 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Group Fairness in LLM-Based Decisions
Jun 24, 2024



Prompting Large Language Models (LLMs) has created new and interesting means for classifying textual data. While evaluating and remediating group fairness is a well-studied problem in classifier fairness literature, some classical approaches (e.g., regularization) do not carry over, and some new opportunities arise (e.g., prompt-based remediation). We measure fairness of LLM-based classifiers on a toxicity classification task, and empirically show that prompt-based classifiers may lead to unfair decisions. We introduce several remediation techniques and benchmark their fairness and performance trade-offs. We hope our work encourages more research on group fairness in LLM-based classifiers.
Towards A Scalable Solution for Improving Multi-Group Fairness in Compositional Classification
Jul 11, 2023Despite the rich literature on machine learning fairness, relatively little attention has been paid to remediating complex systems, where the final prediction is the combination of multiple classifiers and where multiple groups are present. In this paper, we first show that natural baseline approaches for improving equal opportunity fairness scale linearly with the product of the number of remediated groups and the number of remediated prediction labels, rendering them impractical. We then introduce two simple techniques, called {\em task-overconditioning} and {\em group-interleaving}, to achieve a constant scaling in this multi-group multi-label setup. Our experimental results in academic and real-world environments demonstrate the effectiveness of our proposal at mitigation within this environment.
Fair treatment allocations in social networks
Nov 01, 2019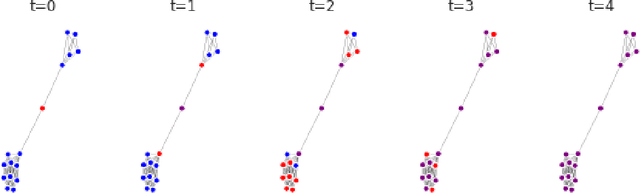

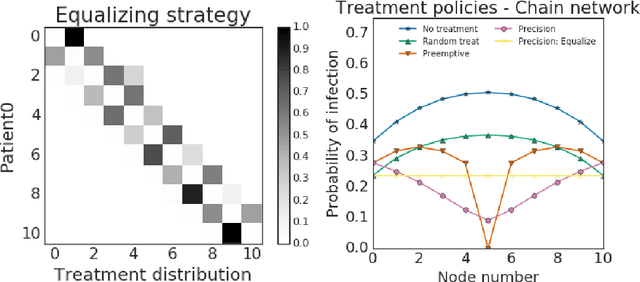
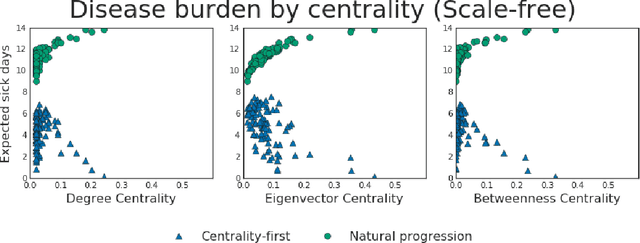
Simulations of infectious disease spread have long been used to understand how epidemics evolve and how to effectively treat them. However, comparatively little attention has been paid to understanding the fairness implications of different treatment strategies -- that is, how might such strategies distribute the expected disease burden differentially across various subgroups or communities in the population? In this work, we define the precision disease control problem -- the problem of optimally allocating vaccines in a social network in a step-by-step fashion -- and we use the ML Fairness Gym to simulate epidemic control and study it from both an efficiency and fairness perspective. We then present an exploratory analysis of several different environments and discuss the fairness implications of different treatment strategies.
