 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Batch Sizes Using Non-Euclidean Gradient Noise Scales for Stochastic Sign and Spectral Descent
Feb 03, 2026To maximize hardware utilization, modern machine learning systems typically employ large constant or manually tuned batch size schedules, relying on heuristics that are brittle and costly to tune. Existing adaptive strategies based on gradient noise scale (GNS) offer a principled alternative. However, their assumption of SGD's Euclidean geometry creates a fundamental mismatch with popular optimizers based on generalized norms, such as signSGD / Signum ($\ell_\infty$) and stochastic spectral descent (specSGD) / Muon ($\mathcal{S}_\infty$). In this work, we derive gradient noise scales for signSGD and specSGD that naturally emerge from the geometry of their respective dual norms. To practically estimate these non-Euclidean metrics, we propose an efficient variance estimation procedure that leverages the local mini-batch gradients on different ranks in distributed data-parallel systems. Our experiments demonstrate that adaptive batch size strategies using non-Euclidean GNS enable us to match the validation loss of constant-batch baselines while reducing training steps by up to 66% for Signum and Muon on a 160 million parameter Llama model.
Image Tiling for High-Resolution Reasoning: Balancing Local Detail with Global Context
Dec 11, 2025Reproducibility remains a cornerstone of scientific progress, yet complex multimodal models often lack transparent implementation details and accessible training infrastructure. In this work, we present a detailed reproduction and critical analysis of the Monkey Vision-Language Model (VLM) (Li et al. 2023b) published in CVPR24, a recent approach to high-resolution image understanding via image tiling. The original paper proposed splitting large images into tiles to recover fine-grained visual details while maintaining computational efficiency. Our study replicates this strategy using open checkpoints and reimplements the training pipeline. We confirm the key finding of the original Monkey VLM work, namely that tiling effectively recovers local details. We then extend this work further, by investigating the effect of the inclusion of the global context, which provide practical insights for future high-resolution multimodal modeling. However, we also report deviations in the results, with the magnitude of these effects depending heavily on task type and tile granularity.
Small Vocabularies, Big Gains: Pretraining and Tokenization in Time Series Models
Nov 06, 2025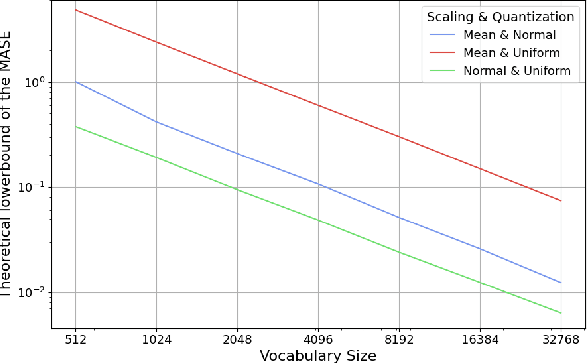
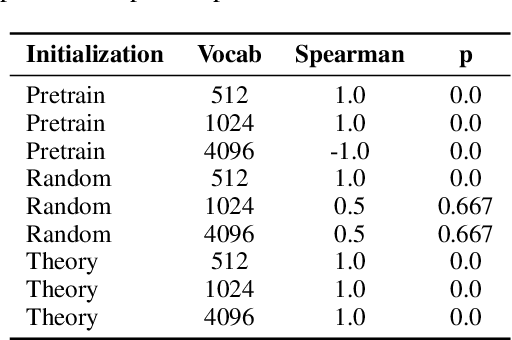
