 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
Auto-Evaluation with Few Labels through Post-hoc Regression
Nov 19, 2024


Continually evaluating large generative models provides a unique challenge. Often, human annotations are necessary to evaluate high-level properties of these models (e.g. in text or images). However, collecting human annotations of samples can be resource intensive, and using other machine learning systems to provide the annotations, or automatic evaluation, can introduce systematic errors into the evaluation. The Prediction Powered Inference (PPI) framework provides a way of leveraging both the statistical power of automatic evaluation and a small pool of labelled data to produce a low-variance, unbiased estimate of the quantity being evaluated for. However, most work on PPI considers a relatively sizable set of labelled samples, which is not always practical to obtain. To this end, we present two new PPI-based techniques that leverage robust regressors to produce even lower variance estimators in the few-label regime.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images
Jan 25, 2024



Capturing the diversity of people in images is challenging: recent literature tends to focus on diversifying one or two attributes, requiring expensive attribute labels or building classifiers. We introduce a diverse people image ranking method which more flexibly aligns with human notions of people diversity in a less prescriptive, label-free manner. The Perception-Aligned Text-derived Human representation Space (PATHS) aims to capture all or many relevant features of people-related diversity, and, when used as the representation space in the standard Maximal Marginal Relevance (MMR) ranking algorithm, is better able to surface a range of types of people-related diversity (e.g. disability, cultural attire). PATHS is created in two stages. First, a text-guided approach is used to extract a person-diversity representation from a pre-trained image-text model. Then this representation is fine-tuned on perception judgments from human annotators so that it captures the aspects of people-related similarity that humans find most salient. Empirical results show that the PATHS method achieves diversity better than baseline methods, according to side-by-side ratings from human annotators.
Out of the Ordinary: Spectrally Adapting Regression for Covariate Shift
Dec 29, 2023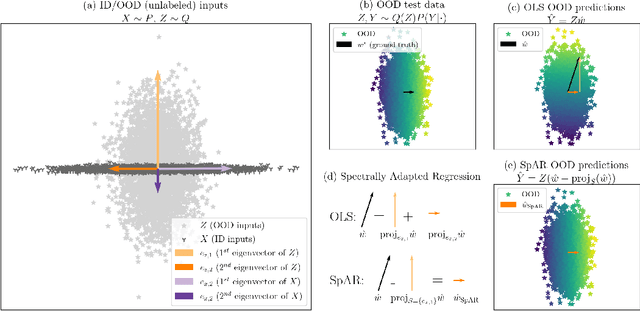
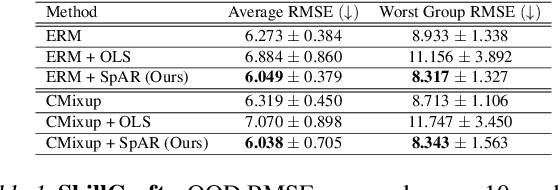
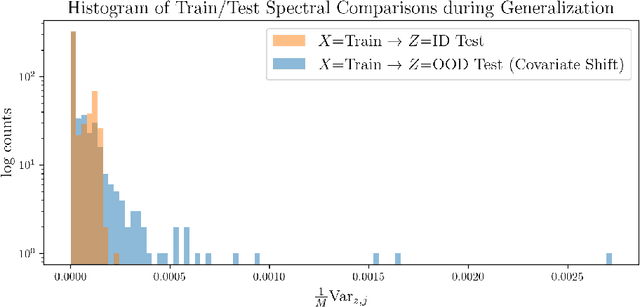

Designing deep neural network classifiers that perform robustly on distributions differing from the available training data is an active area of machine learning research. However, out-of-distribution generalization for regression-the analogous problem for modeling continuous targets-remains relatively unexplored. To tackle this problem, we return to first principles and analyze how the closed-form solution for Ordinary Least Squares (OLS) regression is sensitive to covariate shift. We characterize the out-of-distribution risk of the OLS model in terms of the eigenspectrum decomposition of the source and target data. We then use this insight to propose a method for adapting the weights of the last layer of a pre-trained neural regression model to perform better on input data originating from a different distribution. We demonstrate how this lightweight spectral adaptation procedure can improve out-of-distribution performance for synthetic and real-world datasets.
Learning and Forgetting Unsafe Examples in Large Language Models
Dec 20, 2023

