 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDP-Bench: Benchmarking ability of LLMs to protect personal information in interdependent privacy contexts
Jun 06, 2026Large language models (LLMs) are becoming widely deployed as personal AI assistants with access to sensitive user data, making privacy a major challenge for their design and evaluation. Prior work focuses mainly on individual-level risks, overlooking \textbf{interdependent privacy (IDP)}--where one person's data may be revealed by others without their knowledge or consent. We address this gap by introducing \textbf{IDP-Bench}: the first LLM benchmark for IDP scenarios, grounded in the Contextual Integrity (CI) framework. We evaluate eight open-source LLMs on their understanding of IDP scenarios across three levels of IDP reasoning using two LLM judges. Results show strong co-ownership recognition (6/8 models exceed 90\%) but persistent weaknesses in identifying CI parameters (information attribute, primary subject) and IDP-specific parameters such as secondary subjects, where 7/8 models score below 74\%. Models also struggle to judge sharing appropriateness (5/8 scoring below 77\%). While the ability to judge the appropriateness of sharing improves with scale, performance tends to decline in smaller models, and prompt sensitivity remains high on IDP-specific questions--highlighting the need for more targeted study of IDP in LLM privacy research. Data \& code available \href{https://github.com/tisl-lab/Interdependent_Privacy_Bench}{here}.
Shared Latent Structures Enable Unified Backdoor Detection and Mitigation in LLMs
Jun 06, 2026Backdoor attacks in large language models (LLMs) are often treated as isolated trigger-response failures, motivating defenses tailored to specific triggers or behaviors. We show this view is incomplete. Across diverse backdoor behaviors, we identify a shared latent mechanism that can be detected, causally controlled, and suppressed. Using sparse autoencoders (SAEs) on residual-stream activations, we find a small set of latent features consistently activated across jailbreaking, refusal manipulation, password-locking, bias induction, sentiment misclassification, and country-conditioned harmful advice. These features generalize across Qwen3, Gemma~3, and Llama~3.1 models from 4B to 32B parameters, and across both fine-tuning and weight-editing attacks. Through bidirectional activation steering, we show these features are causal: suppressing them reduces attack success, while amplifying them induces target behaviors on clean prompts. We further train lightweight SAE-feature classifiers that generalize zero-shot to unseen backdoors and outperform residual-stream and weight-diffing baselines. Finally, we introduce Concept Ablation Fine-Tuning (CAFT), which suppresses backdoor formation by ablating the shared latent subspace during training. Together, our results suggest that many backdoors rely on a transferable latent mechanism, enabling unified detection and mitigation.
Leveraging Routing Dynamics in Mixture-of-Experts Models for Efficient Language Adaptation
May 28, 2026Mixture-of-Experts (MoE) models are widely used to scale language models, yet their expert routing behavior and adaptation in a multilingual setting remain underexplored. In this work, we study multilingual routing dynamics during continual pre-training of an English-centric MoE model on a multilingual corpus, analyzing how expert usage varies across languages. We find that continual multilingual pre-training leads to diffused, language-agnostic routing in early and middle layers, with language specialization primarily emerging in the final layers. We also show that token-level vocabulary overlap between languages plays an important role in how languages are routed. Motivated by these findings, we propose a parameter-efficient adaptation strategy that updates language-specific and shared experts in the final MoE layers. Experiments on MultiBLiMP and Belebele show that our method achieves a strong performance-efficiency trade-off, attaining competitive performance relative to fine-tuning complete final layers, while updating less than 2% of the parameters. Overall, our findings provide insights into where and how language specialization emerges in MoEs during continual pre-training and provide practical insights for low-resource multilingual adaptation. Our code is available at https://github.com/aditi184/moe-routing-adaptation.
Mechanics of Bias and Reasoning: Interpreting the Impact of Chain-of-Thought Prompting on Gender Bias in LLMs
May 19, 2026Large language models (LLMs) are increasingly deployed in socially sensitive settings despite substantial documentation that they encode gender biases. Chain-of-Thought (CoT) prompting has been proposed as a bias-mitigation approach. However, existing evaluations primarily focus on changes in LLM benchmark performance, providing limited insight into whether apparent bias reductions reflect meaningful changes in a model's internal mechanisms. In this work, we investigate how CoT prompting affects gender bias in LLMs, combining benchmark-based evaluation with mechanistic interpretability techniques and reasoning chain failure analysis. Our results confirm a stereotypical bias present in LLM outputs across benchmarks, showing that CoT prompting does not consistently reduce the bias gap. Mechanistic analyses reveal that although CoT balances biased behavior in certain attention head clusters, gender bias remains embedded in hidden representations, indicating only superficial mitigation. Inspection of reasoning chains further suggests that these improvements stem from memorization and familiarity with the dataset rather than genuine understanding of bias.
