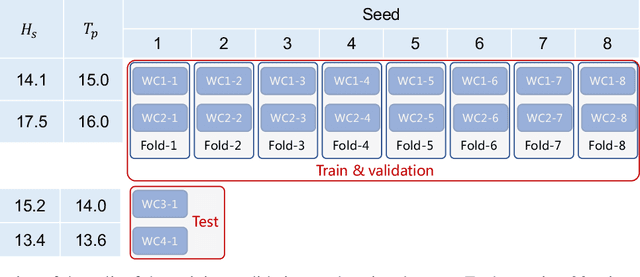
The real-time motion prediction of a floating offshore platform refers to forecasting its motions in the following one- or two-wave cycles, which helps improve the performance of a motion compensation system and provides useful early warning information. In this study, we extend a deep learning (DL) model, which could predict the heave and surge motions of a floating semi-submersible 20 to 50 seconds ahead with good accuracy, to quantify its uncertainty of the predictive time series with the help of the dropout technique. By repeating the inference several times, it is found that the collection of the predictive time series is a Gaussian process (GP). The DL model with dropout learned a kernel inside, and the learning procedure was similar to GP regression. Adding noise into training data could help the model to learn more robust features from the training data, thereby leading to a better performance on test data with a wide noise level range. This study extends the understanding of the DL model to predict the wave excited motions of an offshore platform.
Predicting heave and surge motions of a semi-submersible with neural networks
Jul 31, 2020


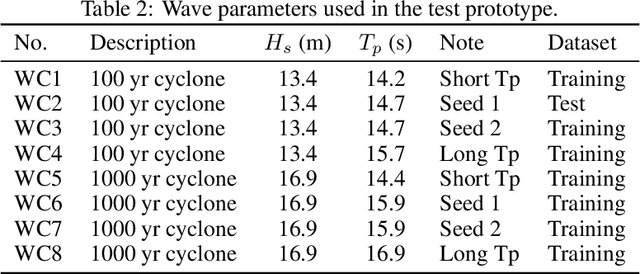
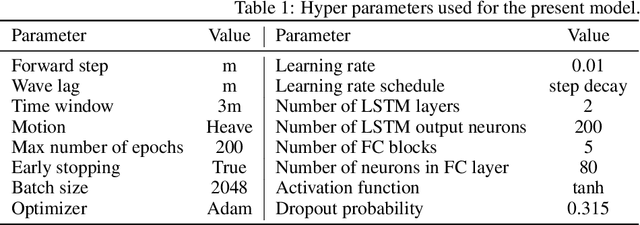
Real-time motion prediction of a vessel or a floating platform can help to improve the performance of motion compensation systems. It can also provide useful early-warning information for offshore operations that are critical with regard to motion. In this study, a long short-term memory (LSTM) -based machine learning model was developed to predict heave and surge motions of a semi-submersible. The training and test data came from a model test carried out in the deep-water ocean basin, at Shanghai Jiao Tong University, China. The motion and measured waves were fed into LSTM cells and then went through serval fully connected (FC) layers to obtain the prediction. With the help of measured waves, the prediction extended 46.5 s into future with an average accuracy close to 90%. Using a noise-extended dataset, the trained model effectively worked with a noise level up to 0.8. As a further step, the model could predict motions only based on the motion itself. Based on sensitive studies on the architectures of the model, guidelines for the construction of the machine learning model are proposed. The proposed LSTM model shows a strong ability to predict vessel wave-excited motions.