 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARSA-Bench: A Comprehensive Persian Audio-Language Model Benchmark
Mar 15, 2026Persian poses unique audio understanding challenges through its classical poetry, traditional music, and pervasive code-switching - none captured by existing benchmarks. We introduce PARSA-Bench (Persian Audio Reasoning and Speech Assessment Benchmark), the first benchmark for evaluating large audio-language models on Persian language and culture, comprising 16 tasks and over 8,000 samples across speech understanding, paralinguistic analysis, and cultural audio understanding. Ten tasks are newly introduced, including poetry meter and style detection, traditional Persian music understanding, and code-switching detection. Text-only baselines consistently outperform audio counterparts, suggesting models may not leverage audio-specific information beyond what transcription alone provides. Culturally-grounded tasks expose a qualitatively distinct failure mode: all models perform near random chance on vazn detection regardless of scale, suggesting prosodic perception remains beyond the reach of current models. The dataset is publicly available at https://huggingface.co/datasets/MohammadJRanjbar/PARSA-Bench
Dealing With Non-stationarity in Decentralized Cooperative Multi-Agent Deep Reinforcement Learning via Multi-Timescale Learning
Feb 06, 2023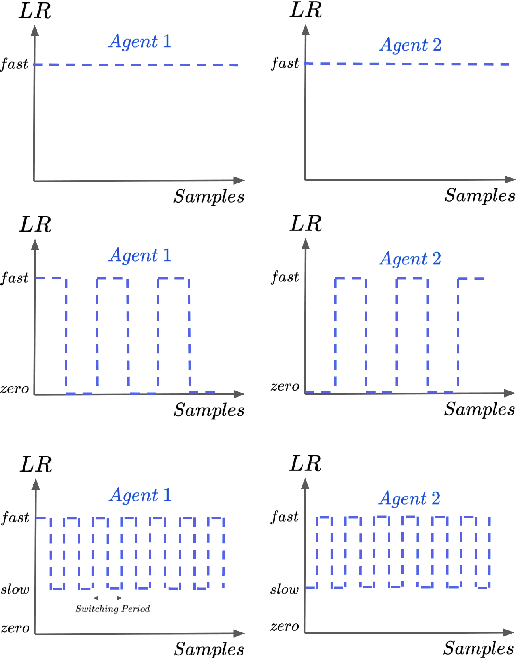
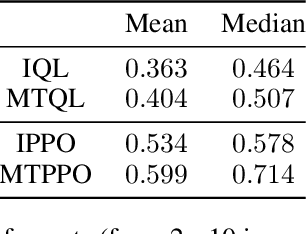
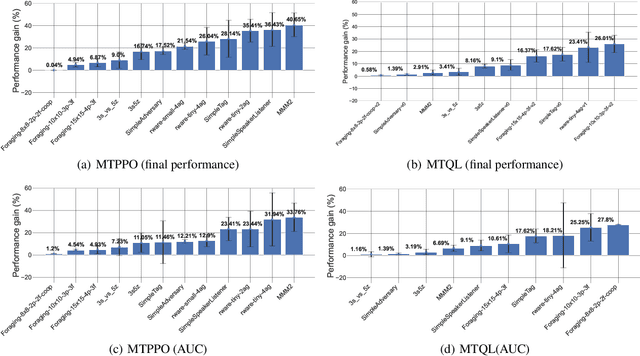
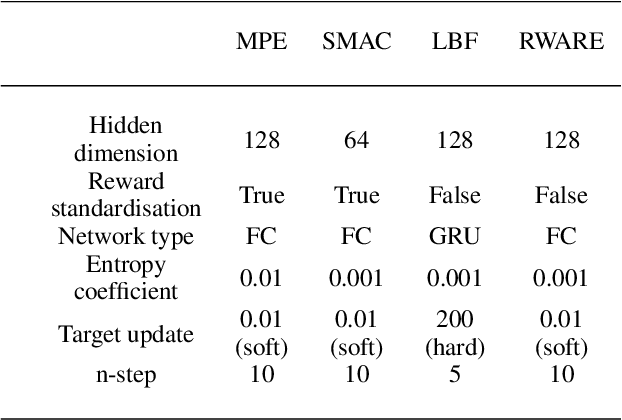
Decentralized cooperative multi-agent deep reinforcement learning (MARL) can be a versatile learning framework, particularly in scenarios where centralized training is either not possible or not practical. One of the key challenges in decentralized deep MARL is the non-stationarity of the learning environment when multiple agents are learning concurrently. A commonly used and efficient scheme for decentralized MARL is independent learning in which agents concurrently update their policies independent of each other. We first show that independent learning does not always converge, while sequential learning where agents update their policies one after another in a sequence is guaranteed to converge to an agent-by-agent optimal solution. In sequential