Neighbor-Aware Localized Concept Erasure in Text-to-Image Diffusion Models
Mar 27, 2026Concept erasure in text-to-image diffusion models seeks to remove undesired concepts while preserving overall generative capability. Localized erasure methods aim to restrict edits to the spatial region occupied by the target concept. However, we observe that suppressing a concept can unintentionally weaken semantically related neighbor concepts, reducing fidelity in fine-grained domains. We propose Neighbor-Aware Localized Concept Erasure (NLCE), a training-free framework designed to better preserve neighboring concepts while removing target concepts. It operates in three stages: (1) a spectrally-weighted embedding modulation that attenuates target concept directions while stabilizing neighbor concept representations, (2) an attention-guided spatial gate that identifies regions exhibiting residual concept activation, and (3) a spatially-gated hard erasure that eliminates remaining traces only where necessary. This neighbor-aware pipeline enables localized concept removal while maintaining the surrounding concept neighborhood structure. Experiments on fine-grained datasets (Oxford Flowers, Stanford Dogs) show that our method effectively removes target concepts while better preserving closely related categories. Additional results on celebrity identity, explicit content and artistic style demonstrate robustness and generalization to broader erasure scenarios.
Rethinking Hallucinations: Correctness, Consistency, and Prompt Multiplicity
Jan 31, 2026Large language models (LLMs) are known to "hallucinate" by generating false or misleading outputs. Hallucinations pose various harms, from erosion of trust to widespread misinformation. Existing hallucination evaluation, however, focuses only on correctness and often overlooks consistency, necessary to distinguish and address these harms. To bridge this gap, we introduce prompt multiplicity, a framework for quantifying consistency in LLM evaluations. Our analysis reveals significant multiplicity (over 50% inconsistency in benchmarks like Med-HALT), suggesting that hallucination-related harms have been severely misunderstood. Furthermore, we study the role of consistency in hallucination detection and mitigation. We find that: (a) detection techniques detect consistency, not correctness, and (b) mitigation techniques like RAG, while beneficial, can introduce additional inconsistencies. By integrating prompt multiplicity into hallucination evaluation, we provide an improved framework of potential harms and uncover critical limitations in current detection and mitigation strategies.
Multilingual Amnesia: On the Transferability of Unlearning in Multilingual LLMs
Jan 09, 2026As multilingual large language models become more widely used, ensuring their safety and fairness across diverse linguistic contexts presents unique challenges. While existing research on machine unlearning has primarily focused on monolingual settings, typically English, multilingual environments introduce additional complexities due to cross-lingual knowledge transfer and biases embedded in both pretraining and fine-tuning data. In this work, we study multilingual unlearning using the Aya-Expanse 8B model under two settings: (1) data unlearning and (2) concept unlearning. We extend benchmarks for factual knowledge and stereotypes to ten languages through translation: English, French, Arabic, Japanese, Russian, Farsi, Korean, Hindi, Hebrew, and Indonesian. These languages span five language families and a wide range of resource levels. Our experiments show that unlearning in high-resource languages is generally more stable, with asymmetric transfer effects observed between typologically related languages. Furthermore, our analysis of linguistic distances indicates that syntactic similarity is the strongest predictor of cross-lingual unlearning behavior.