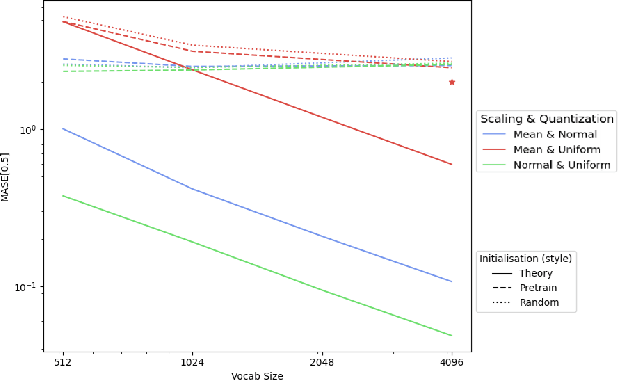
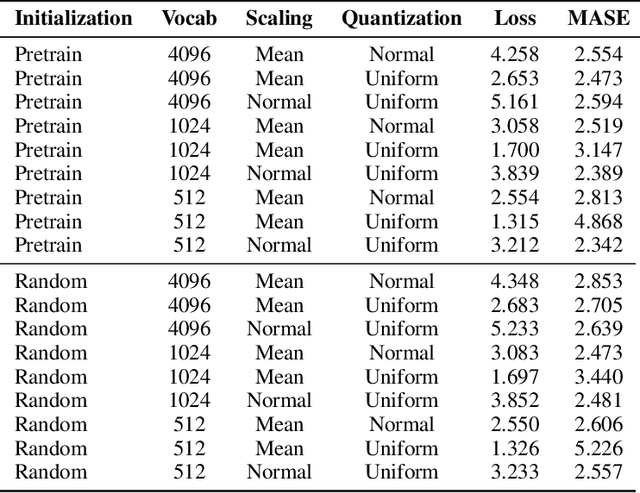
Tokenization and transfer learning are two critical components in building state of the art time series foundation models for forecasting. In this work, we systematically study the effect of tokenizer design, specifically scaling and quantization strategies, on model performance, alongside the impact of pretraining versus random initialization. We show that tokenizer configuration primarily governs the representational capacity and stability of the model, while transfer learning influences optimization efficiency and alignment. Using a combination of empirical training experiments and theoretical analyses, we demonstrate that pretrained models consistently leverage well-designed tokenizers more effectively, particularly at smaller vocabulary sizes. Conversely, misaligned tokenization can diminish or even invert the benefits of pretraining. These findings highlight the importance of careful tokenization in time series modeling and suggest that combining small, efficient vocabularies with pretrained weights is especially advantageous in multi-modal forecasting settings, where the overall vocabulary must be shared across modalities. Our results provide concrete guidance for designing tokenizers and leveraging transfer learning in discrete representation learning for continuous signals.
CAVE: Detecting and Explaining Commonsense Anomalies in Visual Environments
Oct 29, 2025Humans can naturally identify, reason about, and explain anomalies in their environment. In computer vision, this long-standing challenge remains limited to industrial defects or unrealistic, synthetically generated anomalies, failing to capture the richness and unpredictability of real-world anomalies. In this work, we introduce CAVE, the first benchmark of real-world visual anomalies. CAVE supports three open-ended tasks: anomaly description, explanation, and justification; with fine-grained annotations for visual grounding and categorizing anomalies based on their visual manifestations, their complexity, severity, and commonness. These annotations draw inspiration from cognitive science research on how humans identify and resolve anomalies, providing a comprehensive framework for evaluating Vision-Language Models (VLMs) in detecting and understanding anomalies. We show that state-of-the-art VLMs struggle with visual anomaly perception and commonsense reasoning, even with advanced prompting strategies. By offering a realistic and cognitively grounded benchmark, CAVE serves as a valuable resource for advancing research in anomaly detection and commonsense reasoning in VLMs.
