 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Local Geometry of Generative Model Manifolds
Aug 15, 2024



Deep generative models learn continuous representations of complex data manifolds using a finite number of samples during training. For a pre-trained generative model, the common way to evaluate the quality of the manifold representation learned, is by computing global metrics like Fr\'echet Inception Distance using a large number of generated and real samples. However, generative model performance is not uniform across the learned manifold, e.g., for \textit{foundation models} like Stable Diffusion generation performance can vary significantly based on the conditioning or initial noise vector being denoised. In this paper we study the relationship between the \textit{local geometry of the learned manifold} and downstream generation. Based on the theory of continuous piecewise-linear (CPWL) generators, we use three geometric descriptors - scaling ($\psi$), rank ($\nu$), and complexity ($\delta$) - to characterize a pre-trained generative model manifold locally. We provide quantitative and qualitative evidence showing that for a given latent, the local descriptors are correlated with generation aesthetics, artifacts, uncertainty, and even memorization. Finally we demonstrate that training a \textit{reward model} on the local geometry can allow controlling the likelihood of a generated sample under the learned distribution.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images
Jan 25, 2024



Capturing the diversity of people in images is challenging: recent literature tends to focus on diversifying one or two attributes, requiring expensive attribute labels or building classifiers. We introduce a diverse people image ranking method which more flexibly aligns with human notions of people diversity in a less prescriptive, label-free manner. The Perception-Aligned Text-derived Human representation Space (PATHS) aims to capture all or many relevant features of people-related diversity, and, when used as the representation space in the standard Maximal Marginal Relevance (MMR) ranking algorithm, is better able to surface a range of types of people-related diversity (e.g. disability, cultural attire). PATHS is created in two stages. First, a text-guided approach is used to extract a person-diversity representation from a pre-trained image-text model. Then this representation is fine-tuned on perception judgments from human annotators so that it captures the aspects of people-related similarity that humans find most salient. Empirical results show that the PATHS method achieves diversity better than baseline methods, according to side-by-side ratings from human annotators.
Consensus and Subjectivity of Skin Tone Annotation for ML Fairness
May 16, 2023



Recent advances in computer vision fairness have relied on datasets augmented with perceived attribute signals (e.g. gender presentation, skin tone, and age) and benchmarks enabled by these datasets. Typically labels for these tasks come from human annotators. However, annotating attribute signals, especially skin tone, is a difficult and subjective task. Perceived skin tone is affected by technical factors, like lighting conditions, and social factors that shape an annotator's lived experience. This paper examines the subjectivity of skin tone annotation through a series of annotation experiments using the Monk Skin Tone (MST) scale, a small pool of professional photographers, and a much larger pool of trained crowdsourced annotators. Our study shows that annotators can reliably annotate skin tone in a way that aligns with an expert in the MST scale, even under challenging environmental conditions. We also find evidence that annotators from different geographic regions rely on different mental models of MST categories resulting in annotations that systematically vary across regions. Given this, we advise practitioners to use a diverse set of annotators and a higher replication count for each image when annotating skin tone for fairness research.
A Step Toward More Inclusive People Annotations for Fairness
May 05, 2021
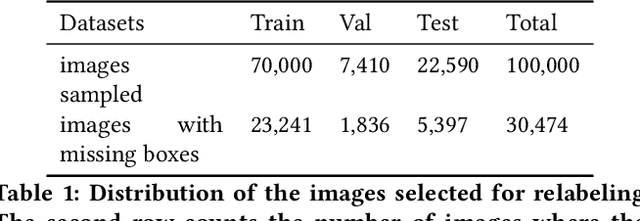
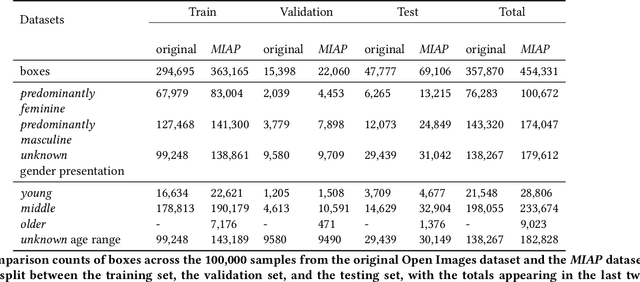
The Open Images Dataset contains approximately 9 million images and is a widely accepted dataset for computer vision research. As is common practice for large datasets, the annotations are not exhaustive, with bounding boxes and attribute labels for only a subset of the classes in each image. In this paper, we present a new set of annotations on a subset of the Open Images dataset called the MIAP (More Inclusive Annotations for People) subset, containing bounding boxes and attributes for all of the people visible in those images. The attributes and labeling methodology for the MIAP subset were designed to enable research into model fairness. In addition, we analyze the original annotation methodology for the person class and its subclasses, discussing the resulting patterns in order to inform future annotation efforts. By considering both the original and exhaustive annotation sets, researchers can also now study how systematic patterns in training annotations affect modeling.