Detecting Extrapolation with Local Ensembles
Oct 21, 2019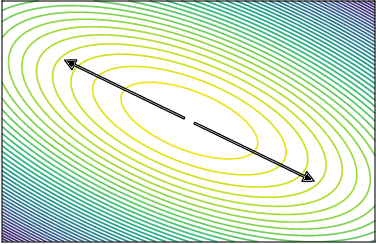
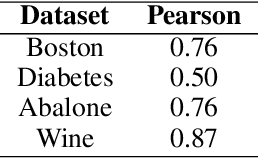
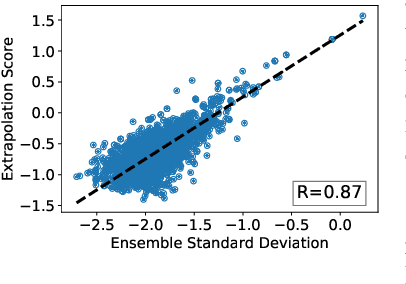
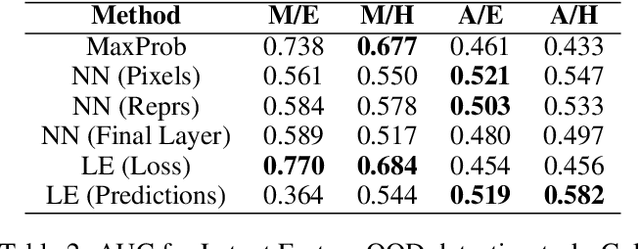
We present local ensembles, a method for detecting extrapolation at test time in a pre-trained model. We focus on underdetermination as a key component of extrapolation: we aim to detect when many possible predictions are consistent with the training data and model class. Our method uses local second-order information to approximate the variance of predictions across an ensemble of models from the same class. We compute this approximation by estimating the norm of the component of a test point's gradient that aligns with the low-curvature directions of the Hessian, and provide a tractable method for estimating this quantity. Experimentally, we show that our method is capable of detecting when a pre-trained model is extrapolating on test data, with applications to out-of-distribution detection, detecting spurious correlates, and active learning.
BriarPatches: Pixel-Space Interventions for Inducing Demographic Parity
Dec 17, 2018
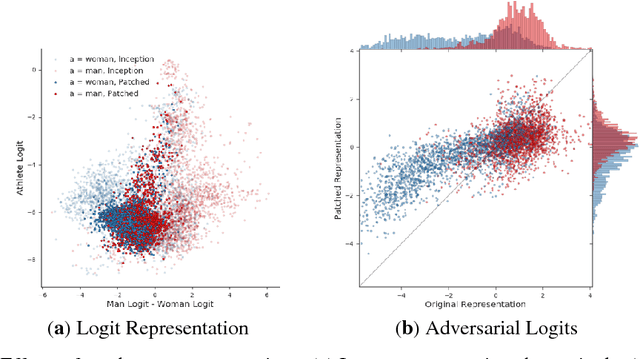
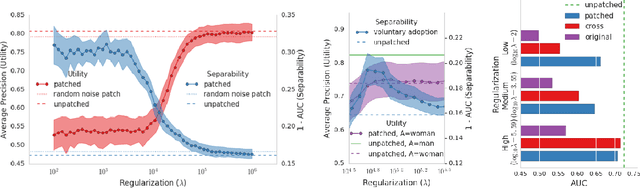
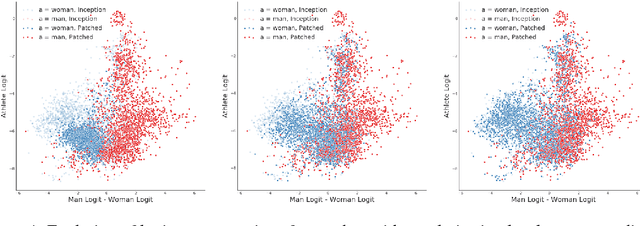
We introduce the BriarPatch, a pixel-space intervention that obscures sensitive attributes from representations encoded in pre-trained classifiers. The patches encourage internal model representations not to encode sensitive information, which has the effect of pushing downstream predictors towards exhibiting demographic parity with respect to the sensitive information. The net result is that these BriarPatches provide an intervention mechanism available at user level, and complements prior research on fair representations that were previously only applicable by model developers and ML experts.