Warming Up for Zeroth-Order Federated Pre-Training with Low Resource Clients
Sep 03, 2025Federated learning enables collaborative model training across numerous edge devices without requiring participants to share data; however, memory and communication constraints on these edge devices may preclude their participation in training. We consider a setting in which a subset of edge devices are below a critical memory or communication threshold required to conduct model updates. Under typical federated optimization algorithms, these devices are excluded from training which renders their data inaccessible and increases system induced bias. We are inspired by MeZO, a zeroth-order method used for memory-efficient fine-tuning. The increased variance inherent to zeroth-order gradient approximations has relegated previous zeroth-order optimizers exclusively to the domain of fine tuning; a limitation we seek to correct. We devise a federated, memory-efficient zeroth-order optimizer, ZOWarmUp that permits zeroth-order training from a random initialization. ZOWarmUp leverages differing client capabilities and careful variance reduction techniques to facilitate participation of under-represented, low-resource clients in model training. Like other federated zeroth-order methods, ZOWarmUp eliminates the need for edge devices to transmit their full gradients to the server and instead relies on only a small set of random seeds, rendering the up-link communication cost negligible. We present experiments using various datasets and model architectures to show that ZOWarmUp is a robust algorithm that can can be applied under a wide variety of circumstances. For systems with a high proportion of edge devices that would otherwise be excluded from training, this algorithm provides access to a greater volume and diversity of data, thus improving training outcomes.
Beyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs
Aug 13, 2025Forecasting in real-world settings requires models to integrate not only historical data but also relevant contextual information, often available in textual form. While recent work has shown that large language models (LLMs) can be effective context-aided forecasters via na\"ive direct prompting, their full potential remains underexplored. We address this gap with 4 strategies, providing new insights into the zero-shot capabilities of LLMs in this setting. ReDP improves interpretability by eliciting explicit reasoning traces, allowing us to assess the model's reasoning over the context independently from its forecast accuracy. CorDP leverages LLMs solely to refine existing forecasts with context, enhancing their applicability in real-world forecasting pipelines. IC-DP proposes embedding historical examples of context-aided forecasting tasks in the prompt, substantially improving accuracy even for the largest models. Finally, RouteDP optimizes resource efficiency by using LLMs to estimate task difficulty, and routing the most challenging tasks to larger models. Evaluated on different kinds of context-aided forecasting tasks from the CiK benchmark, our strategies demonstrate distinct benefits over na\"ive prompting across LLMs of different sizes and families. These results open the door to further simple yet effective improvements in LLM-based context-aided forecasting.