Human Comprehension of Fairness in Machine Learning
Dec 17, 2019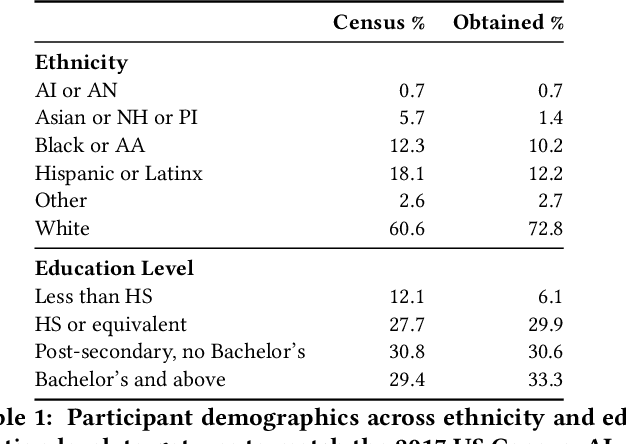
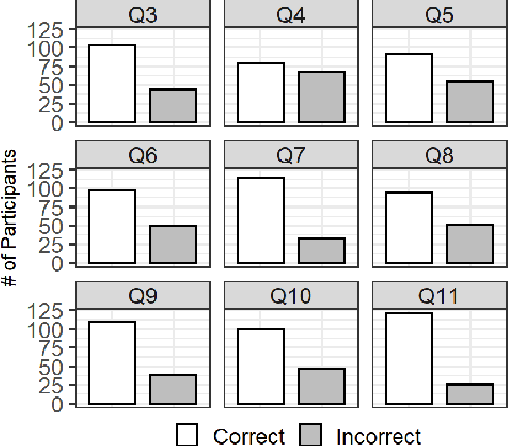
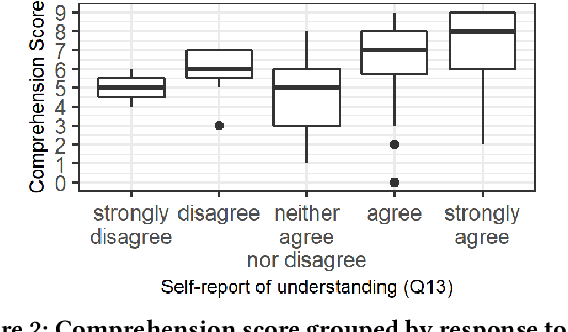
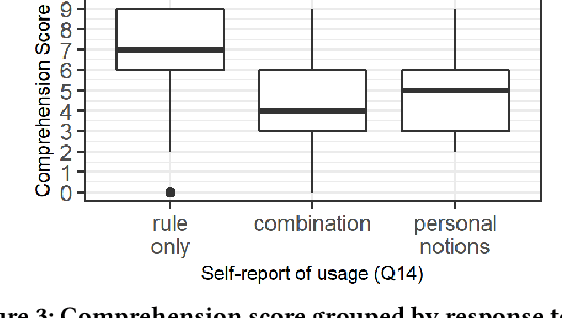
Bias in machine learning has manifested injustice in several areas, such as medicine, hiring, and criminal justice. In response, computer scientists have developed myriad definitions of fairness to correct this bias in fielded algorithms. While some definitions are based on established legal and ethical norms, others are largely mathematical. It is unclear whether the general public agrees with these fairness definitions, and perhaps more importantly, whether they understand these definitions. We take initial steps toward bridging this gap between ML researchers and the public, by addressing the question: does a non-technical audience understand a basic definition of ML fairness? We develop a metric to measure comprehension of one such definition--demographic parity. We validate this metric using online surveys, and study the relationship between comprehension and sentiment, demographics, and the application at hand.