Understanding the role of depth in the neural tangent kernel for overparameterized neural networks
Nov 10, 2025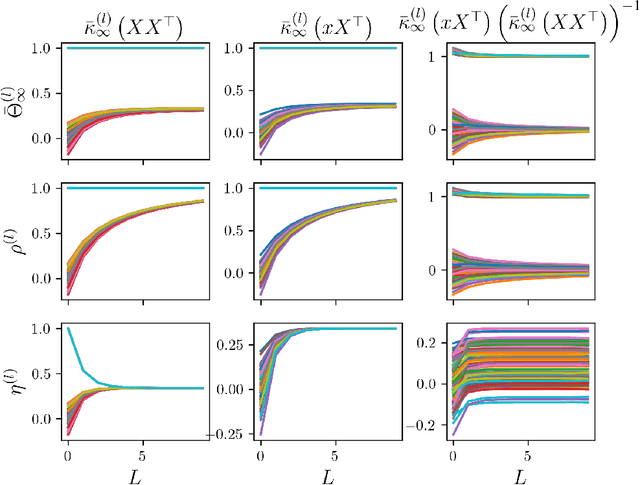
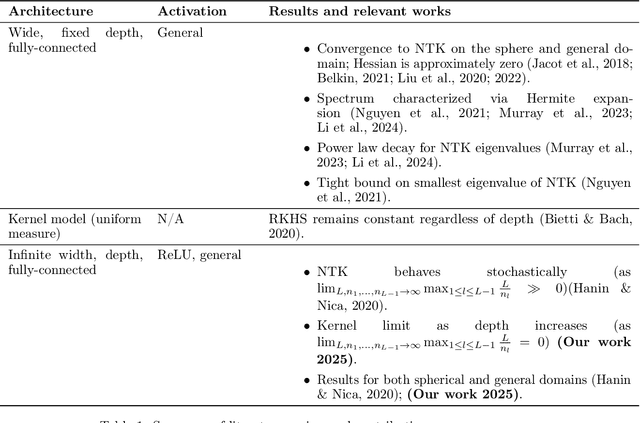
Overparameterized fully-connected neural networks have been shown to behave like kernel models when trained with gradient descent, under mild conditions on the width, the learning rate, and the parameter initialization. In the limit of infinitely large widths and small learning rate, the kernel that is obtained allows to represent the output of the learned model with a closed-form solution. This closed-form solution hinges on the invertibility of the limiting kernel, a property that often holds on real-world datasets. In this work, we analyze the sensitivity of large ReLU networks to increasing depths by characterizing the corresponding limiting kernel. Our theoretical results demonstrate that the normalized limiting kernel approaches the matrix of ones. In contrast, they show the corresponding closed-form solution approaches a fixed limit on the sphere. We empirically evaluate the order of magnitude in network depth required to observe this convergent behavior, and we describe the essential properties that enable the generalization of our results to other kernels.
Designing Ambiguity Sets for Distributionally Robust Optimization Using Structural Causal Optimal Transport
Oct 01, 2025Distributionally robust optimization tackles out-of-sample issues like overfitting and distribution shifts by adopting an adversarial approach over a range of possible data distributions, known as the ambiguity set. To balance conservatism and accuracy, these sets must include realistic probability distributions by leveraging information from the nominal distribution. Assuming that nominal distributions arise from a structural causal model with a directed acyclic graph $\mathcal{G}$ and structural equations, previous methods such as adapted and $\mathcal{G}$-causal optimal transport have only utilized causal graph information in designing ambiguity sets. In this work, we propose incorporating structural equations, which include causal graph information, to enhance ambiguity sets, resulting in more realistic distributions. We introduce structural causal optimal transport and its associated ambiguity set, demonstrating their advantages and connections to previous methods. A key benefit of our approach is a relaxed version, where a regularization term replaces the complex causal constraints, enabling an efficient algorithm via difference-of-convex programming to solve structural causal optimal transport. We also show that when structural information is absent and must be estimated, our approach remains effective and provides finite sample guarantees. Lastly, we address the radius of ambiguity sets, illustrating how our method overcomes the curse of dimensionality in optimal transport problems, achieving faster shrinkage with dimension-free order.
Reasoning with Preference Constraints: A Benchmark for Language Models in Many-to-One Matching Markets
Sep 16, 2025Recent advances in reasoning with large language models (LLMs) have demonstrated strong performance on complex mathematical tasks, including combinatorial optimization. Techniques such as Chain-of-Thought and In-Context Learning have further enhanced this capability, making LLMs both powerful and accessible tools for a wide range of users, including non-experts. However, applying LLMs to matching problems, which require reasoning under preferential and structural constraints, remains underexplored. To address this gap, we introduce a novel benchmark of 369 instances of the College Admission Problem, a canonical example of a matching problem with preferences, to evaluate LLMs across key dimensions: feasibility, stability, and optimality. We employ this benchmark to assess the performance of several open-weight LLMs. Our results first reveal that while LLMs can satisfy certain constraints, they struggle to meet all evaluation criteria consistently. They also show that reasoning LLMs, like QwQ and GPT-oss, significantly outperform traditional models such as Llama, Qwen or Mistral, defined here as models used without any dedicated reasoning mechanisms. Moreover, we observed that LLMs reacted differently to the various prompting strategies tested, which include Chain-of-Thought, In-Context Learning and role-based prompting, with no prompt consistently offering the best performance. Finally, we report the performances from iterative prompting with auto-generated feedback and show that they are not monotonic; they can peak early and then significantly decline in later attempts. Overall, this work offers a new perspective on model reasoning performance and the effectiveness of prompting strategies in combinatorial optimization problems with preferential constraints.