 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSink-Token-Aware Pruning for Fine-Grained Video Understanding in Efficient Video LLMs
Apr 22, 2026Video Large Language Models (Video LLMs) incur high inference latency due to a large number of visual tokens provided to LLMs. To address this, training-free visual token pruning has emerged as a solution to reduce computational costs; however, existing methods are primarily validated on Multiple-Choice Question Answering (MCQA) benchmarks, where coarse-grained cues often suffice. In this work, we reveal that these methods suffer a sharp performance collapse on fine-grained understanding tasks requiring precise visual grounding, such as hallucination evaluation. To explore this gap, we conduct a systematic analysis and identify sink tokens--semantically uninformative tokens that attract excessive attention--as a key obstacle to fine-grained video understanding. When these sink tokens survive pruning, they distort the model's visual evidence and hinder fine-grained understanding. Motivated by these insights, we propose Sink-Token-aware Pruning (SToP), a simple yet effective plug-and-play method that introduces a sink score to quantify each token's tendency to behave as a sink and applies this score to existing spatial and temporal pruning methods to suppress them, thereby enhancing video understanding. To validate the effectiveness of SToP, we apply it to state-of-the-art pruning methods (VisionZip, FastVid, and Holitom) and evaluate it across diverse benchmarks covering hallucination, open-ended generation, compositional reasoning, and MCQA. Our results demonstrate that SToP significantly boosts performance, even when pruning up to 90% of visual tokens.
Vectorizing the Trie: Efficient Constrained Decoding for LLM-based Generative Retrieval on Accelerators
Feb 26, 2026Generative retrieval has emerged as a powerful paradigm for LLM-based recommendation. However, industrial recommender systems often benefit from restricting the output space to a constrained subset of items based on business logic (e.g. enforcing content freshness or product category), which standard autoregressive decoding cannot natively support. Moreover, existing constrained decoding methods that make use of prefix trees (Tries) incur severe latency penalties on hardware accelerators (TPUs/GPUs). In this work, we introduce STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding), an efficient and scalable constrained decoding technique designed specifically for high-throughput LLM-based generative retrieval on TPUs/GPUs. By flattening the prefix tree into a static Compressed Sparse Row (CSR) matrix, we transform irregular tree traversals into fully vectorized sparse matrix operations, unlocking massive efficiency gains on hardware accelerators. We deploy STATIC on a large-scale industrial video recommendation platform serving billions of users. STATIC produces significant product metric impact with minimal latency overhead (0.033 ms per step and 0.25% of inference time), achieving a 948x speedup over a CPU trie implementation and a 47-1033x speedup over a hardware-accelerated binary-search baseline. Furthermore, the runtime overhead of STATIC remains extremely low across a wide range of practical configurations. To the best of our knowledge, STATIC enables the first production-scale deployment of strictly constrained generative retrieval. In addition, evaluation on academic benchmarks demonstrates that STATIC can considerably improve cold-start performance for generative retrieval. Our code is available at https://github.com/youtube/static-constraint-decoding.
Ultra Fast PDE Solving via Physics Guided Few-step Diffusion
Feb 03, 2026Diffusion-based models have demonstrated impressive accuracy and generalization in solving partial differential equations (PDEs). However, they still face significant limitations, such as high sampling costs and insufficient physical consistency, stemming from their many-step iterative sampling mechanism and lack of explicit physics constraints. To address these issues, we propose Phys-Instruct, a novel physics-guided distillation framework which not only (1) compresses a pre-trained diffusion PDE solver into a few-step generator via matching generator and prior diffusion distributions to enable rapid sampling, but also (2) enhances the physics consistency by explicitly injecting PDE knowledge through a PDE distillation guidance. Physic-Instruct is built upon a solid theoretical foundation, leading to a practical physics-constrained training objective that admits tractable gradients. Across five PDE benchmarks, Phys-Instruct achieves orders-of-magnitude faster inference while reducing PDE error by more than 8 times compared to state-of-the-art diffusion baselines. Moreover, the resulting unconditional student model functions as a compact prior, enabling efficient and physically consistent inference for various downstream conditional tasks. Our results indicate that Phys-Instruct is a novel, effective, and efficient framework for ultra-fast PDE solving powered by deep generative models.
FASA: Frequency-aware Sparse Attention
Feb 03, 2026The deployment of Large Language Models (LLMs) faces a critical bottleneck when handling lengthy inputs: the prohibitive memory footprint of the Key Value (KV) cache. To address this bottleneck, the token pruning paradigm leverages attention sparsity to selectively retain a small, critical subset of tokens. However, existing approaches fall short, with static methods risking irreversible information loss and dynamic strategies employing heuristics that insufficiently capture the query-dependent nature of token importance. We propose FASA, a novel framework that achieves query-aware token eviction by dynamically predicting token importance. FASA stems from a novel insight into RoPE: the discovery of functional sparsity at the frequency-chunk (FC) level. Our key finding is that a small, identifiable subset of "dominant" FCs consistently exhibits high contextual agreement with the full attention head. This provides a robust and computationally free proxy for identifying salient tokens. %making them a powerful and efficient proxy for token importance. Building on this insight, FASA first identifies a critical set of tokens using dominant FCs, and then performs focused attention computation solely on this pruned subset. % Since accessing only a small fraction of the KV cache, FASA drastically lowers memory bandwidth requirements and computational cost. Across a spectrum of long-context tasks, from sequence modeling to complex CoT reasoning, FASA consistently outperforms all token-eviction baselines and achieves near-oracle accuracy, demonstrating remarkable robustness even under constraint budgets. Notably, on LongBench-V1, FASA reaches nearly 100\% of full-KV performance when only keeping 256 tokens, and achieves 2.56$\times$ speedup using just 18.9\% of the cache on AIME24.
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
mRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation
May 29, 2025Large Vision-Language Models (LVLMs) have made remarkable strides in multimodal tasks such as visual question answering, visual grounding, and complex reasoning. However, they remain limited by static training data, susceptibility to hallucinations, and inability to verify claims against up-to-date, external evidence, compromising their performance in dynamic real-world applications. Retrieval-Augmented Generation (RAG) offers a practical solution to mitigate these challenges by allowing the LVLMs to access large-scale knowledge databases via retrieval mechanisms, thereby grounding model outputs in factual, contextually relevant information. Here in this paper, we conduct the first systematic dissection of the multimodal RAG pipeline for LVLMs, explicitly investigating (1) the retrieval phase: on the modality configurations and retrieval strategies, (2) the re-ranking stage: on strategies to mitigate positional biases and improve the relevance of retrieved evidence, and (3) the generation phase: we further investigate how to best integrate retrieved candidates into the final generation process. Finally, we extend to explore a unified agentic framework that integrates re-ranking and generation through self-reflection, enabling LVLMs to select relevant evidence and suppress irrelevant context dynamically. Our full-stack exploration of RAG for LVLMs yields substantial insights, resulting in an average performance boost of 5% without any fine-tuning.
User Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
Feb 18, 2025



