 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Adaptive Muon: Accelerating LLM Pretraining with NSR-Modulated and Variance-Scaled Momentum
Jan 21, 2026Large Language Models (LLMs) achieve competitive performance across diverse natural language processing (NLP) tasks, yet pretraining is computationally demanding, making optimizer efficiency an important practical consideration. Muon accelerates LLM pretraining via orthogonal momentum updates that serve as a matrix analogue of the element-wise sign operator. Motivated by the recent perspective that Adam is a variance-adaptive sign update algorithm, we propose two variants of Muon, Muon-NSR and Muon-VS, which apply variance-adaptive normalization to momentum before orthogonalization. Muon-NSR applies noise-to-signal ratio (NSR) modulation, while Muon-VS performs variance-based scaling without introducing additional hyperparameters. Experiments on GPT-2 and LLaMA pretraining demonstrate that our proposed methods accelerate convergence and consistently achieve lower validation loss than both competitive, well-tuned AdamW and Muon baselines. For example, on the LLaMA-1.2B model, Muon-NSR and Muon-VS reduce the iterations required to reach the target validation loss by $1.36\times$ relative to the well-tuned Muon following the recent benchmark.
GRACE: Designing Generative Face Video Codec via Agile Hardware-Centric Workflow
Nov 12, 2025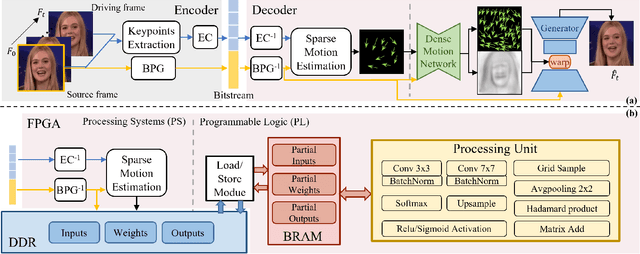


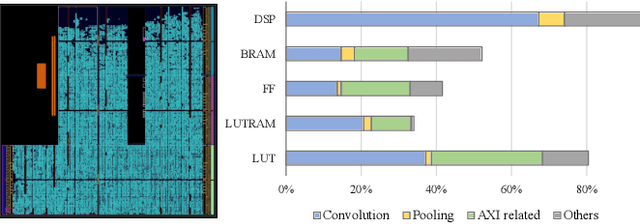
The Animation-based Generative Codec (AGC) is an emerging paradigm for talking-face video compression. However, deploying its intricate decoder on resource and power-constrained edge devices presents challenges due to numerous parameters, the inflexibility to adapt to dynamically evolving algorithms, and the high power consumption induced by extensive computations and data transmission. This paper for the first time proposes a novel field programmable gate arrays (FPGAs)-oriented AGC deployment scheme for edge-computing video services. Initially, we analyze the AGC algorithm and employ network compression methods including post-training static quantization and layer fusion techniques. Subsequently, we design an overlapped accelerator utilizing the co-processor paradigm to perform computations through software-hardware co-design. The hardware processing unit comprises engines such as convolution, grid sampling, upsample, etc. Parallelization optimization strategies like double-buffered pipelines and loop unrolling are employed to fully exploit the resources of FPGA. Ultimately, we establish an AGC FPGA prototype on the PYNQ-Z1 platform using the proposed scheme, achieving \textbf{24.9$\times$} and \textbf{4.1$\times$} higher energy efficiency against commercial Central Processing Unit (CPU) and Graphic Processing Unit (GPU), respectively. Specifically, only \textbf{11.7} microjoules ($\upmu$J) are required for one pixel reconstructed by this FPGA system.
Unicorn: Unified Neural Image Compression with One Number Reconstruction
Dec 11, 2024Prevalent lossy image compression schemes can be divided into: 1) explicit image compression (EIC), including traditional standards and neural end-to-end algorithms; 2) implicit image compression (IIC) based on implicit neural representations (INR). The former is encountering impasses of either leveling off bitrate reduction at a cost of tremendous complexity while the latter suffers from excessive smoothing quality as well as lengthy decoder models. In this paper, we propose an innovative paradigm, which we dub \textbf{Unicorn} (\textbf{U}nified \textbf{N}eural \textbf{I}mage \textbf{C}ompression with \textbf{O}ne \textbf{N}number \textbf{R}econstruction). By conceptualizing the images as index-image pairs and learning the inherent distribution of pairs in a subtle neural network model, Unicorn can reconstruct a visually pleasing image from a randomly generated noise with only one index number. The neural model serves as the unified decoder of images while the noises and indexes corresponds to explicit representations. As a proof of concept, we propose an effective and efficient prototype of Unicorn based on latent diffusion models with tailored model designs. Quantitive and qualitative experimental results demonstrate that our prototype achieves significant bitrates reduction compared with EIC and IIC algorithms. More impressively, benefitting from the unified decoder, our compression ratio escalates as the quantity of images increases. We envision that more advanced model designs will endow Unicorn with greater potential in image compression. We will release our codes in \url{https://github.com/uniqzheng/Unicorn-Laduree}.
