 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Models, Big Results: Achieving Superior Intent Extraction through Decomposition
Sep 15, 2025Understanding user intents from UI interaction trajectories remains a challenging, yet crucial, frontier in intelligent agent development. While massive, datacenter-based, multi-modal large language models (MLLMs) possess greater capacity to handle the complexities of such sequences, smaller models which can run on-device to provide a privacy-preserving, low-cost, and low-latency user experience, struggle with accurate intent inference. We address these limitations by introducing a novel decomposed approach: first, we perform structured interaction summarization, capturing key information from each user action. Second, we perform intent extraction using a fine-tuned model operating on the aggregated summaries. This method improves intent understanding in resource-constrained models, even surpassing the base performance of large MLLMs.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
FRAPPÉ: A Post-Processing Framework for Group Fairness Regularization
Dec 05, 2023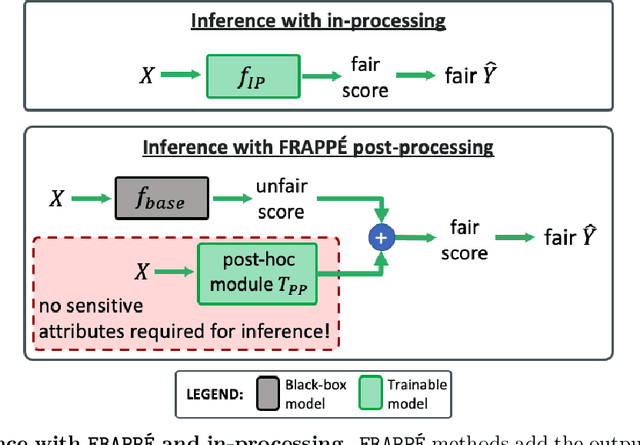
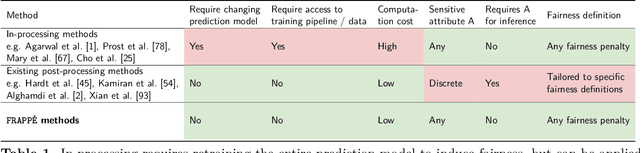
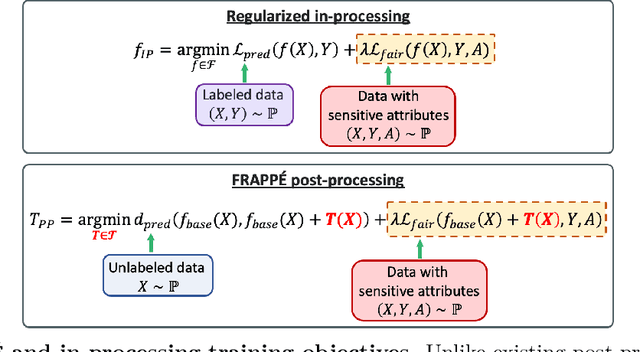
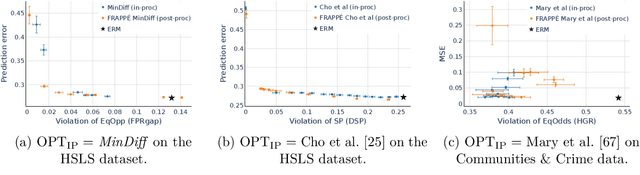
Post-processing mitigation techniques for group fairness generally adjust the decision threshold of a base model in order to improve fairness. Methods in this family exhibit several advantages that make them appealing in practice: post-processing requires no access to the model training pipeline, is agnostic to the base model architecture, and offers a reduced computation cost compared to in-processing. Despite these benefits, existing methods face other challenges that limit their applicability: they require knowledge of the sensitive attributes at inference time and are oftentimes outperformed by in-processing. In this paper, we propose a general framework to transform any in-processing method with a penalized objective into a post-processing procedure. The resulting method is specifically designed to overcome the aforementioned shortcomings of prior post-processing approaches. Furthermore, we show theoretically and through extensive experiments on real-world data that the resulting post-processing method matches or even surpasses the fairness-error trade-off offered by the in-processing counterpart.
