 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIRCLE: A Framework for Evaluating AI from a Real-World Lens
Mar 03, 2026This paper proposes CIRCLE, a six-stage, lifecycle-based framework to bridge the reality gap between model-centric performance metrics and AI's materialized outcomes in deployment. While existing frameworks like MLOps focus on system stability and benchmarks measure abstract capabilities, decision-makers outside the AI stack lack systematic evidence about the behavior of AI technologies under real-world user variability and constraints. CIRCLE operationalizes the Validation phase of TEVV (Test, Evaluation, Verification, and Validation) by formalizing the translation of stakeholder concerns outside the stack into measurable signals. Unlike participatory design, which often remains localized, or algorithmic audits, which are often retrospective, CIRCLE provides a structured, prospective protocol for linking context-sensitive qualitative insights to scalable quantitative metrics. By integrating methods such as field testing, red teaming, and longitudinal studies into a coordinated pipeline, CIRCLE produces systematic knowledge: evidence that is comparable across sites yet sensitive to local context. This can enable governance based on materialized downstream effects rather than theoretical capabilities.
Say It Another Way: A Framework for User-Grounded Paraphrasing
May 06, 2025Small changes in how a prompt is worded can lead to meaningful differences in the behavior of large language models (LLMs), raising concerns about the stability and reliability of their evaluations. While prior work has explored simple formatting changes, these rarely capture the kinds of natural variation seen in real-world language use. We propose a controlled paraphrasing framework based on a taxonomy of minimal linguistic transformations to systematically generate natural prompt variations. Using the BBQ dataset, we validate our method with both human annotations and automated checks, then use it to study how LLMs respond to paraphrased prompts in stereotype evaluation tasks. Our analysis shows that even subtle prompt modifications can lead to substantial changes in model behavior. These results highlight the need for robust, paraphrase-aware evaluation protocols.
Multilingual Hallucination Gaps in Large Language Models
Oct 23, 2024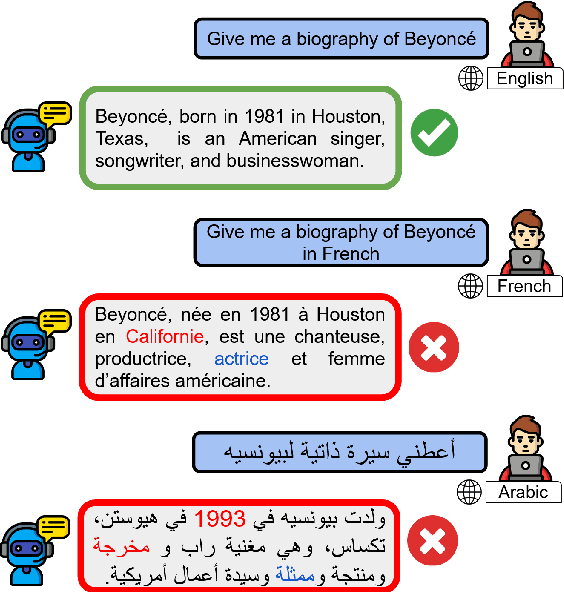
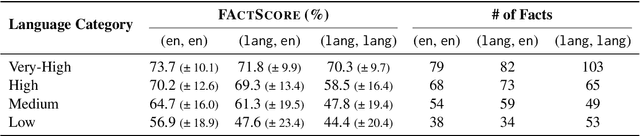

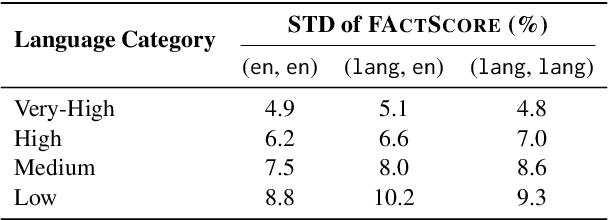
Large language models (LLMs) are increasingly used as alternatives to traditional search engines given their capacity to generate text that resembles human language. However, this shift is concerning, as LLMs often generate hallucinations, misleading or false information that appears highly credible. In this study, we explore the phenomenon of hallucinations across multiple languages in freeform text generation, focusing on what we call multilingual hallucination gaps. These gaps reflect differences in the frequency of hallucinated answers depending on the prompt and language used. To quantify such hallucinations, we used the FactScore metric and extended its framework to a multilingual setting. We conducted experiments using LLMs from the LLaMA, Qwen, and Aya families, generating biographies in 19 languages and comparing the results to Wikipedia pages. Our results reveal variations in hallucination rates, especially between high and low resource languages, raising important questions about LLM multilingual performance and the challenges in evaluating hallucinations in multilingual freeform text generation.