Video Quality Assessment: A Comprehensive Survey
Dec 04, 2024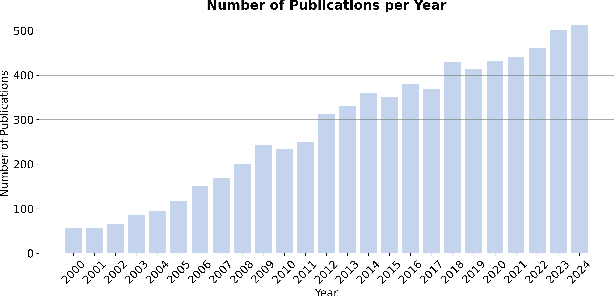
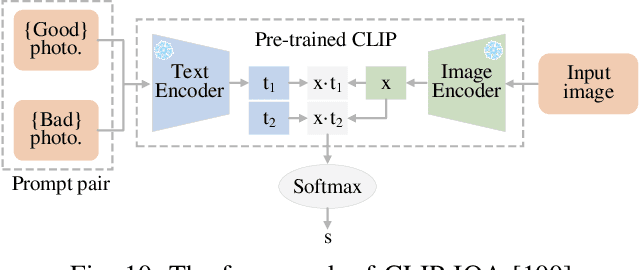
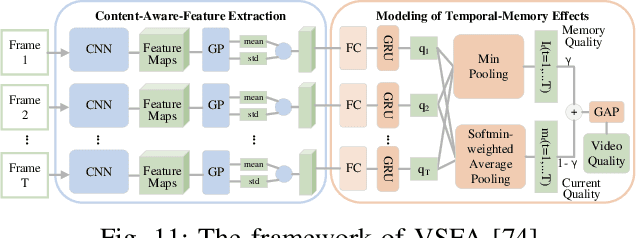
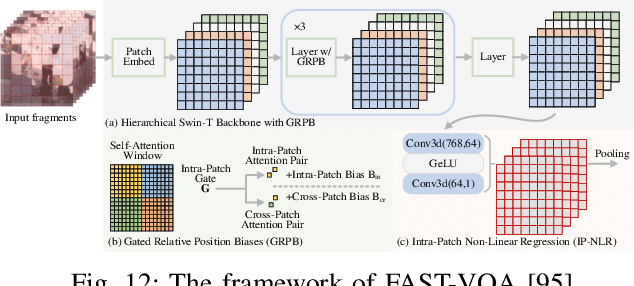
Video quality assessment (VQA) is an important processing task, aiming at predicting the quality of videos in a manner highly consistent with human judgments of perceived quality. Traditional VQA models based on natural image and/or video statistics, which are inspired both by models of projected images of the real world and by dual models of the human visual system, deliver only limited prediction performances on real-world user-generated content (UGC), as exemplified in recent large-scale VQA databases containing large numbers of diverse video contents crawled from the web. Fortunately, recent advances in deep neural networks and Large Multimodality Models (LMMs) have enabled significant progress in solving this problem, yielding better results than prior handcrafted models. Numerous deep learning-based VQA models have been developed, with progress in this direction driven by the creation of content-diverse, large-scale human-labeled databases that supply ground truth psychometric video quality data. Here, we present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.