Group Fairness in Bandit Arm Selection
Dec 09, 2019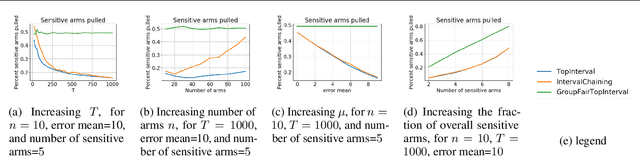
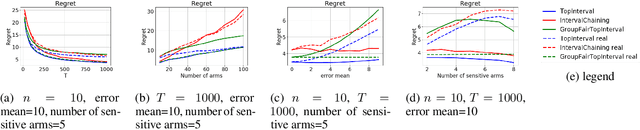
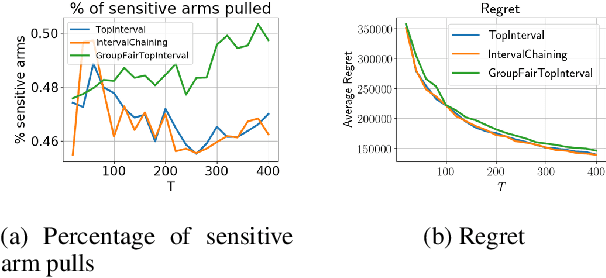
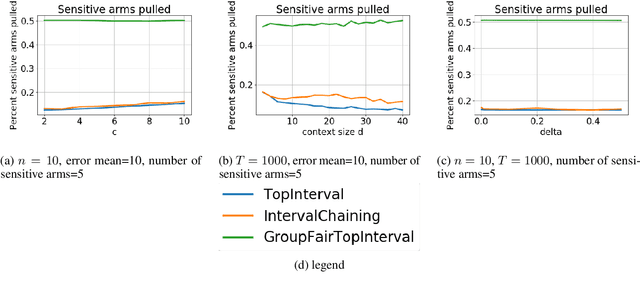
We consider group fairness in the contextual bandit setting. Here, a sequential decision maker must choose at each time step an arm to pull from a finite set of arms, after observing some context for each of the potential arm pulls. Additionally, arms are partitioned into m sensitive groups based on some protected feature (e.g., age, race, or socio-economic status). Despite the fact that there may be differences in expected payout between the groups, we may wish to ensure some form of fairness between picking arms from the various groups. In this work, we explore two definitions of fairness: equal group probability, wherein the probability of pulling an arm from any of the protected groups is the same; and proportional parity, wherein the probability of choosing an arm from a particular group is proportional to the size of that group. We provide a novel algorithm that can accommodate these notions of fairness and provide bounds on the regret for our algorithm. We test our algorithms on a hypothetical intervention setting wherein we want to allocate resources across protected groups.