learning, when one agent updates its policy, all other agent's policies are kept fixed, alleviating the challenge of non-stationarity due to concurrent updates in other agents' policies. However, it can be slow because only one agent is learning at any time. Therefore it might also not always be practical. In this work, we propose a decentralized cooperative MARL algorithm based on multi-timescale learning. In multi-timescale learning, all agents learn concurrently, but at different learning rates. In our proposed method, when one agent updates its policy, other agents are allowed to update their policies as well, but at a slower rate. This speeds up sequential learning, while also minimizing non-stationarity caused by other agents updating concurrently. Multi-timescale learning outperforms state-of-the-art decentralized learning methods on a set of challenging multi-agent cooperative tasks in the epymarl (papoudakis2020) benchmark. This can be seen as a first step towards more general decentralized cooperative deep MARL methods based on multi-timescale learning.
Improving Sample Efficiency of Value Based Models Using Attention and Vision Transformers
Feb 01, 2022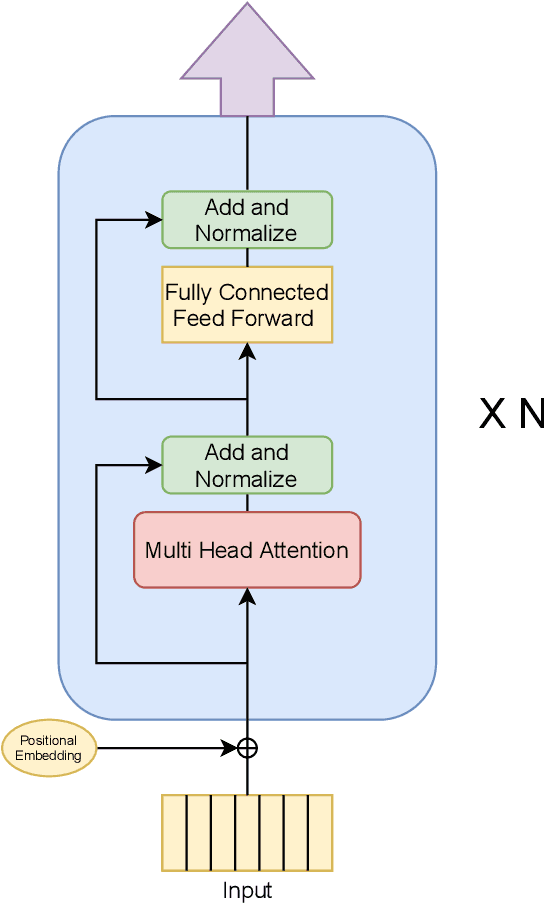

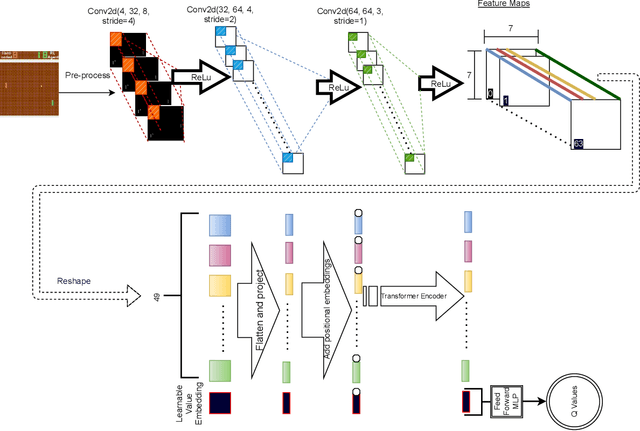
Much of recent Deep Reinforcement Learning success is owed to the neural architecture's potential to learn and use effective internal representations of the world. While many current algorithms access a simulator to train with a large amount of data, in realistic settings, including while playing games that may be played against people, collecting experience can be quite costly. In this paper, we introduce a deep reinforcement learning architecture whose purpose is to increase sample efficiency without sacrificing performance. We design this architecture by incorporating advances achieved in recent years in the field of Natural Language Processing and Computer Vision. Specifically, we propose a visually attentive model that uses transformers to learn a self-attention mechanism on the feature maps of the state representation, while simultaneously optimizing return. We demonstrate empirically that this architecture improves sample complexity for several Atari environments, while also achieving better performance in some of the games.