MWFormer: Multi-Weather Image Restoration Using Degradation-Aware Transformers
Nov 26, 2024



Restoring images captured under adverse weather conditions is a fundamental task for many computer vision applications. However, most existing weather restoration approaches are only capable of handling a specific type of degradation, which is often insufficient in real-world scenarios, such as rainy-snowy or rainy-hazy weather. Towards being able to address these situations, we propose a multi-weather Transformer, or MWFormer for short, which is a holistic vision Transformer that aims to solve multiple weather-induced degradations using a single, unified architecture. MWFormer uses hyper-networks and feature-wise linear modulation blocks to restore images degraded by various weather types using the same set of learned parameters. We first employ contrastive learning to train an auxiliary network that extracts content-independent, distortion-aware feature embeddings that efficiently represent predicted weather types, of which more than one may occur. Guided by these weather-informed predictions, the image restoration Transformer adaptively modulates its parameters to conduct both local and global feature processing, in response to multiple possible weather. Moreover, MWFormer allows for a novel way of tuning, during application, to either a single type of weather restoration or to hybrid weather restoration without any retraining, offering greater controllability than existing methods. Our experimental results on multi-weather restoration benchmarks show that MWFormer achieves significant performance improvements compared to existing state-of-the-art methods, without requiring much computational cost. Moreover, we demonstrate that our methodology of using hyper-networks can be integrated into various network architectures to further boost their performance. The code is available at: https://github.com/taco-group/MWFormer
M3-CVC: Controllable Video Compression with Multimodal Generative Models
Nov 24, 2024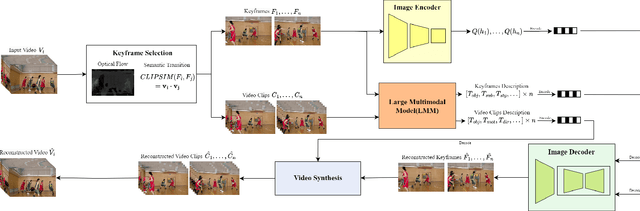
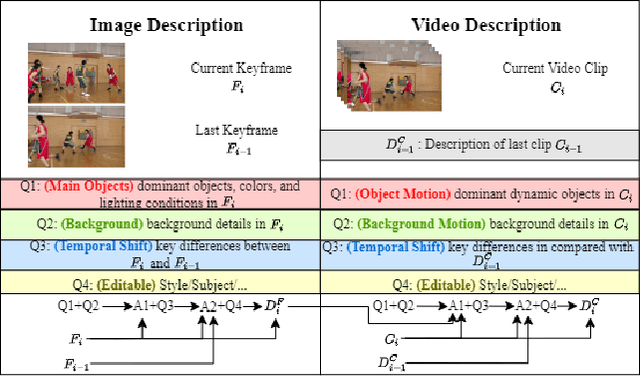
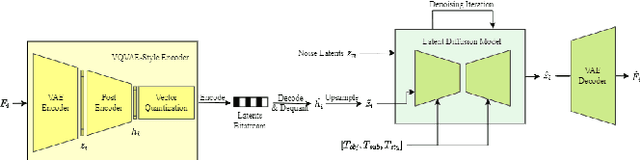
Traditional and neural video codecs commonly encounter limitations in controllability and generality under ultra-low-bitrate coding scenarios. To overcome these challenges, we propose M3-CVC, a controllable video compression framework incorporating multimodal generative models. The framework utilizes a semantic-motion composite strategy for keyframe selection to retain critical information. For each keyframe and its corresponding video clip, a dialogue-based large multimodal model (LMM) approach extracts hierarchical spatiotemporal details, enabling both inter-frame and intra-frame representations for improved video fidelity while enhancing encoding interpretability. M3-CVC further employs a conditional diffusion-based, text-guided keyframe compression method, achieving high fidelity in frame reconstruction. During decoding, textual descriptions derived from LMMs guide the diffusion process to restore the original video's content accurately. Experimental results demonstrate that M3-CVC significantly outperforms the state-of-the-art VVC standard in ultra-low bitrate scenarios, particularly in preserving semantic and perceptual fidelity.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
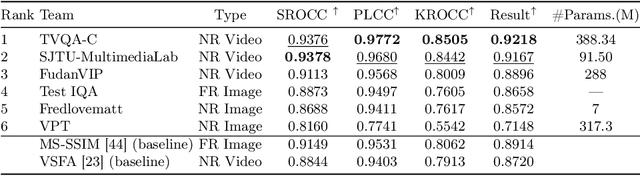
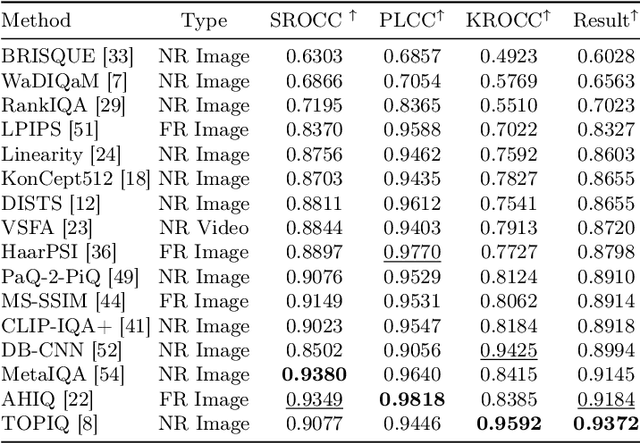
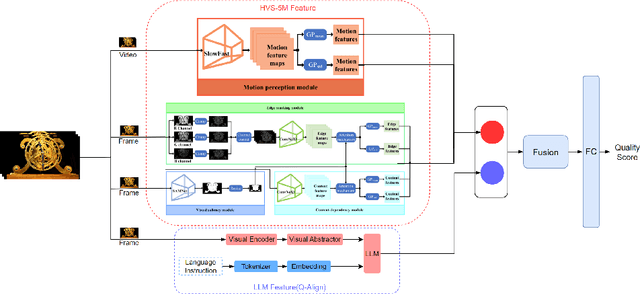
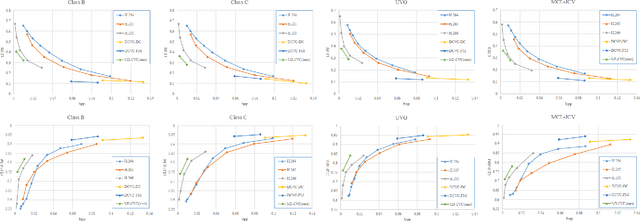
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