Transfer of Machine Learning Fairness across Domains
Jun 26, 2019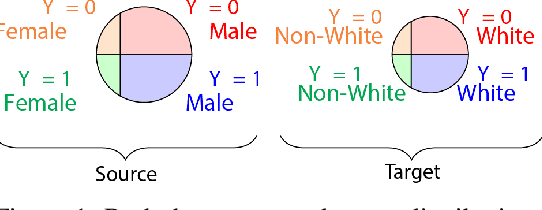

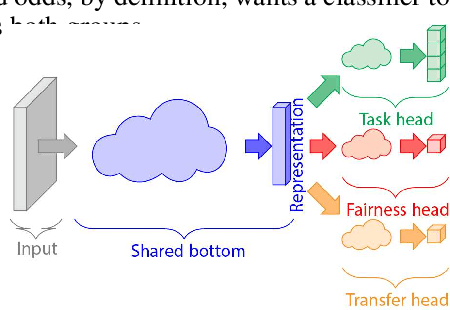
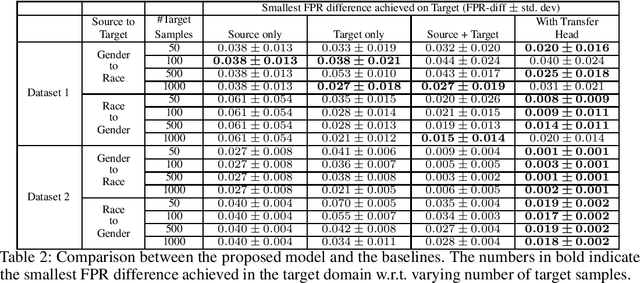
If our models are used in new or unexpected cases, do we know if they will make fair predictions? Previously, researchers developed ways to debias a model for a single problem domain. However, this is often not how models are trained and used in practice. For example, labels and demographics (sensitive attributes) are often hard to observe, resulting in auxiliary or synthetic data to be used for training, and proxies of the sensitive attribute to be used for evaluation of fairness. A model trained for one setting may be picked up and used in many others, particularly as is common with pre-training and cloud APIs. Despite the pervasiveness of these complexities, remarkably little work in the fairness literature has theoretically examined these issues. We frame all of these settings as domain adaptation problems: how can we use what we have learned in a source domain to debias in a new target domain, without directly debiasing on the target domain as if it is a completely new problem? We offer new theoretical guarantees of improving fairness across domains, and offer a modeling approach to transfer to data-sparse target domains. We give empirical results validating the theory and showing that these modeling approaches can improve fairness metrics with less data.
Making the Cut: A Bandit-based Approach to Tiered Interviewing
Jun 23, 2019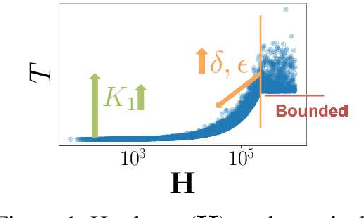
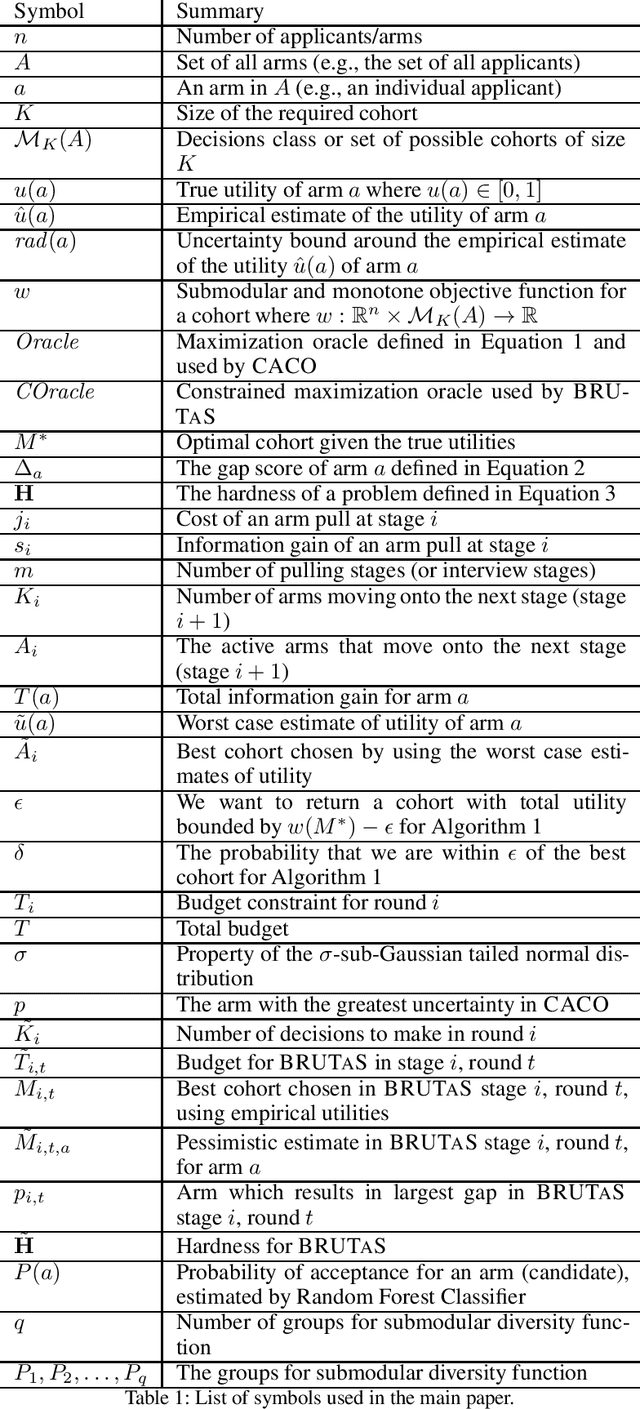
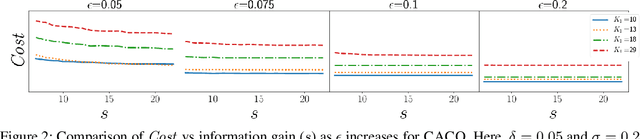

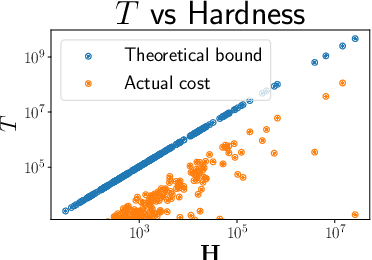