Learning from Negative User Feedback and Measuring Responsiveness for Sequential Recommenders
Aug 23, 2023


Sequential recommenders have been widely used in industry due to their strength in modeling user preferences. While these models excel at learning a user's positive interests, less attention has been paid to learning from negative user feedback. Negative user feedback is an important lever of user control, and comes with an expectation that recommenders should respond quickly and reduce similar recommendations to the user. However, negative feedback signals are often ignored in the training objective of sequential retrieval models, which primarily aim at predicting positive user interactions. In this work, we incorporate explicit and implicit negative user feedback into the training objective of sequential recommenders in the retrieval stage using a "not-to-recommend" loss function that optimizes for the log-likelihood of not recommending items with negative feedback. We demonstrate the effectiveness of this approach using live experiments on a large-scale industrial recommender system. Furthermore, we address a challenge in measuring recommender responsiveness to negative feedback by developing a counterfactual simulation framework to compare recommender responses between different user actions, showing improved responsiveness from the modeling change.
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021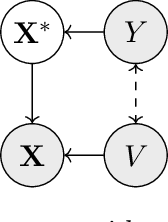

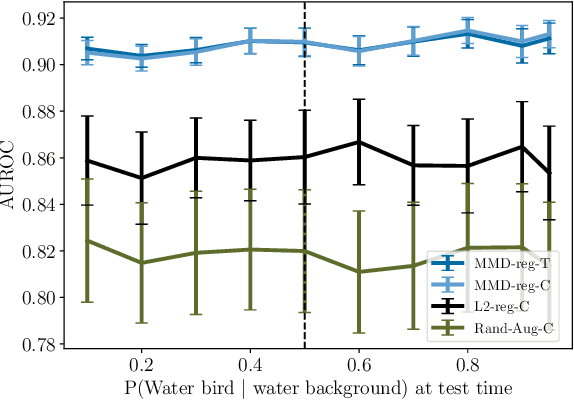
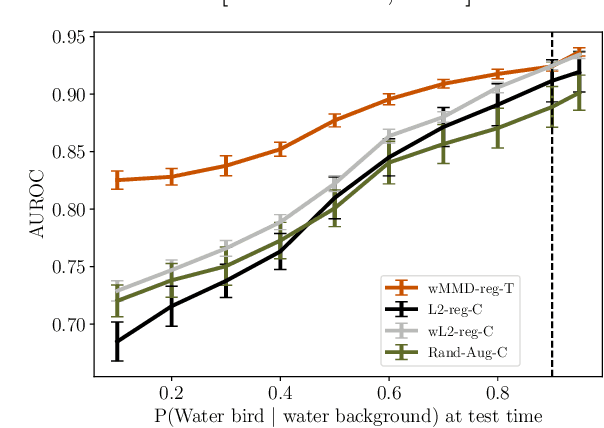
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
Measuring Recommender System Effects with Simulated Users
Jan 12, 2021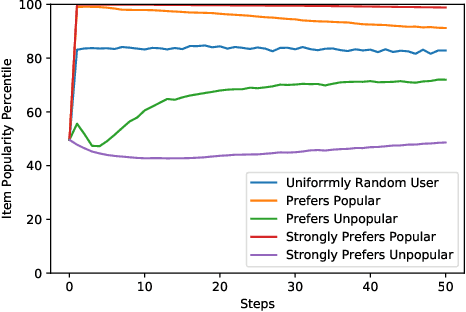

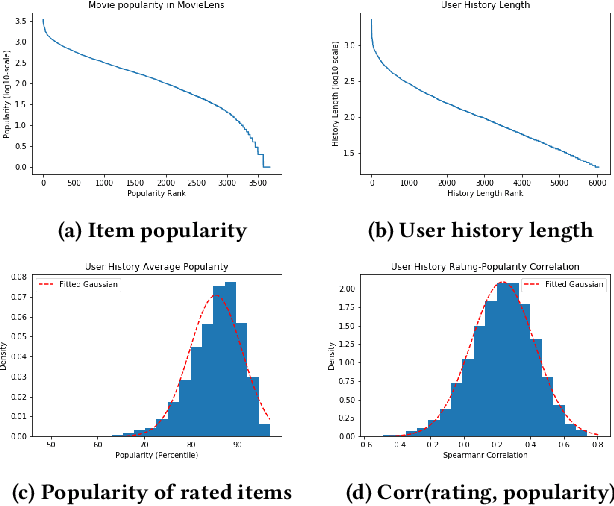
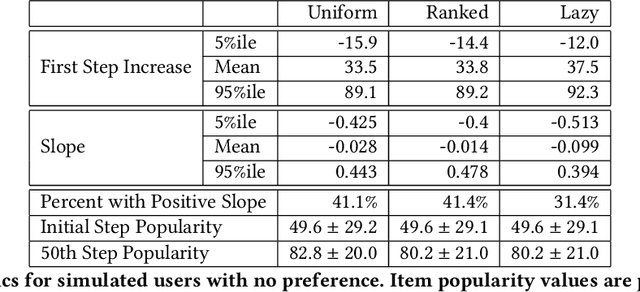
Imagine a food recommender system -- how would we check if it is \emph{causing} and fostering unhealthy eating habits or merely reflecting users' interests? How much of a user's experience over time with a recommender is caused by the recommender system's choices and biases, and how much is based on the user's preferences and biases? Popularity bias and filter bubbles are two of the most well-studied recommender system biases, but most of the prior research has focused on understanding the system behavior in a single recommendation step. How do these biases interplay with user behavior, and what types of user experiences are created from repeated interactions? In this work, we offer a simulation framework for measuring the impact of a recommender system under different types of user behavior. Using this simulation framework, we can (a) isolate the effect of the recommender system from the user preferences, and (b) examine how the system performs not just on average for an "average user" but also the extreme experiences under atypical user behavior. As part of the simulation framework, we propose a set of evaluation metrics over the simulations to understand the recommender system's behavior. Finally, we present two empirical case studies -- one on traditional collaborative filtering in MovieLens and one on a large-scale production recommender system -- to understand how popularity bias manifests over time.