No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World
Nov 22, 2017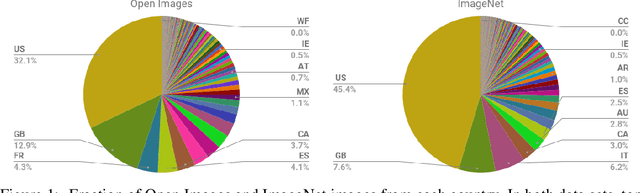
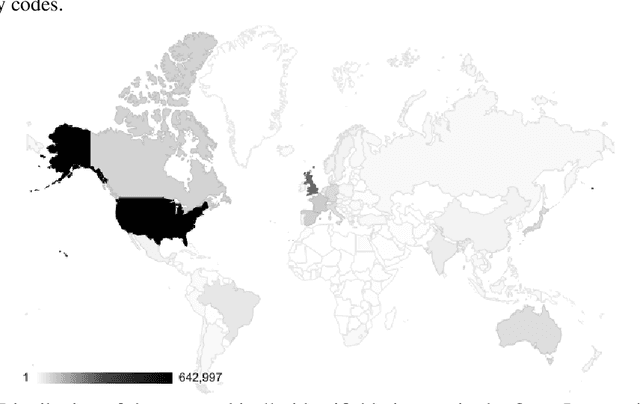
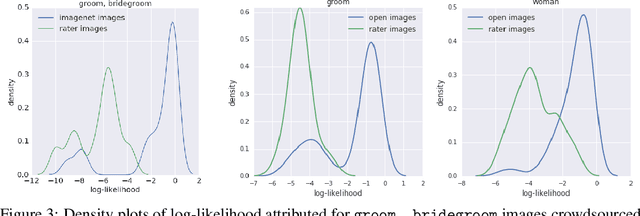
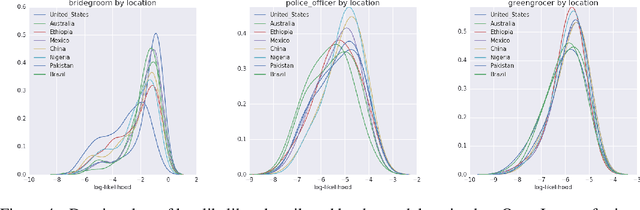
Modern machine learning systems such as image classifiers rely heavily on large scale data sets for training. Such data sets are costly to create, thus in practice a small number of freely available, open source data sets are widely used. We suggest that examining the geo-diversity of open data sets is critical before adopting a data set for use cases in the developing world. We analyze two large, publicly available image data sets to assess geo-diversity and find that these data sets appear to exhibit an observable amerocentric and eurocentric representation bias. Further, we analyze classifiers trained on these data sets to assess the impact of these training distributions and find strong differences in the relative performance on images from different locales. These results emphasize the need to ensure geo-representation when constructing data sets for use in the developing world.
Sparse Diffusion-Convolutional Neural Networks
Oct 26, 2017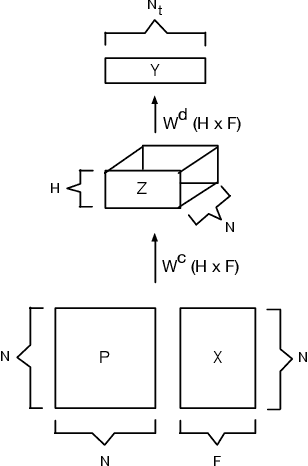
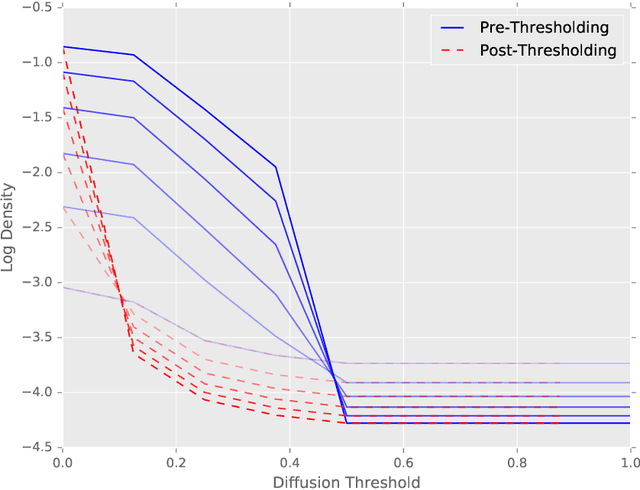
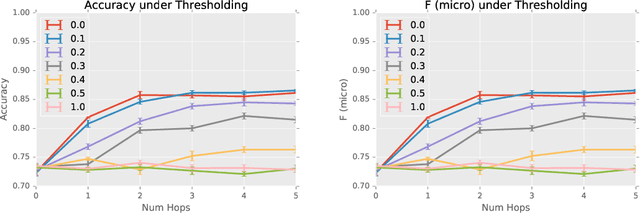
The predictive power and overall computational efficiency of Diffusion-convolutional neural networks make them an attractive choice for node classification tasks. However, a naive dense-tensor-based implementation of DCNNs leads to $\mathcal{O}(N^2)$ memory complexity which is prohibitive for large graphs. In this paper, we introduce a simple method for thresholding input graphs that provably reduces memory requirements of DCNNs to O(N) (i.e. linear in the number of nodes in the input) without significantly affecting predictive performance.