Given a huge set of applicants, how should a firm allocate sequential resume screenings, phone interviews, and in-person site visits? In a tiered interview process, later stages (e.g., in-person visits) are more informative, but also more expensive than earlier stages (e.g., resume screenings). Using accepted hiring models and the concept of structured interviews, a best practice in human resources, we cast tiered hiring as a combinatorial pure exploration (CPE) problem in the stochastic multi-armed bandit setting. The goal is to select a subset of arms (in our case, applicants) with some combinatorial structure. We present new algorithms in both the probably approximately correct (PAC) and fixed-budget settings that select a near-optimal cohort with provable guarantees. We show on real data from one of the largest US-based computer science graduate programs that our algorithms make better hiring decisions or use less budget than the status quo.
The Diverse Cohort Selection Problem
Aug 26, 2018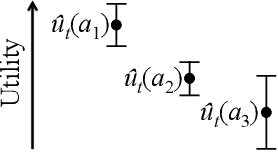

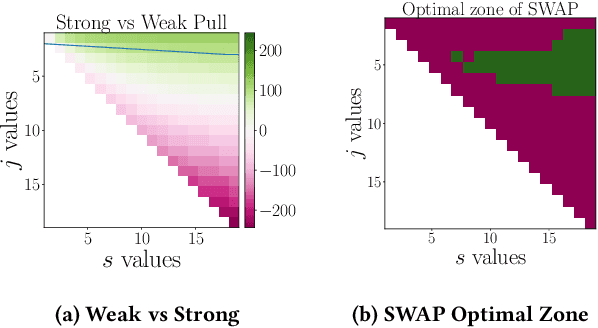
How should a firm allocate its limited interviewing resources to select the optimal cohort of new employees from a large set of job applicants? How should that firm allocate cheap but noisy resume screenings and expensive but in-depth in-person interviews? We view this problem through the lens of combinatorial pure exploration (CPE) in the multi-armed bandit setting, where a central learning agent performs costly exploration of a set of arms before selecting a final subset with some combinatorial structure. We generalize a recent CPE algorithm to the setting where arm pulls can have different costs, and return different levels of information, and prove theoretical upper bounds for a general class of arm-pulling strategies in this new setting. We then apply our general algorithm to a real-world problem with combinatorial structure: incorporating diversity into university admissions. We take real data from admissions at one of the largest US-based computer science graduate programs and show that a simulation of our algorithm produces more diverse student cohorts at low cost to individual student quality, spending comparable budget to the current admissions process at that university.