 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem-$π$: Adaptive Memory through Learning When and What to Generate
May 20, 2026We present Mem-$π$, a framework for adaptive memory in large language model (LLM) agents, where useful guidance is generated on demand rather than retrieved from external memory stores. Existing memory-augmented agents typically rely on similarity-based retrieval from episodic memory banks or skill libraries, returning static entries that often misalign with the current context. In contrast, Mem-$π$ uses a dedicated language or vision-language model with its own parameters, separate from the downstream agent, to generate context-specific guidance for complex tasks. Conditioned on the current agent context, the model jointly decides when to produce guidance and what guidance to produce. We train it with a decision-content decoupled reinforcement learning (RL) objective, enabling it to abstain when generation would not help and otherwise produce concise, useful guidance. Across diverse agentic benchmarks spanning web navigation, terminal-based tool use, and text-based embodied interaction, Mem-$π$ consistently outperforms retrieval-based and prior RL-optimized memory baselines, achieving over 30% relative improvement on web navigation tasks.
Just-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Oct 05, 2025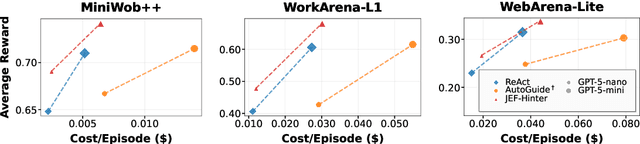
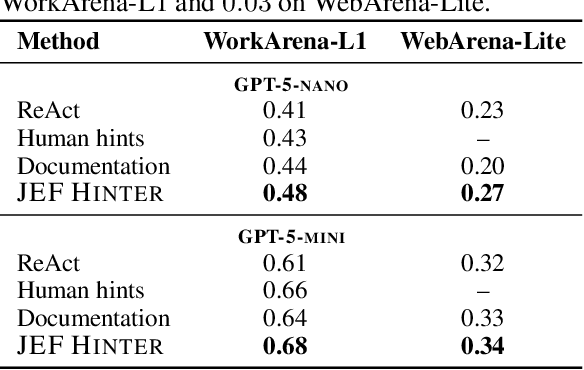
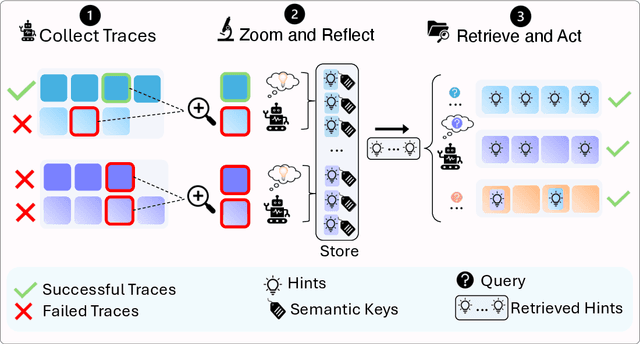
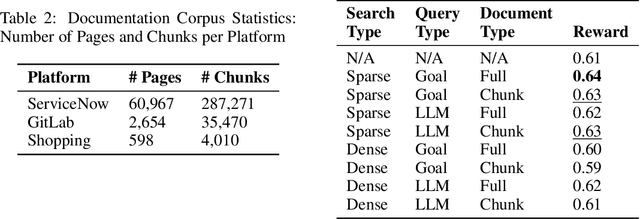
Large language model (LLM) agents perform well in sequential decision-making tasks, but improving them on unfamiliar domains often requires costly online interactions or fine-tuning on large expert datasets. These strategies are impractical for closed-source models and expensive for open-source ones, with risks of catastrophic forgetting. Offline trajectories offer reusable knowledge, yet demonstration-based methods struggle because raw traces are long, noisy, and tied to specific tasks. We present Just-in-time Episodic Feedback Hinter (JEF Hinter), an agentic system that distills offline traces into compact, context-aware hints. A zooming mechanism highlights decisive steps in long trajectories, capturing both strategies and pitfalls. Unlike prior methods, JEF Hinter leverages both successful and failed trajectories, extracting guidance even when only failure data is available, while supporting parallelized hint generation and benchmark-independent prompting. At inference, a retriever selects relevant hints for the current state, providing targeted guidance with transparency and traceability. Experiments on MiniWoB++, WorkArena-L1, and WebArena-Lite show that JEF Hinter consistently outperforms strong baselines, including human- and document-based hints.
