 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Lifelong Supervised Learning
Jul 12, 2022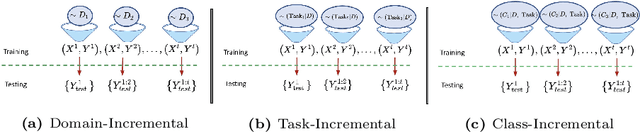
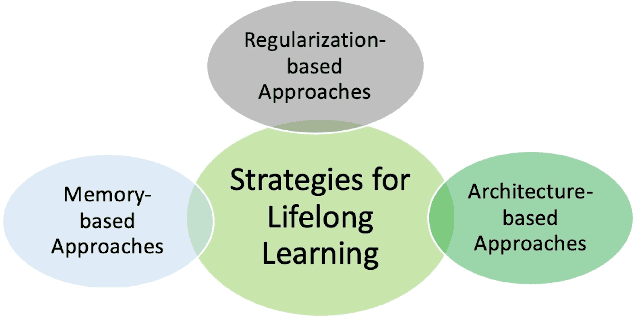
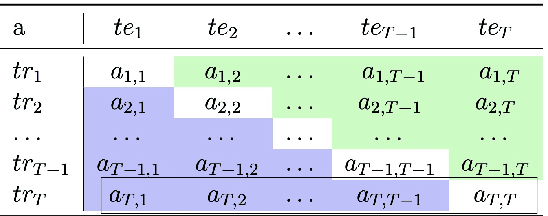
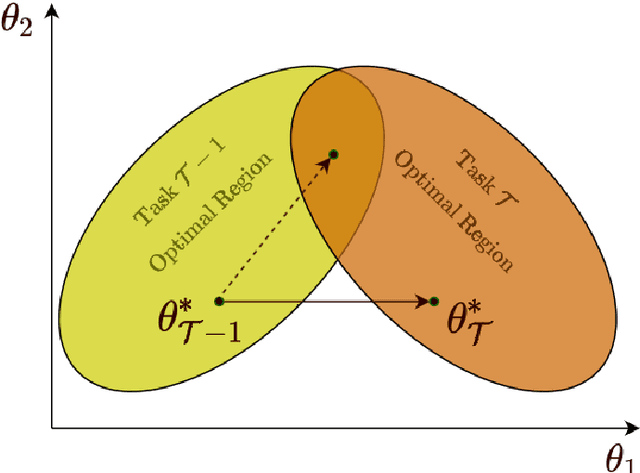
This primer is an attempt to provide a detailed summary of the different facets of lifelong learning. We start with Chapter 2 which provides a high-level overview of lifelong learning systems. In this chapter, we discuss prominent scenarios in lifelong learning (Section 2.4), provide 8 Introduction a high-level organization of different lifelong learning approaches (Section 2.5), enumerate the desiderata for an ideal lifelong learning system (Section 2.6), discuss how lifelong learning is related to other learning paradigms (Section 2.7), describe common metrics used to evaluate lifelong learning systems (Section 2.8). This chapter is more useful for readers who are new to lifelong learning and want to get introduced to the field without focusing on specific approaches or benchmarks. The remaining chapters focus on specific aspects (either learning algorithms or benchmarks) and are more useful for readers who are looking for specific approaches or benchmarks. Chapter 3 focuses on regularization-based approaches that do not assume access to any data from previous tasks. Chapter 4 discusses memory-based approaches that typically use a replay buffer or an episodic memory to save subset of data across different tasks. Chapter 5 focuses on different architecture families (and their instantiations) that have been proposed for training lifelong learning systems. Following these different classes of learning algorithms, we discuss the commonly used evaluation benchmarks and metrics for lifelong learning (Chapter 6) and wrap up with a discussion of future challenges and important research directions in Chapter 7.