Diffusion-Convolutional Neural Networks
Jul 08, 2016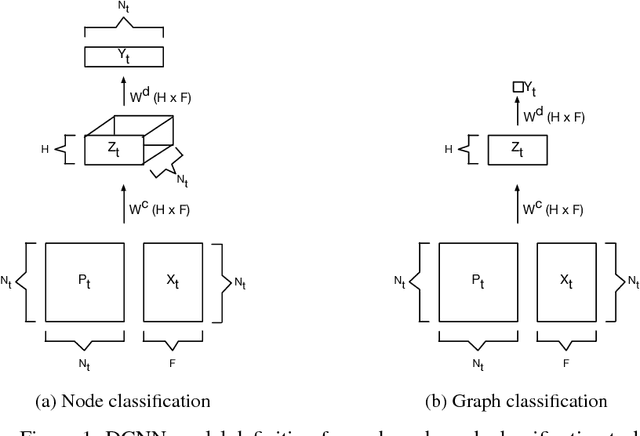
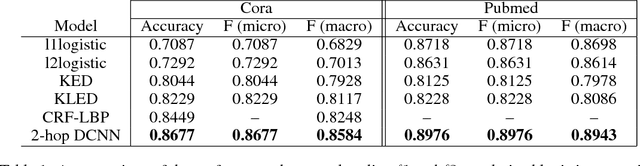
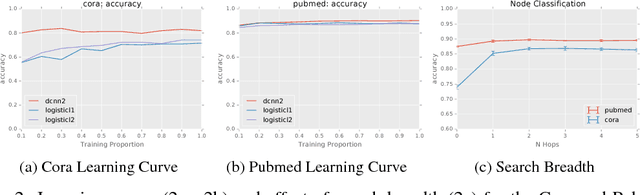
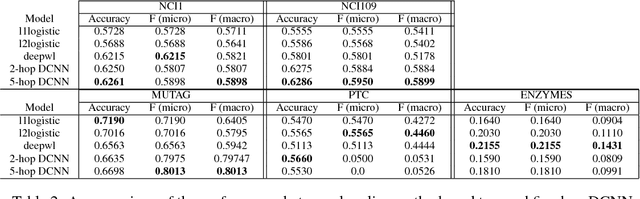
We present diffusion-convolutional neural networks (DCNNs), a new model for graph-structured data. Through the introduction of a diffusion-convolution operation, we show how diffusion-based representations can be learned from graph-structured data and used as an effective basis for node classification. DCNNs have several attractive qualities, including a latent representation for graphical data that is invariant under isomorphism, as well as polynomial-time prediction and learning that can be represented as tensor operations and efficiently implemented on the GPU. Through several experiments with real structured datasets, we demonstrate that DCNNs are able to outperform probabilistic relational models and kernel-on-graph methods at relational node classification tasks.