A Generalist Hanabi Agent
Mar 17, 2025Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting than the one they have been trained on, and struggle to successfully cooperate with unfamiliar collaborators. This is particularly visible in the Hanabi benchmark, a popular 2-to-5 player cooperative card-game which requires complex reasoning and precise assistance to other agents. Current MARL agents for Hanabi can only learn one specific game-setting (e.g., 2-player games), and play with the same algorithmic agents. This is in stark contrast to humans, who can quickly adjust their strategies to work with unfamiliar partners or situations. In this paper, we introduce Recurrent Replay Relevance Distributed DQN (R3D2), a generalist agent for Hanabi, designed to overcome these limitations. We reformulate the task using text, as language has been shown to improve transfer. We then propose a distributed MARL algorithm that copes with the resulting dynamic observation- and action-space. In doing so, our agent is the first that can play all game settings concurrently, and extend strategies learned from one setting to other ones. As a consequence, our agent also demonstrates the ability to collaborate with different algorithmic agents -- agents that are themselves unable to do so. The implementation code is available at: $\href{https://github.com/chandar-lab/R3D2-A-Generalist-Hanabi-Agent}{R3D2-A-Generalist-Hanabi-Agent}$
Generative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
Fairness Incentives in Response to Unfair Dynamic Pricing
Apr 22, 2024The use of dynamic pricing by profit-maximizing firms gives rise to demand fairness concerns, measured by discrepancies in consumer groups' demand responses to a given pricing strategy. Notably, dynamic pricing may result in buyer distributions unreflective of those of the underlying population, which can be problematic in markets where fair representation is socially desirable. To address this, policy makers might leverage tools such as taxation and subsidy to adapt policy mechanisms dependent upon their social objective. In this paper, we explore the potential for AI methods to assist such intervention strategies. To this end, we design a basic simulated economy, wherein we introduce a dynamic social planner (SP) to generate corporate taxation schedules geared to incentivizing firms towards adopting fair pricing behaviours, and to use the collected tax budget to subsidize consumption among underrepresented groups. To cover a range of possible policy scenarios, we formulate our social planner's learning problem as a multi-armed bandit, a contextual bandit and finally as a full reinforcement learning (RL) problem, evaluating welfare outcomes from each case. To alleviate the difficulty in retaining meaningful tax rates that apply to less frequently occurring brackets, we introduce FairReplayBuffer, which ensures that our RL agent samples experiences uniformly across a discretized fairness space. We find that, upon deploying a learned tax and redistribution policy, social welfare improves on that of the fairness-agnostic baseline, and approaches that of the analytically optimal fairness-aware baseline for the multi-armed and contextual bandit settings, and surpassing it by 13.19% in the full RL setting.
Towards Few-shot Coordination: Revisiting Ad-hoc Teamplay Challenge In the Game of Hanabi
Aug 20, 2023



Cooperative Multi-agent Reinforcement Learning (MARL) algorithms with Zero-Shot Coordination (ZSC) have gained significant attention in recent years. ZSC refers to the ability of agents to coordinate zero-shot (without additional interaction experience) with independently trained agents. While ZSC is crucial for cooperative MARL agents, it might not be possible for complex tasks and changing environments. Agents also need to adapt and improve their performance with minimal interaction with other agents. In this work, we show empirically that state-of-the-art ZSC algorithms have poor performance when paired with agents trained with different learning methods, and they require millions of interaction samples to adapt to these new partners. To investigate this issue, we formally defined a framework based on a popular cooperative multi-agent game called Hanabi to evaluate the adaptability of MARL methods. In particular, we created a diverse set of pre-trained agents and defined a new metric called adaptation regret that measures the agent's ability to efficiently adapt and improve its coordination performance when paired with some held-out pool of partners on top of its ZSC performance. After evaluating several SOTA algorithms using our framework, our experiments reveal that naive Independent Q-Learning (IQL) agents in most cases adapt as quickly as the SOTA ZSC algorithm Off-Belief Learning (OBL). This finding raises an interesting research question: How to design MARL algorithms with high ZSC performance and capability of fast adaptation to unseen partners. As a first step, we studied the role of different hyper-parameters and design choices on the adaptability of current MARL algorithms. Our experiments show that two categories of hyper-parameters controlling the training data diversity and optimization process have a significant impact on the adaptability of Hanabi agents.