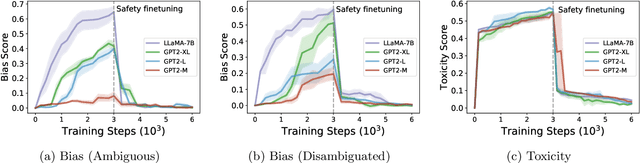
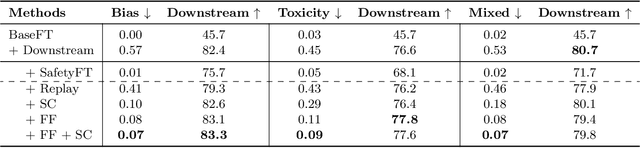
As the number of large language models (LLMs) released to the public grows, there is a pressing need to understand the safety implications associated with these models learning from third-party custom finetuning data. We explore the behavior of LLMs finetuned on noisy custom data containing unsafe content, represented by datasets that contain biases, toxicity, and harmfulness, finding that while aligned LLMs can readily learn this unsafe content, they also tend to forget it more significantly than other examples when subsequently finetuned on safer content. Drawing inspiration from the discrepancies in forgetting, we introduce the "ForgetFilter" algorithm, which filters unsafe data based on how strong the model's forgetting signal is for that data. We demonstrate that the ForgetFilter algorithm ensures safety in customized finetuning without compromising downstream task performance, unlike sequential safety finetuning. ForgetFilter outperforms alternative strategies like replay and moral self-correction in curbing LLMs' ability to assimilate unsafe content during custom finetuning, e.g. 75% lower than not applying any safety measures and 62% lower than using self-correction in toxicity score.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Identifying and Benchmarking Natural Out-of-Context Prediction Problems
Oct 25, 2021



Deep learning systems frequently fail at out-of-context (OOC) prediction, the problem of making reliable predictions on uncommon or unusual inputs or subgroups of the training distribution. To this end, a number of benchmarks for measuring OOC performance have recently been introduced. In this work, we introduce a framework unifying the literature on OOC performance measurement, and demonstrate how rich auxiliary information can be leveraged to identify candidate sets of OOC examples in existing datasets. We present NOOCh: a suite of naturally-occurring "challenge sets", and show how varying notions of context can be used to probe specific OOC failure modes. Experimentally, we explore the tradeoffs between various learning approaches on these challenge sets and demonstrate how the choices made in designing OOC benchmarks can yield varying conclusions.
Fairness and Robustness in Invariant Learning: A Case Study in Toxicity Classification
Dec 02, 2020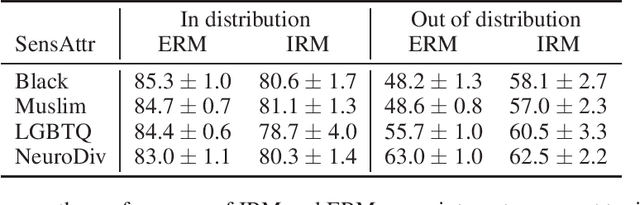
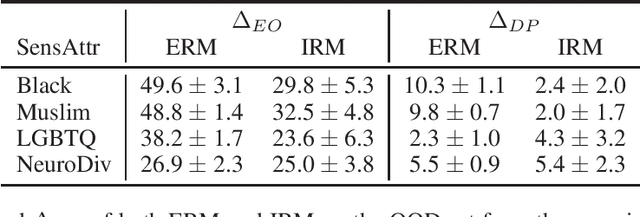


Robustness is of central importance in machine learning and has given rise to the fields of domain generalization and invariant learning, which are concerned with improving performance on a test distribution distinct from but related to the training distribution. In light of recent work suggesting an intimate connection between fairness and robustness, we investigate whether algorithms from robust ML can be used to improve the fairness of classifiers that are trained on biased data and tested on unbiased data. We apply Invariant Risk Minimization (IRM), a domain generalization algorithm that employs a causal discovery inspired method to find robust predictors, to the task of fairly predicting the toxicity of internet comments. We show that IRM achieves better out-of-distribution accuracy and fairness than Empirical Risk Minimization (ERM) methods, and analyze both the difficulties that arise when applying IRM in practice and the conditions under which IRM will likely be effective in this scenario. We hope that this work will inspire further studies of how robust machine learning methods relate to algorithmic fairness.
Amortized Causal Discovery: Learning to Infer Causal Graphs from Time-Series Data
Jun 18, 2020



Standard causal discovery methods must fit a new model whenever they encounter samples from a new underlying causal graph. However, these samples often share relevant information - for instance, the dynamics describing the effects of causal relations - which is lost when following this approach. We propose Amortized Causal Discovery, a novel framework that leverages such shared dynamics to learn to infer causal relations from time-series data. This enables us to train a single, amortized model that infers causal relations across samples with different underlying causal graphs, and thus makes use of the information that is shared. We demonstrate experimentally that this approach, implemented as a variational model, leads to significant improvements in causal discovery performance, and show how it can be extended to perform well under hidden confounding.