Fair treatment allocations in social networks
Nov 01, 2019

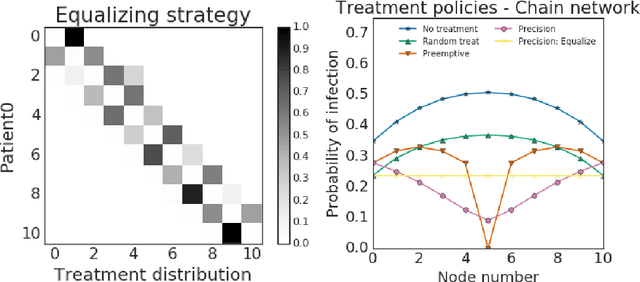
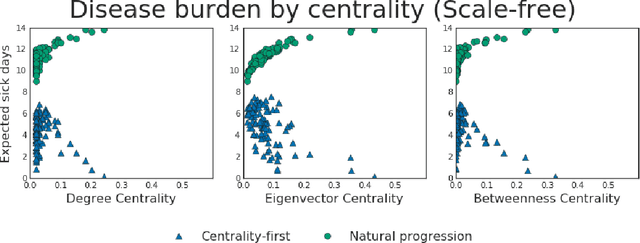
Simulations of infectious disease spread have long been used to understand how epidemics evolve and how to effectively treat them. However, comparatively little attention has been paid to understanding the fairness implications of different treatment strategies -- that is, how might such strategies distribute the expected disease burden differentially across various subgroups or communities in the population? In this work, we define the precision disease control problem -- the problem of optimally allocating vaccines in a social network in a step-by-step fashion -- and we use the ML Fairness Gym to simulate epidemic control and study it from both an efficiency and fairness perspective. We then present an exploratory analysis of several different environments and discuss the fairness implications of different treatment strategies.
Benefits of Overparameterization in Single-Layer Latent Variable Generative Models
Jun 28, 2019
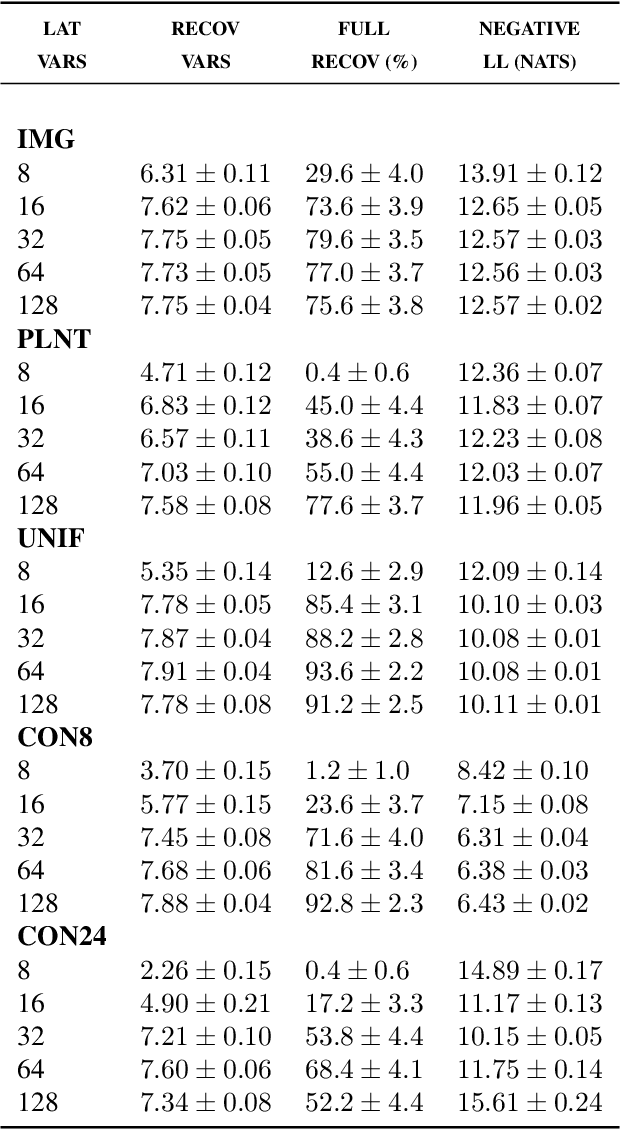