Dealing With Non-stationarity in Decentralized Cooperative Multi-Agent Deep Reinforcement Learning via Multi-Timescale Learning
Feb 06, 2023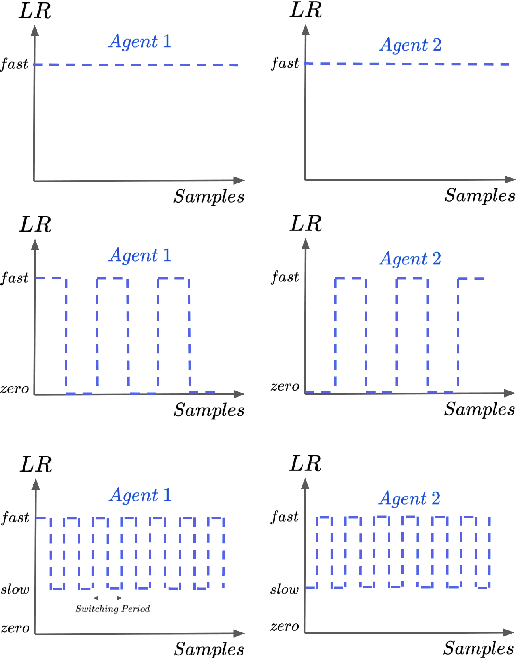
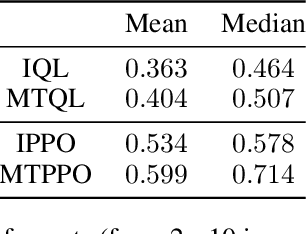
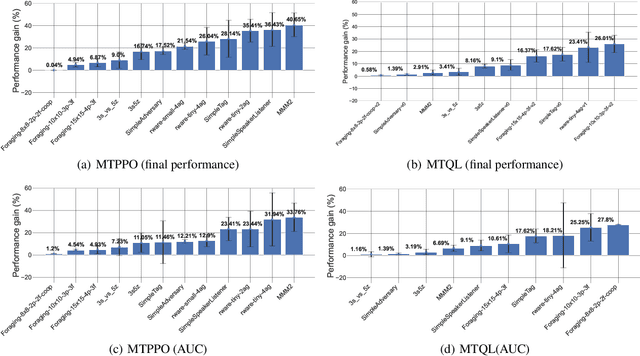
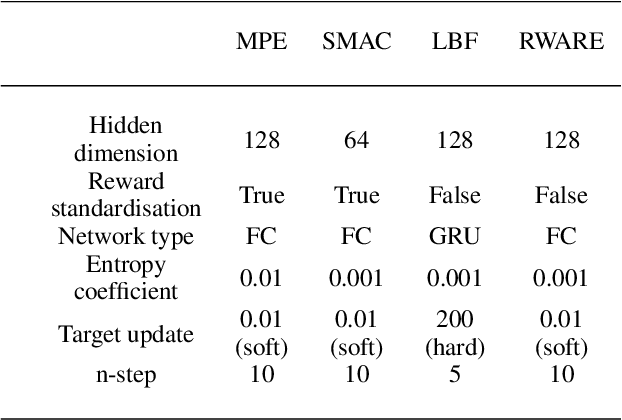
Decentralized cooperative multi-agent deep reinforcement learning (MARL) can be a versatile learning framework, particularly in scenarios where centralized training is either not possible or not practical. One of the key challenges in decentralized deep MARL is the non-stationarity of the learning environment when multiple agents are learning concurrently. A commonly used and efficient scheme for decentralized MARL is independent learning in which agents concurrently update their policies independent of each other. We first show that independent learning does not always converge, while sequential learning where agents update their policies one after another in a sequence is guaranteed to converge to an agent-by-agent optimal solution. In sequential learning, when one agent updates its policy, all other agent's policies are kept fixed, alleviating the challenge of non-stationarity due to concurrent updates in other agents' policies. However, it can be slow because only one agent is learning at any time. Therefore it might also not always be practical. In this work, we propose a decentralized cooperative MARL algorithm based on multi-timescale learning. In multi-timescale learning, all agents learn concurrently, but at different learning rates. In our proposed method, when one agent updates its policy, other agents are allowed to update their policies as well, but at a slower rate. This speeds up sequential learning, while also minimizing non-stationarity caused by other agents updating concurrently. Multi-timescale learning outperforms state-of-the-art decentralized learning methods on a set of challenging multi-agent cooperative tasks in the epymarl (papoudakis2020) benchmark. This can be seen as a first step towards more general decentralized cooperative deep MARL methods based on multi-timescale learning.