SAND-mask: An Enhanced Gradient Masking Strategy for the Discovery of Invariances in Domain Generalization
Jun 04, 2021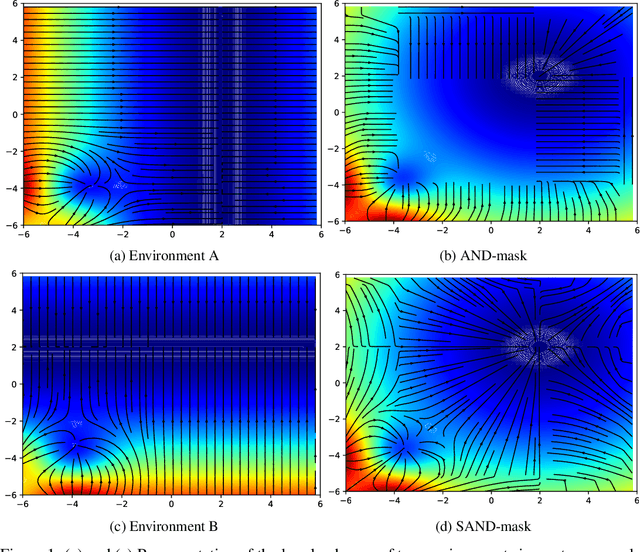
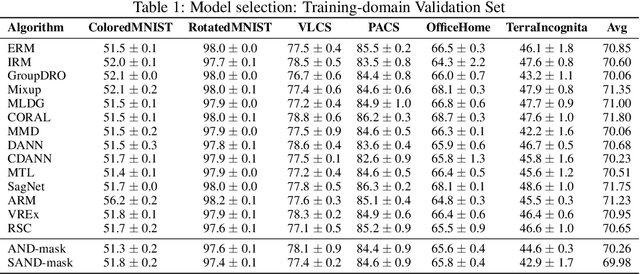
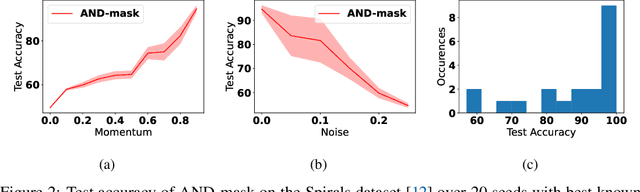
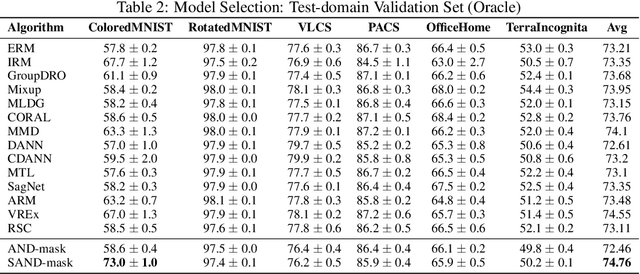
A major bottleneck in the real-world applications of machine learning models is their failure in generalizing to unseen domains whose data distribution is not i.i.d to the training domains. This failure often stems from learning non-generalizable features in the training domains that are spuriously correlated with the label of data. To address this shortcoming, there has been a growing surge of interest in learning good explanations that are hard to vary, which is studied under the notion of Out-of-Distribution (OOD) Generalization. The search for good explanations that are \textit{invariant} across different domains can be seen as finding local (global) minimas in the loss landscape that hold true across all of the training domains. In this paper, we propose a masking strategy, which determines a continuous weight based on the agreement of gradients that flow in each edge of network, in order to control the amount of update received by the edge in each step of optimization. Particularly, our proposed technique referred to as "Smoothed-AND (SAND)-masking", not only validates the agreement in the direction of gradients but also promotes the agreement among their magnitudes to further ensure the discovery of invariances across training domains. SAND-mask is validated over the Domainbed benchmark for domain generalization and significantly improves the state-of-the-art accuracy on the Colored MNIST dataset while providing competitive results on other domain generalization datasets.