Fairness Incentives in Response to Unfair Dynamic Pricing
Apr 22, 2024The use of dynamic pricing by profit-maximizing firms gives rise to demand fairness concerns, measured by discrepancies in consumer groups' demand responses to a given pricing strategy. Notably, dynamic pricing may result in buyer distributions unreflective of those of the underlying population, which can be problematic in markets where fair representation is socially desirable. To address this, policy makers might leverage tools such as taxation and subsidy to adapt policy mechanisms dependent upon their social objective. In this paper, we explore the potential for AI methods to assist such intervention strategies. To this end, we design a basic simulated economy, wherein we introduce a dynamic social planner (SP) to generate corporate taxation schedules geared to incentivizing firms towards adopting fair pricing behaviours, and to use the collected tax budget to subsidize consumption among underrepresented groups. To cover a range of possible policy scenarios, we formulate our social planner's learning problem as a multi-armed bandit, a contextual bandit and finally as a full reinforcement learning (RL) problem, evaluating welfare outcomes from each case. To alleviate the difficulty in retaining meaningful tax rates that apply to less frequently occurring brackets, we introduce FairReplayBuffer, which ensures that our RL agent samples experiences uniformly across a discretized fairness space. We find that, upon deploying a learned tax and redistribution policy, social welfare improves on that of the fairness-agnostic baseline, and approaches that of the analytically optimal fairness-aware baseline for the multi-armed and contextual bandit settings, and surpassing it by 13.19% in the full RL setting.
Federated Edge Learning : Design Issues and Challenges
Aug 31, 2020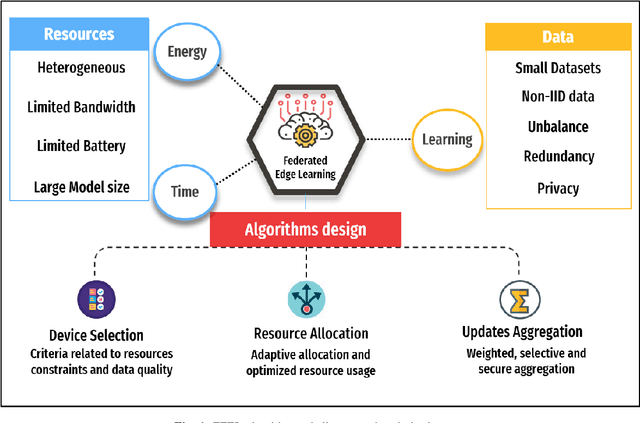
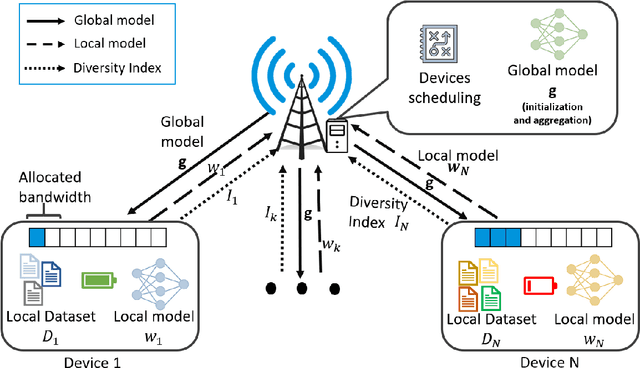
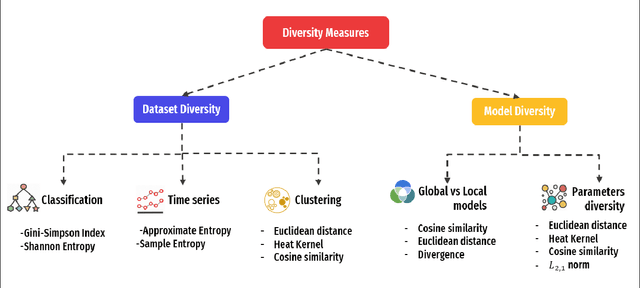
Federated Learning (FL) is a distributed machine learning technique, where each device contributes to the learning model by independently computing the gradient based on its local training data. It has recently become a hot research topic, as it promises several benefits related to data privacy and scalability. However, implementing FL at the network edge is challenging due to system and data heterogeneity and resources constraints. In this article, we examine the existing challenges and trade-offs in Federated Edge Learning (FEEL). The design of FEEL algorithms for resources-efficient learning raises several challenges. These challenges are essentially related to the multidisciplinary nature of the problem. As the data is the key component of the learning, this article advocates a new set of considerations for data characteristics in wireless scheduling algorithms in FEEL. Hence, we propose a general framework for the data-aware scheduling as a guideline for future research directions. We also discuss the main axes and requirements for data evaluation and some exploitable techniques and metrics.