Multi-Agent Reinforcement Learning for Fast-Timescale Demand Response of Residential Loads
Jan 06, 2023To integrate high amounts of renewable energy resources, electrical power grids must be able to cope with high amplitude, fast timescale variations in power generation. Frequency regulation through demand response has the potential to coordinate temporally flexible loads, such as air conditioners, to counteract these variations. Existing approaches for discrete control with dynamic constraints struggle to provide satisfactory performance for fast timescale action selection with hundreds of agents. We propose a decentralized agent trained with multi-agent proximal policy optimization with localized communication. We explore two communication frameworks: hand-engineered, or learned through targeted multi-agent communication. The resulting policies perform well and robustly for frequency regulation, and scale seamlessly to arbitrary numbers of houses for constant processing times.
Continuous Coordination As a Realistic Scenario for Lifelong Learning
Mar 04, 2021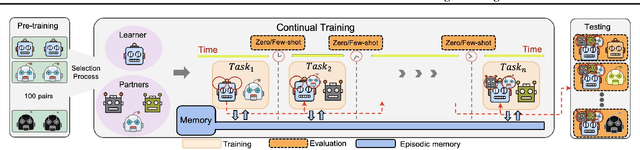
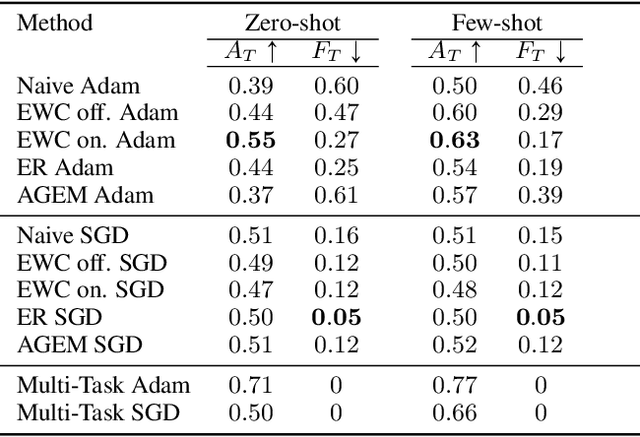
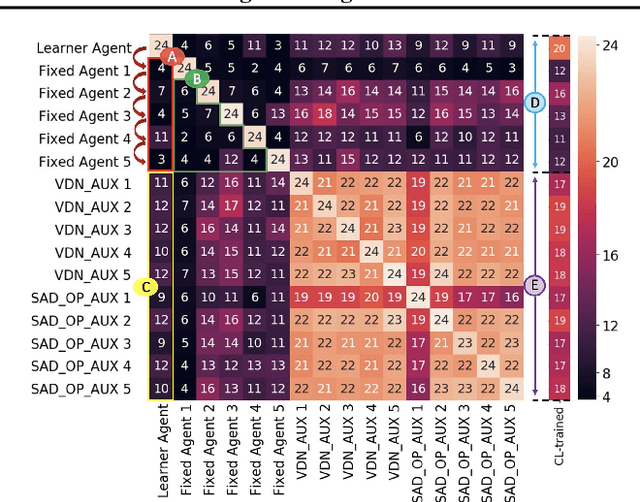

Current deep reinforcement learning (RL) algorithms are still highly task-specific and lack the ability to generalize to new environments. Lifelong learning (LLL), however, aims at solving multiple tasks sequentially by efficiently transferring and using knowledge between tasks. Despite a surge of interest in lifelong RL in recent years, the lack of a realistic testbed makes robust evaluation of LLL algorithms difficult. Multi-agent RL (MARL), on the other hand, can be seen as a natural scenario for lifelong RL due to its inherent non-stationarity, since the agents' policies change over time. In this work, we introduce a multi-agent lifelong learning testbed that supports both zero-shot and few-shot settings. Our setup is based on Hanabi -- a partially-observable, fully cooperative multi-agent game that has been shown to be challenging for zero-shot coordination. Its large strategy space makes it a desirable environment for lifelong RL tasks. We evaluate several recent MARL methods, and benchmark state-of-the-art LLL algorithms in limited memory and computation regimes to shed light on their strengths and weaknesses. This continual learning paradigm also provides us with a pragmatic way of going beyond centralized training which is the most commonly used training protocol in MARL. We empirically show that the agents trained in our setup are able to coordinate well with unseen agents, without any additional assumptions made by previous works.