The emergence of large Vision Language Models (VLMs) has broadened the scope and capabilities of single-modal Large Language Models (LLMs) by integrating visual modalities, thereby unlocking transformative cross-modal applications in a variety of real-world scenarios. Despite their impressive performance, VLMs are prone to significant hallucinations, particularly in the form of cross-modal inconsistencies. Building on the success of Reinforcement Learning from Human Feedback (RLHF) in aligning LLMs, recent advancements have focused on applying direct preference optimization (DPO) on carefully curated datasets to mitigate these issues. Yet, such approaches typically introduce preference signals in a brute-force manner, neglecting the crucial role of visual information in the alignment process. In this paper, we introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications. We release all the code in https://github.com/taco-group/Re-Align.
Train Once, Deploy Anywhere: Matryoshka Representation Learning for Multimodal Recommendation
Sep 25, 2024



Despite recent advancements in language and vision modeling, integrating rich multimodal knowledge into recommender systems continues to pose significant challenges. This is primarily due to the need for efficient recommendation, which requires adaptive and interactive responses. In this study, we focus on sequential recommendation and introduce a lightweight framework called full-scale Matryoshka representation learning for multimodal recommendation (fMRLRec). Our fMRLRec captures item features at different granularities, learning informative representations for efficient recommendation across multiple dimensions. To integrate item features from diverse modalities, fMRLRec employs a simple mapping to project multimodal item features into an aligned feature space. Additionally, we design an efficient linear transformation that embeds smaller features into larger ones, substantially reducing memory requirements for large-scale training on recommendation data. Combined with improved state space modeling techniques, fMRLRec scales to different dimensions and only requires one-time training to produce multiple models tailored to various granularities. We demonstrate the effectiveness and efficiency of fMRLRec on multiple benchmark datasets, which consistently achieves superior performance over state-of-the-art baseline methods.
Auto-Encoding or Auto-Regression? A Reality Check on Causality of Self-Attention-Based Sequential Recommenders
Jun 04, 2024

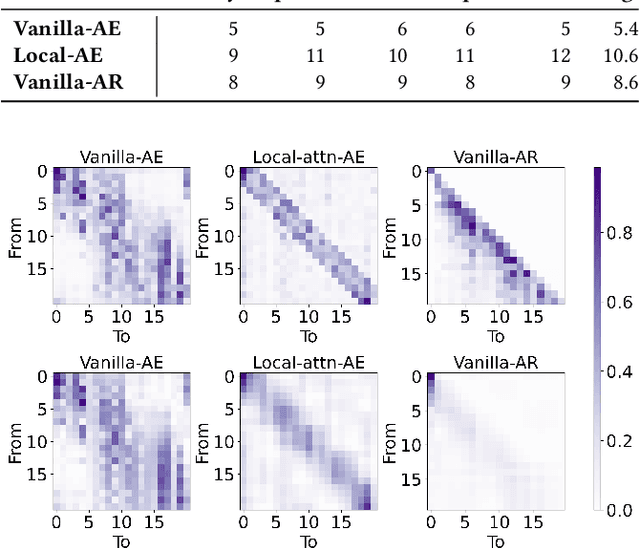

The comparison between Auto-Encoding (AE) and Auto-Regression (AR) has become an increasingly important topic with recent advances in sequential recommendation. At the heart of this discussion lies the comparison of BERT4Rec and SASRec, which serve as representative AE and AR models for self-attentive sequential recommenders. Yet the conclusion of this debate remains uncertain due to: (1) the lack of fair and controlled environments for experiments and evaluations; and (2) the presence of numerous confounding factors w.r.t. feature selection, modeling choices and optimization algorithms. In this work, we aim to answer this question by conducting a series of controlled experiments. We start by tracing the AE/AR debate back to its origin through a systematic re-evaluation of SASRec and BERT4Rec, discovering that AR models generally surpass AE models in sequential recommendation. In addition, we find that AR models further outperforms AE models when using a customized design space that includes additional features, modeling approaches and optimization techniques. Furthermore, the performance advantage of AR models persists in the broader HuggingFace transformer ecosystems. Lastly, we provide potential explanations and insights into AE/AR performance from two key perspectives: low-rank approximation and inductive bias. We make our code and data available at https://github.com/yueqirex/ModSAR