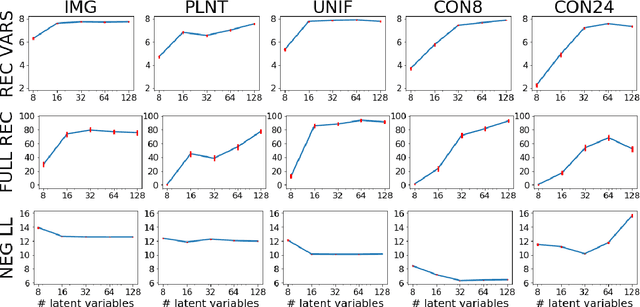
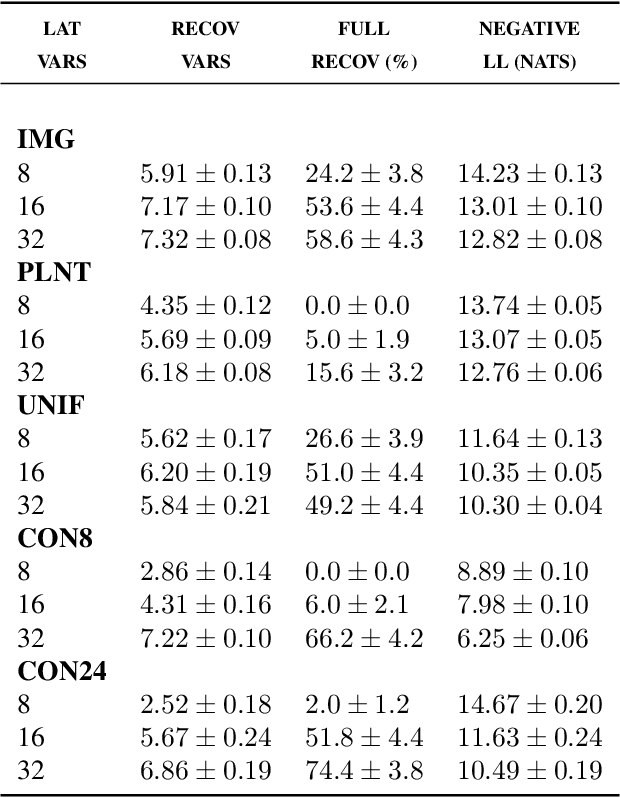
One of the most surprising and exciting discoveries in supervising learning was the benefit of overparametrization (i.e. training a very large model) to improving the optimization landscape of a problem, with minimal effect on statistical performance (i.e. generalization). In contrast, unsupervised settings have been under-explored, despite the fact that it has been observed that overparameterization can be helpful as early as Dasgupta & Schulman (2007). In this paper, we perform an exhaustive study of different aspects of overparameterization in unsupervised learning via synthetic and semi-synthetic experiments. We discuss benefits to different metrics of success (held-out log-likelihood, recovering the parameters of the ground-truth model), sensitivity to variations of the training algorithm, and behavior as the amount of overparameterization increases. We find that, when learning using methods such as variational inference, larger models can significantly increase the number of ground truth latent variables recovered.