DEUP: Direct Epistemic Uncertainty Prediction
Feb 16, 2021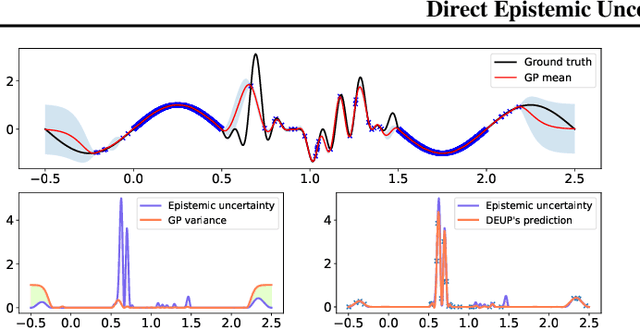
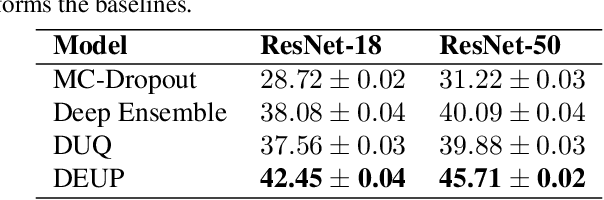
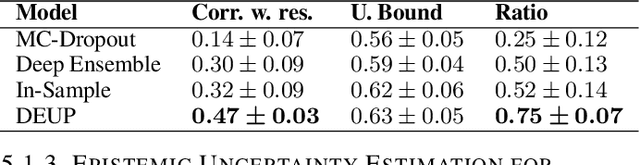
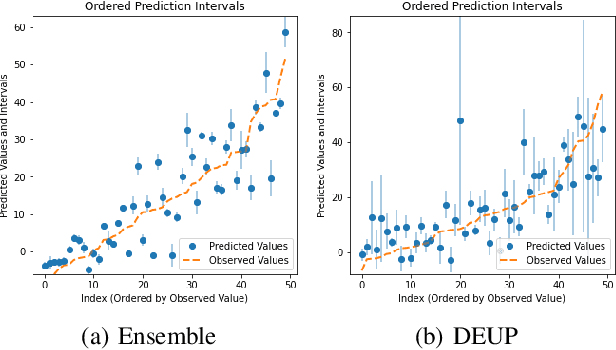
Epistemic uncertainty is the part of out-of-sample prediction error due to the lack of knowledge of the learner. Whereas previous work was focusing on model variance, we propose a principled approach for directly estimating epistemic uncertainty by learning to predict generalization error and subtracting an estimate of aleatoric uncertainty, i.e., intrinsic unpredictability. This estimator of epistemic uncertainty includes the effect of model bias and can be applied in non-stationary learning environments arising in active learning or reinforcement learning. In addition to demonstrating these properties of Direct Epistemic Uncertainty Prediction (DEUP), we illustrate its advantage against existing methods for uncertainty estimation on downstream tasks including sequential model optimization and reinforcement learning. We also evaluate the quality of uncertainty estimates from DEUP for probabilistic classification of images and for estimating uncertainty about synergistic drug combinations.