 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation
May 29, 2025Large Vision-Language Models (LVLMs) have made remarkable strides in multimodal tasks such as visual question answering, visual grounding, and complex reasoning. However, they remain limited by static training data, susceptibility to hallucinations, and inability to verify claims against up-to-date, external evidence, compromising their performance in dynamic real-world applications. Retrieval-Augmented Generation (RAG) offers a practical solution to mitigate these challenges by allowing the LVLMs to access large-scale knowledge databases via retrieval mechanisms, thereby grounding model outputs in factual, contextually relevant information. Here in this paper, we conduct the first systematic dissection of the multimodal RAG pipeline for LVLMs, explicitly investigating (1) the retrieval phase: on the modality configurations and retrieval strategies, (2) the re-ranking stage: on strategies to mitigate positional biases and improve the relevance of retrieved evidence, and (3) the generation phase: we further investigate how to best integrate retrieved candidates into the final generation process. Finally, we extend to explore a unified agentic framework that integrates re-ranking and generation through self-reflection, enabling LVLMs to select relevant evidence and suppress irrelevant context dynamically. Our full-stack exploration of RAG for LVLMs yields substantial insights, resulting in an average performance boost of 5% without any fine-tuning.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Video Quality Assessment: A Comprehensive Survey
Dec 04, 2024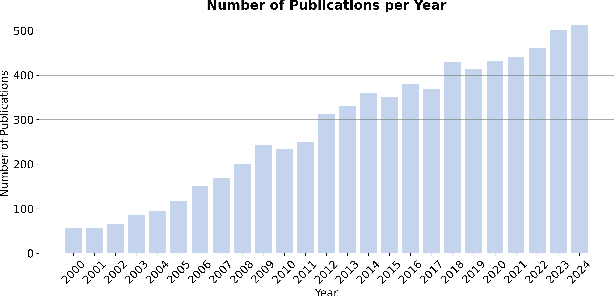
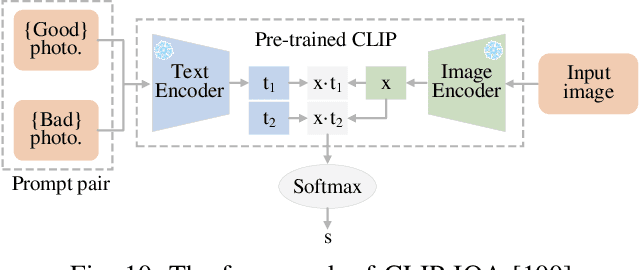
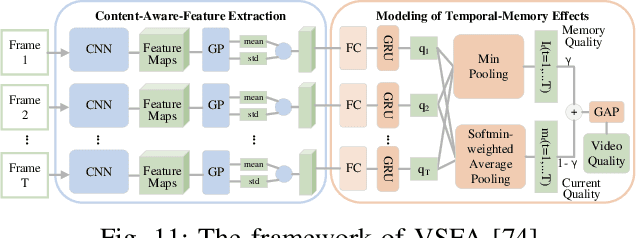
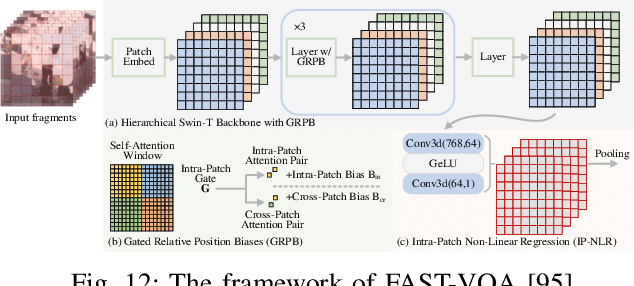
Video quality assessment (VQA) is an important processing task, aiming at predicting the quality of videos in a manner highly consistent with human judgments of perceived quality. Traditional VQA models based on natural image and/or video statistics, which are inspired both by models of projected images of the real world and by dual models of the human visual system, deliver only limited prediction performances on real-world user-generated content (UGC), as exemplified in recent large-scale VQA databases containing large numbers of diverse video contents crawled from the web. Fortunately, recent advances in deep neural networks and Large Multimodality Models (LMMs) have enabled significant progress in solving this problem, yielding better results than prior handcrafted models. Numerous deep learning-based VQA models have been developed, with progress in this direction driven by the creation of content-diverse, large-scale human-labeled databases that supply ground truth psychometric video quality data. Here, we present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.