BriarPatches: Pixel-Space Interventions for Inducing Demographic Parity
Dec 17, 2018
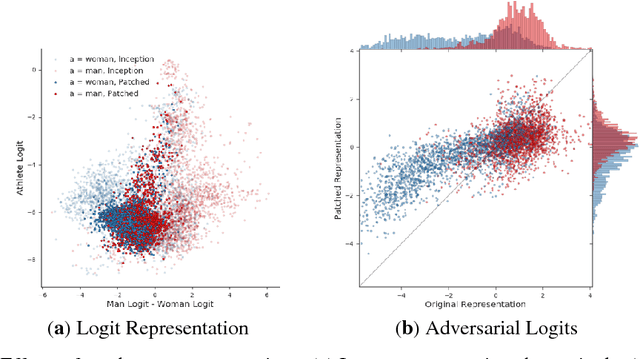
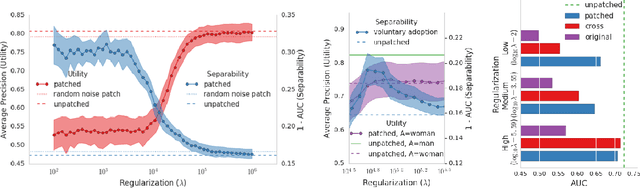
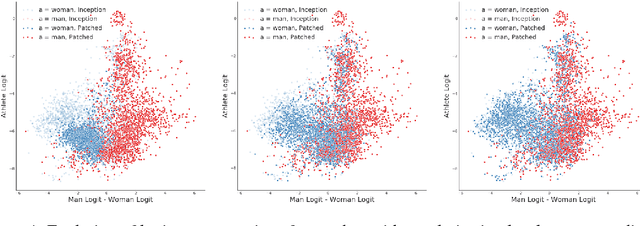
We introduce the BriarPatch, a pixel-space intervention that obscures sensitive attributes from representations encoded in pre-trained classifiers. The patches encourage internal model representations not to encode sensitive information, which has the effect of pushing downstream predictors towards exhibiting demographic parity with respect to the sensitive information. The net result is that these BriarPatches provide an intervention mechanism available at user level, and complements prior research on fair representations that were previously only applicable by model developers and ML experts.
No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World
Nov 22, 2017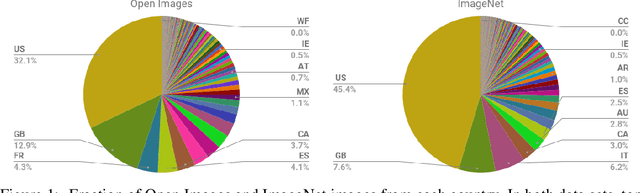
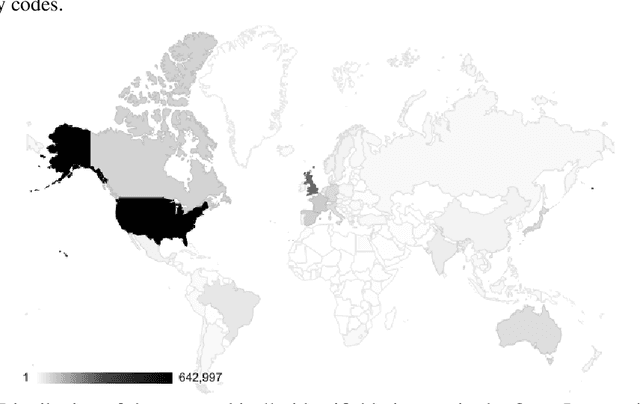
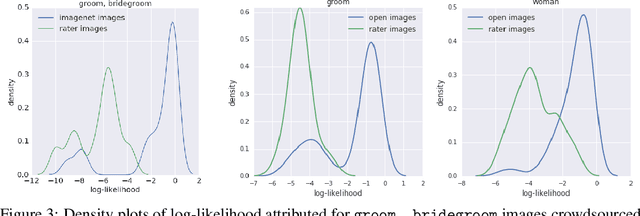
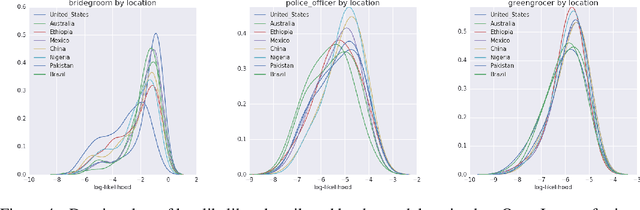
Modern machine learning systems such as image classifiers rely heavily on large scale data sets for training. Such data sets are costly to create, thus in practice a small number of freely available, open source data sets are widely used. We suggest that examining the geo-diversity of open data sets is critical before adopting a data set for use cases in the developing world. We analyze two large, publicly available image data sets to assess geo-diversity and find that these data sets appear to exhibit an observable amerocentric and eurocentric representation bias. Further, we analyze classifiers trained on these data sets to assess the impact of these training distributions and find strong differences in the relative performance on images from different locales. These results emphasize the need to ensure geo-representation when constructing data sets for use in the developing world.