Persistent Instability in LLM's Personality Measurements: Effects of Scale, Reasoning, and Conversation History
Aug 06, 2025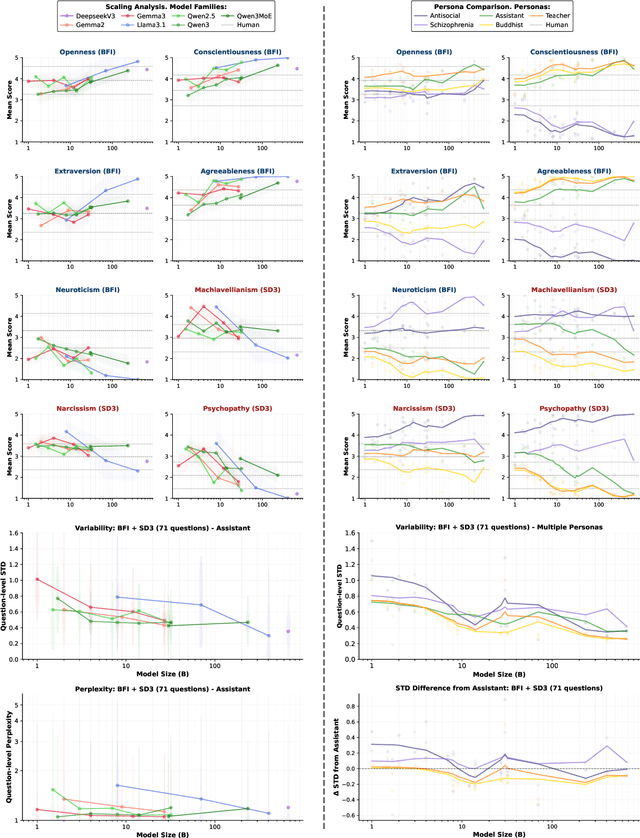
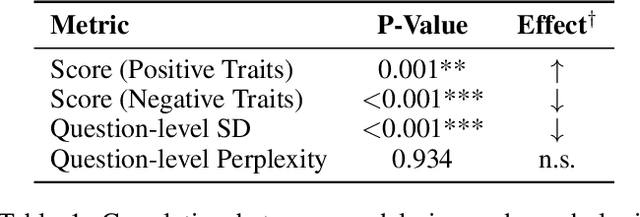
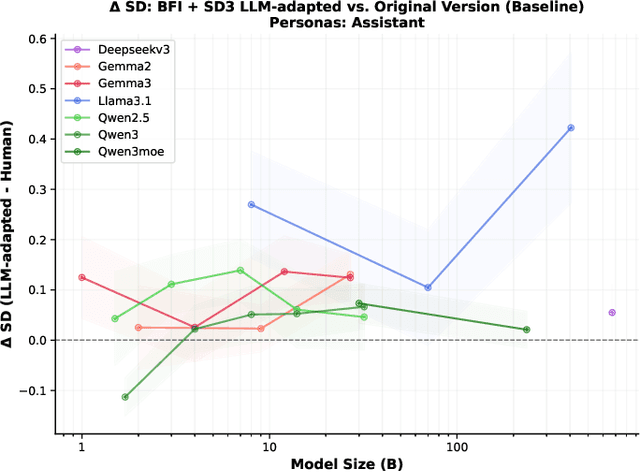

Large language models require consistent behavioral patterns for safe deployment, yet their personality-like traits remain poorly understood. We present PERSIST (PERsonality Stability in Synthetic Text), a comprehensive evaluation framework testing 25+ open-source models (1B-671B parameters) across 500,000+ responses. Using traditional (BFI-44, SD3) and novel LLM-adapted personality instruments, we systematically vary question order, paraphrasing, personas, and reasoning modes. Our findings challenge fundamental deployment assumptions: (1) Even 400B+ models exhibit substantial response variability (SD > 0.4); (2) Minor prompt reordering alone shifts personality measurements by up to 20%; (3) Interventions expected to stabilize behavior, such as chain-of-thought reasoning, detailed personas instruction, inclusion of conversation history, can paradoxically increase variability; (4) LLM-adapted instruments show equal instability to human-centric versions, confirming architectural rather than translational limitations. This persistent instability across scales and mitigation strategies suggests current LLMs lack the foundations for genuine behavioral consistency. For safety-critical applications requiring predictable behavior, these findings indicate that personality-based alignment strategies may be fundamentally inadequate.
GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Jul 16, 2025
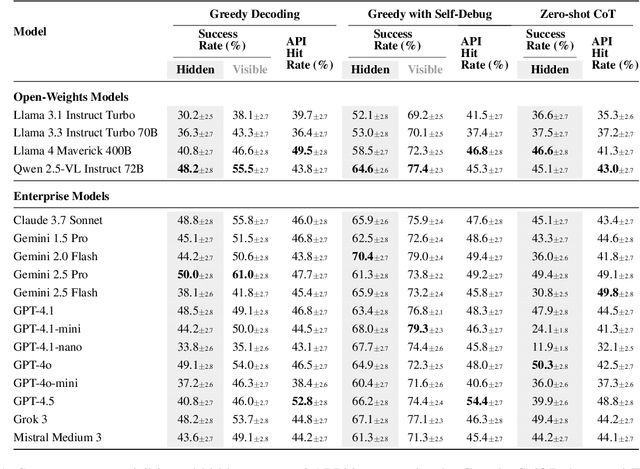
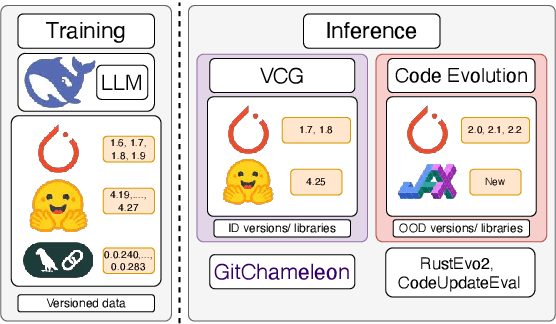
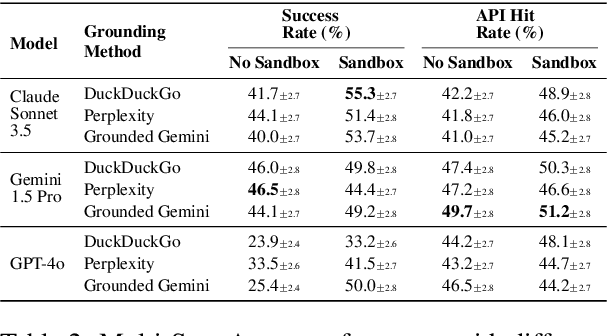
The rapid evolution of software libraries poses a considerable hurdle for code generation, necessitating continuous adaptation to frequent version updates while preserving backward compatibility. While existing code evolution benchmarks provide valuable insights, they typically lack execution-based evaluation for generating code compliant with specific library versions. To address this, we introduce GitChameleon, a novel, meticulously curated dataset comprising 328 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. GitChameleon rigorously evaluates the capacity of contemporary large language models (LLMs), LLM-powered agents, code assistants, and RAG systems to perform version-conditioned code generation that demonstrates functional accuracy through execution. Our extensive evaluations indicate that state-of-the-art systems encounter significant challenges with this