The OpenCDA Open-source Ecosystem for Cooperative Driving Automation Research
Jan 26, 2023



Advances in Single-vehicle intelligence of automated driving have encountered significant challenges because of limited capabilities in perception and interaction with complex traffic environments. Cooperative Driving Automation~(CDA) has been considered a pivotal solution to next-generation automated driving and intelligent transportation. Though CDA has attracted much attention from both academia and industry, exploration of its potential is still in its infancy. In industry, companies tend to build their in-house data collection pipeline and research tools to tailor their needs and protect intellectual properties. Reinventing the wheels, however, wastes resources and limits the generalizability of the developed approaches since no standardized benchmarks exist. On the other hand, in academia, due to the absence of real-world traffic data and computation resources, researchers often investigate CDA topics in simplified and mostly simulated environments, restricting the possibility of scaling the research outputs to real-world scenarios. Therefore, there is an urgent need to establish an open-source ecosystem~(OSE) to address the demands of different communities for CDA research, particularly in the early exploratory research stages, and provide the bridge to ensure an integrated development and testing pipeline that diverse communities can share. In this paper, we introduce the OpenCDA research ecosystem, a unified OSE integrated with a model zoo, a suite of driving simulators at various resolutions, large-scale real-world and simulated datasets, complete development toolkits for benchmark training/testing, and a scenario database/generator. We also demonstrate the effectiveness of OpenCDA OSE through example use cases, including cooperative 3D LiDAR detection, cooperative merge, cooperative camera-based map prediction, and adversarial scenario generation.
Regression or Classification? New Methods to Evaluate No-Reference Picture and Video Quality Models
Jan 30, 2021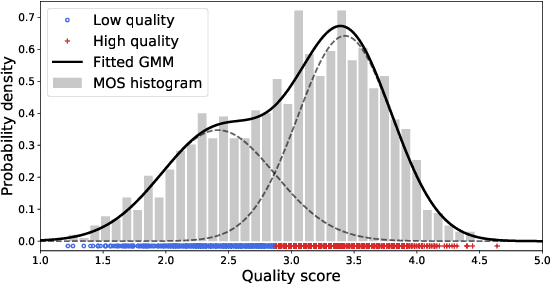
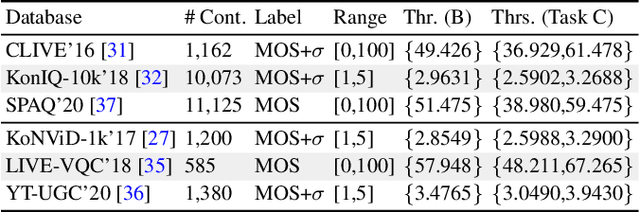
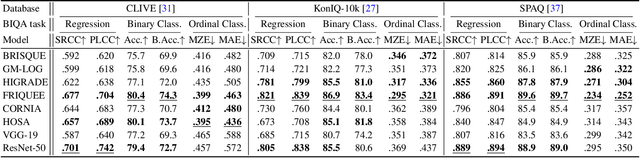
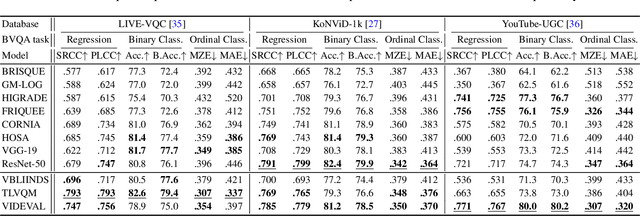
Video and image quality assessment has long been projected as a regression problem, which requires predicting a continuous quality score given an input stimulus. However, recent efforts have shown that accurate quality score regression on real-world user-generated content (UGC) is a very challenging task. To make the problem more tractable, we propose two new methods - binary, and ordinal classification - as alternatives to evaluate and compare no-reference quality models at coarser levels. Moreover, the proposed new tasks convey more practical meaning on perceptually optimized UGC transcoding, or for preprocessing on media processing platforms. We conduct a comprehensive benchmark experiment of popular no-reference quality models on recent in-the-wild picture and video quality datasets, providing reliable baselines for both evaluation methods to support further studies. We hope this work promotes coarse-grained perceptual modeling and its applications to efficient UGC processing.
A Comparative Evaluation of Temporal Pooling Methods for Blind Video Quality Assessment
Feb 25, 2020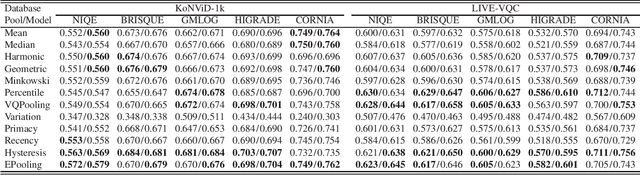
Many objective video quality assessment (VQA) algorithms include a key step of temporal pooling of frame-level quality scores. However, less attention has been paid to studying the relative efficiencies of different pooling methods on no-reference (blind) VQA. Here we conduct a large-scale comparative evaluation to assess the capabilities and limitations of multiple temporal pooling strategies on blind VQA of user-generated videos. The study yields insights and general guidance regarding the application and selection of temporal pooling models. In addition, we also propose an ensemble pooling model built on top of high-performing temporal pooling models. Our experimental results demonstrate the relative efficacies of the evaluated temporal pooling models, using several popular VQA algorithms, and evaluated on two recent large-scale natural video quality databases. In addition to the new ensemble model, we provide a general recipe for applying temporal pooling of frame-based quality predictions.