Attack and Defense Analysis of Learned Image Compression
Jan 18, 2024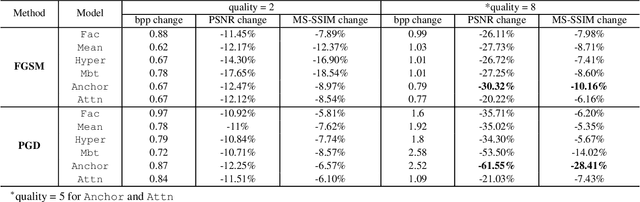

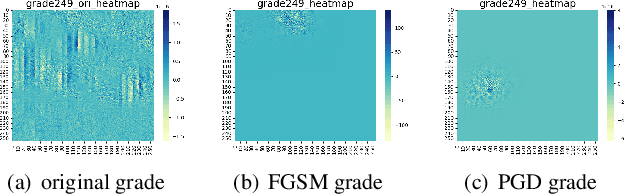
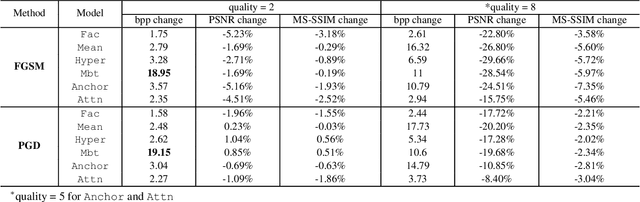
Learned image compression (LIC) is becoming more and more popular these years with its high efficiency and outstanding compression quality. Still, the practicality against modified inputs added with specific noise could not be ignored. White-box attacks such as FGSM and PGD use only gradient to compute adversarial images that mislead LIC models to output unexpected results. Our experiments compare the effects of different dimensions such as attack methods, models, qualities, and targets, concluding that in the worst case, there is a 61.55% decrease in PSNR or a 19.15 times increase in bit rate under the PGD attack. To improve their robustness, we conduct adversarial training by adding adversarial images into the training datasets, which obtains a 95.52% decrease in the R-D cost of the most vulnerable LIC model. We further test the robustness of H.266, whose better performance on reconstruction quality extends its possibility to defend one-step or iterative adversarial attacks.
Fast QTMT Partition for VVC Intra Coding Using U-Net Framework
Apr 06, 2023Versatile Video Coding (VVC) has significantly increased encoding efficiency at the expense of numerous complex coding tools, particularly the flexible Quad-Tree plus Multi-type Tree (QTMT) block partition. This paper proposes a deep learning-based algorithm applied in fast QTMT partition for VVC intra coding. Our solution greatly reduces encoding time by early termination of less-likely intra prediction and partitions with negligible BD-BR increase. Firstly, a redesigned U-Net is recommended as the network's fundamental framework. Next, we design a Quality Parameter (QP) fusion network to regulate the effect of QPs on the partition results. Finally, we adopt a refined post-processing strategy to better balance encoding performance and complexity. Experimental results demonstrate that our solution outperforms the state-of-the-art works with a complexity reduction of 44.74% to 68.76% and a BD-BR increase of 0.60% to 2.33%.
An Error-Surface-Based Fractional Motion Estimation Algorithm and Hardware Implementation for VVC
Feb 13, 2023Versatile Video Coding (VVC) introduces more coding tools to improve compression efficiency compared to its predecessor High Efficiency Video Coding (HEVC). For inter-frame coding, Fractional Motion Estimation (FME) still has a high computational effort, which limits the real-time processing capability of the video encoder. In this context, this paper proposes an error-surface-based FME algorithm and the corresponding hardware implementation. The algorithm creates an error surface constructed by the Rate-Distortion (R-D) cost of the integer motion vector (IMV) and its neighbors. This method requires no iteration and interpolation, thus reducing the area and power consumption and increasing the throughput of the hardware. The experimental results show that the corresponding BDBR loss is only 0.47% compared to VTM 16.0 in LD-P configuration. The hardware implementation was synthesized using GF 28nm process. It can support 13 different sizes of CU varying from 128x128 to 8x8. The measured throughput can reach 4K@30fps at 400MHz, with a gate count of 192k and power consumption of 12.64 mW. And the throughput can reach 8K@30fps at 631MHz when only quadtree is searched. To the best of our knowledge, this work is the first hardware architecture for VVC FME with interpolation-free strategies