 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Edge Learning : Design Issues and Challenges
Paper and Code
Aug 31, 2020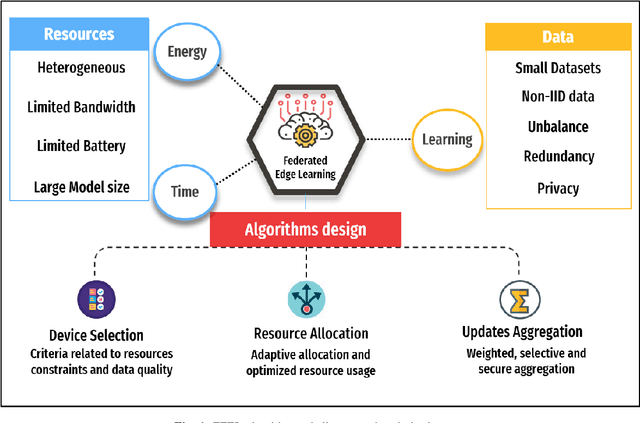
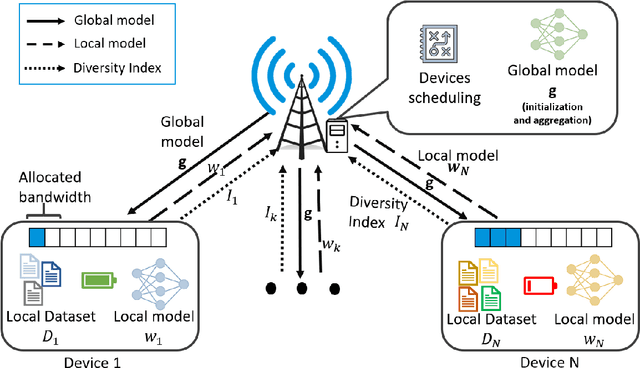
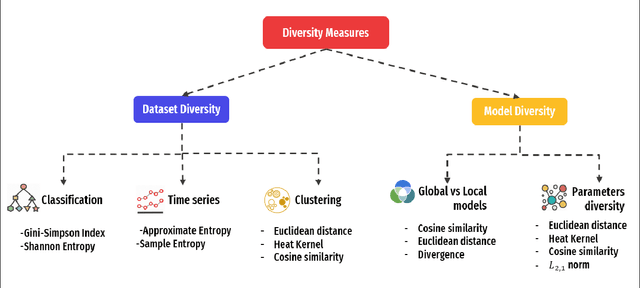
Federated Learning (FL) is a distributed machine learning technique, where each device contributes to the learning model by independently computing the gradient based on its local training data. It has recently become a hot research topic, as it promises several benefits related to data privacy and scalability. However, implementing FL at the network edge is challenging due to system and data heterogeneity and resources constraints. In this article, we examine the existing challenges and trade-offs in Federated Edge Learning (FEEL). The design of FEEL algorithms for resources-efficient learning raises several challenges. These challenges are essentially related to the multidisciplinary nature of the problem. As the data is the key component of the learning, this article advocates a new set of considerations for data characteristics in wireless scheduling algorithms in FEEL. Hence, we propose a general framework for the data-aware scheduling as a guideline for future research directions. We also discuss the main axes and requirements for data evaluation and some exploitable techniques and metrics.