PatchUp: A Regularization Technique for Convolutional Neural Networks
Jun 14, 2020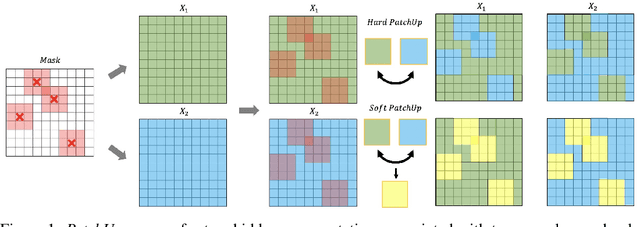
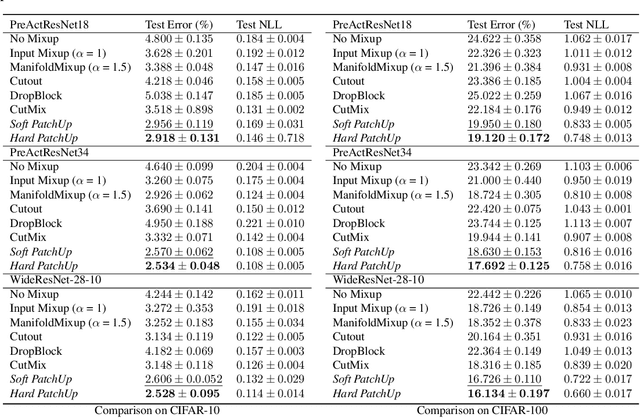
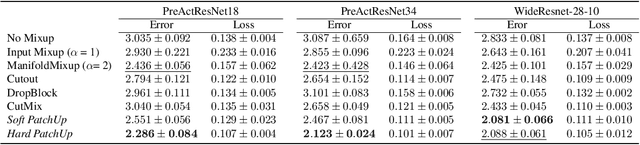
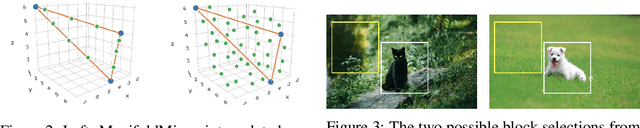
Large capacity deep learning models are often prone to a high generalization gap when trained with a limited amount of labeled training data. A recent class of methods to address this problem uses various ways to construct a new training sample by mixing a pair (or more) of training samples. We propose PatchUp, a hidden state block-level regularization technique for Convolutional Neural Networks (CNNs), that is applied on selected contiguous blocks of feature maps from a random pair of samples. Our approach improves the robustness of CNN models against the manifold intrusion problem that may occur in other state-of-the-art mixing approaches like Mixup and CutMix. Moreover, since we are mixing the contiguous block of features in the hidden space, which has more dimensions than the input space, we obtain more diverse samples for training towards different dimensions. Our experiments on CIFAR-10, CIFAR-100, and SVHN datasets with PreactResnet18, PreactResnet34, and WideResnet-28-10 models show that PatchUp improves upon, or equals, the performance of current state-of-the-art regularizers for CNNs. We also show that PatchUp can provide better generalization to affine transformations of samples and is more robust against adversarial attacks.