Learning to Generate Networks
Nov 10, 2014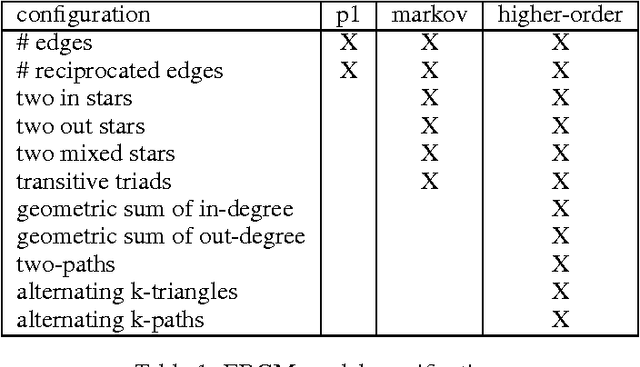
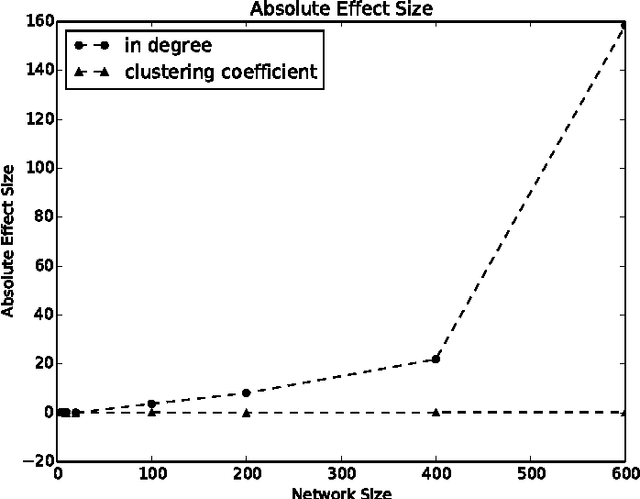
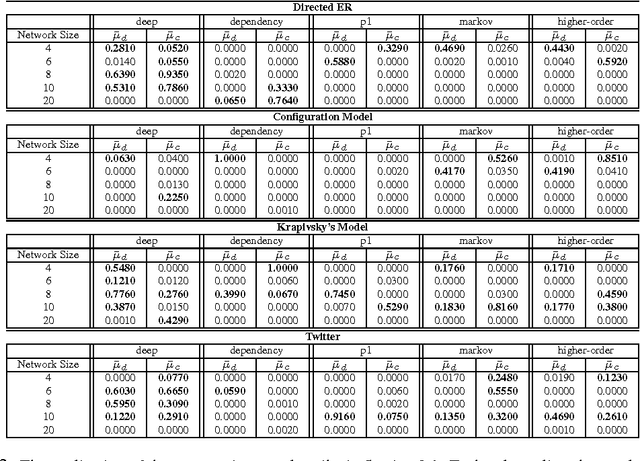
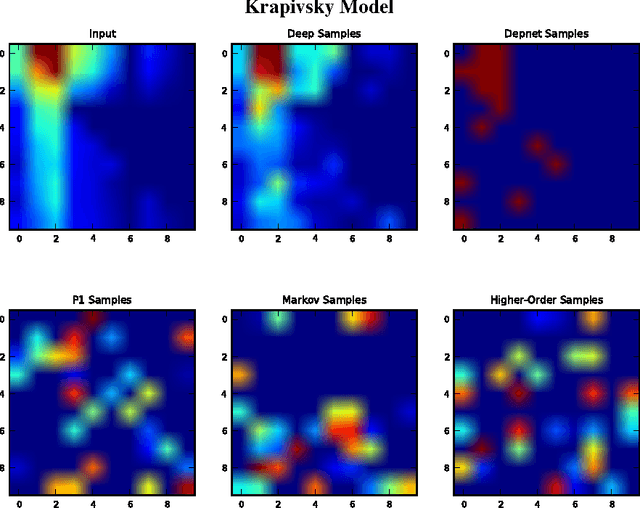
We investigate the problem of learning to generate complex networks from data. Specifically, we consider whether deep belief networks, dependency networks, and members of the exponential random graph family can learn to generate networks whose complex behavior is consistent with a set of input examples. We find that the deep model is able to capture the complex behavior of small networks, but that no model is able capture this behavior for networks with more than a handful of nodes.