task; enterprise models achieving baseline success rates in the 48-51\% range, underscoring the intricacy of the problem. By offering an execution-based benchmark emphasizing the dynamic nature of code libraries, GitChameleon enables a clearer understanding of this challenge and helps guide the development of more adaptable and dependable AI code generation methods. We make the dataset and evaluation code publicly available at https://github.com/mrcabbage972/GitChameleonBenchmark.
Training Dynamics Underlying Language Model Scaling Laws: Loss Deceleration and Zero-Sum Learning
Jun 05, 2025This work aims to understand how scaling improves language models, specifically in terms of training dynamics. We find that language models undergo loss deceleration early in training; an abrupt slowdown in the rate of loss improvement, resulting in piecewise linear behaviour of the loss curve in log-log space. Scaling up the model mitigates this transition by (1) decreasing the loss at which deceleration occurs, and (2) improving the log-log rate of loss improvement after deceleration. We attribute loss deceleration to a type of degenerate training dynamics we term zero-sum learning (ZSL). In ZSL, per-example gradients become systematically opposed, leading to destructive interference in per-example changes in loss. As a result, improving loss on one subset of examples degrades it on another, bottlenecking overall progress. Loss deceleration and ZSL provide new insights into the training dynamics underlying language model scaling laws, and could potentially be targeted directly to improve language models independent of scale. We make our code and artefacts available at: https://github.com/mirandrom/zsl
MuLoCo: Muon is a practical inner optimizer for DiLoCo
May 29, 2025DiLoCo is a powerful framework for training large language models (LLMs) under networking constraints with advantages for increasing parallelism and accelerator utilization in data center settings. Despite significantly reducing communication frequency, however, DiLoCo's communication steps still involve all-reducing a complete copy of the model's parameters. While existing works have explored ways to reduce communication in DiLoCo, the role of error feedback accumulators and the effect of the inner-optimizer on compressibility remain under-explored. In this work, we investigate the effectiveness of standard compression methods including Top-k sparsification and quantization for reducing the communication overhead of DiLoCo when paired with two local optimizers (AdamW and Muon). Our experiments pre-training decoder-only transformer language models (LMs) reveal that leveraging Muon as the inner optimizer for DiLoCo along with an error-feedback accumulator allows to aggressively compress the communicated delta to 2-bits with next to no performance degradation. Crucially, MuLoCo (Muon inner optimizer DiLoCo) significantly outperforms DiLoCo while communicating 8X less and having identical memory complexity.