IIRC: Incremental Implicitly-Refined Classification
Jan 11, 2021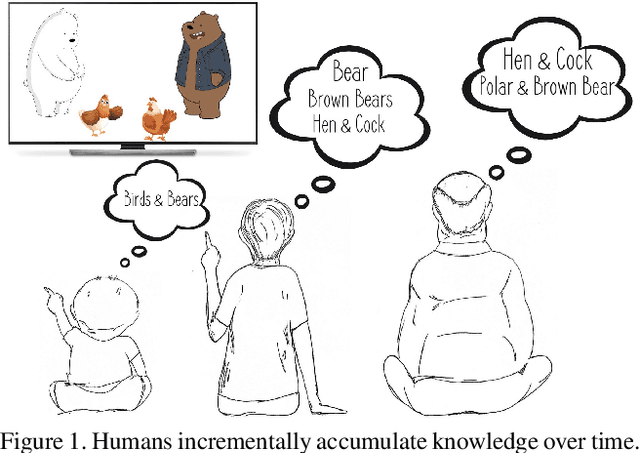

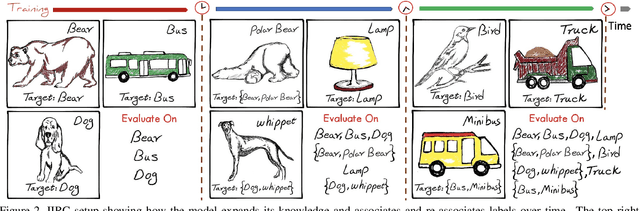

We introduce the "Incremental Implicitly-Refined Classi-fication (IIRC)" setup, an extension to the class incremental learning setup where the incoming batches of classes have two granularity levels. i.e., each sample could have a high-level (coarse) label like "bear" and a low-level (fine) label like "polar bear". Only one label is provided at a time, and the model has to figure out the other label if it has already learnfed it. This setup is more aligned with real-life scenarios, where a learner usually interacts with the same family of entities multiple times, discovers more granularity about them, while still trying not to forget previous knowledge. Moreover, this setup enables evaluating models for some important lifelong learning challenges that cannot be easily addressed under the existing setups. These challenges can be motivated by the example "if a model was trained on the class bear in one task and on polar bear in another task, will it forget the concept of bear, will it rightfully infer that a polar bear is still a bear? and will it wrongfully associate the label of polar bear to other breeds of bear?". We develop a standardized benchmark that enables evaluating models on the IIRC setup. We evaluate several state-of-the-art lifelong learning algorithms and highlight their strengths and limitations. For example, distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image. We hope that the proposed setup, along with the benchmark, would provide a meaningful problem setting to the practitioners
PatchUp: A Regularization Technique for Convolutional Neural Networks
Jun 14, 2020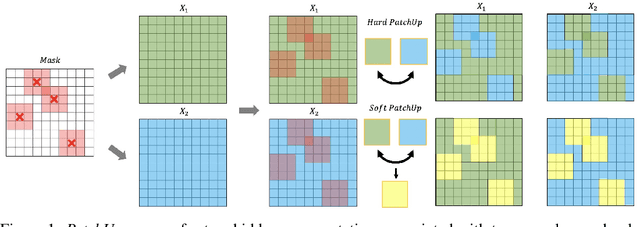
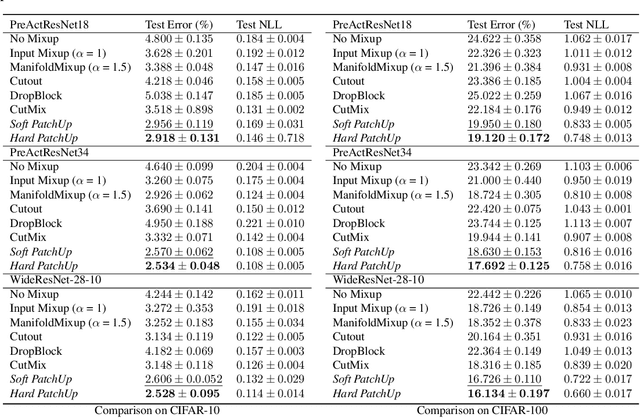
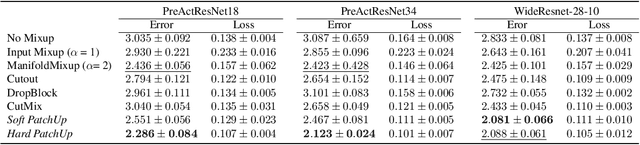
Large capacity deep learning models are often prone to a high generalization gap when trained with a limited amount of labeled training data. A recent class of methods to address this problem uses various ways to construct a new training sample by mixing a pair (or more) of training samples. We propose PatchUp, a hidden state block-level regularization technique for Convolutional Neural Networks (CNNs), that is applied on selected contiguous blocks of feature maps from a random pair of samples. Our approach improves the robustness of CNN models against the manifold intrusion problem that may occur in other state-of-the-art mixing approaches like Mixup and CutMix. Moreover, since we are mixing the contiguous block of features in the hidden space, which has more dimensions than the input space, we obtain more diverse samples for training towards different dimensions. Our experiments on CIFAR-10, CIFAR-100, and SVHN datasets with PreactResnet18, PreactResnet34, and WideResnet-28-10 models show that PatchUp improves upon, or equals, the performance of current state-of-the-art regularizers for CNNs. We also show that PatchUp can provide better generalization to affine transformations of samples and is more robust against adversarial attacks.