 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
The Effectiveness of Approximate Regularized Replay for Efficient Supervised Fine-Tuning of Large Language Models
Dec 26, 2025Although parameter-efficient fine-tuning methods, such as LoRA, only modify a small subset of parameters, they can have a significant impact on the model. Our instruction-tuning experiments show that LoRA-based supervised fine-tuning can catastrophically degrade model capabilities, even when trained on very small datasets for relatively few steps. With that said, we demonstrate that while the most straightforward approach (that is likely the most used in practice) fails spectacularly, small tweaks to the training procedure with very little overhead can virtually eliminate the problem. Particularly, in this paper we consider a regularized approximate replay approach which penalizes KL divergence with respect to the initial model and interleaves in data for next token prediction from a different, yet similar, open access corpus to what was used in pre-training. When applied to Qwen instruction-tuned models, we find that this recipe preserves general knowledge in the model without hindering plasticity to new tasks by adding a modest amount of computational overhead.
Beyond Sliding Windows: Learning to Manage Memory in Non-Markovian Environments
Dec 22, 2025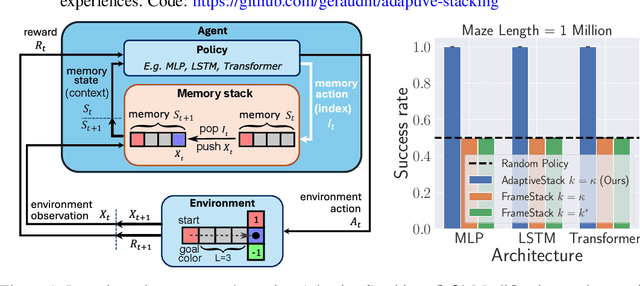

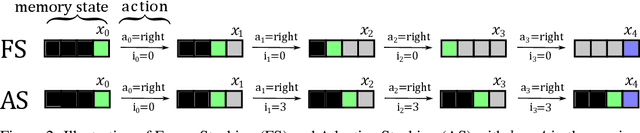

Recent success in developing increasingly general purpose agents based on sequence models has led to increased focus on the problem of deploying computationally limited agents within the vastly more complex real-world. A key challenge experienced in these more realistic domains is highly non-Markovian dependencies with respect to the agent's observations, which are less common in small controlled domains. The predominant approach for dealing with this in the literature is to stack together a window of the most recent observations (Frame Stacking), but this window size must grow with the degree of non-Markovian dependencies, which results in prohibitive computational and memory requirements for both action inference and learning. In this paper, we are motivated by the insight that in many environments that are highly non-Markovian with respect to time, the environment only causally depends on a relatively small number of observations over that time-scale. A natural direction would then be to consider meta-algorithms that maintain relatively small adaptive stacks of memories such that it is possible to express highly non-Markovian dependencies with respect to time while considering fewer observations at each step and thus experience substantial savings in both compute and memory requirements. Hence, we propose a meta-algorithm (Adaptive Stacking) for achieving exactly that with convergence guarantees and quantify the reduced computation and memory constraints for MLP, LSTM, and Transformer-based agents. Our experiments utilize popular memory tasks, which give us control over the degree of non-Markovian dependencies. This allows us to demonstrate that an appropriate meta-algorithm can learn the removal of memories not predictive of future rewards without excessive removal of important experiences. Code: https://github.com/geraudnt/adaptive-stacking
Handling Delay in Real-Time Reinforcement Learning
Mar 30, 2025Real-time reinforcement learning (RL) introduces several challenges. First, policies are constrained to a fixed number of actions per second due to hardware limitations. Second, the environment may change while the network is still computing an action, leading to observational delay. The first issue can partly be addressed with pipelining, leading to higher throughput and potentially better policies. However, the second issue remains: if each neuron operates in parallel with an execution time of $\tau$, an $N$-layer feed-forward network experiences observation delay of $\tau N$. Reducing the number of layers can decrease this delay, but at the cost of the network's expressivity. In this work, we explore the trade-off between minimizing delay and network's expressivity. We present a theoretically motivated solution that leverages temporal skip connections combined with history-augmented observations. We evaluate several architectures and show that those incorporating temporal skip connections achieve strong performance across various neuron execution times, reinforcement learning algorithms, and environments, including four Mujoco tasks and all MinAtar games. Moreover, we demonstrate parallel neuron computation can accelerate inference by 6-350% on standard hardware. Our investigation into temporal skip connections and parallel computations paves the way for more efficient RL agents in real-time setting.
EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts
Feb 20, 2025



Recent advances in Large Language Models (LLMs) have yielded impressive successes on many language tasks. However, efficient processing of long contexts using LLMs remains a significant challenge. We introduce \textbf{EpMAN} -- a method for processing long contexts in an \textit{episodic memory} module while \textit{holistically attending to} semantically relevant context chunks. The output of \textit{episodic attention} is then used to reweigh the decoder's self-attention to the stored KV cache of the context during training and generation. When an LLM decoder is trained using \textbf{EpMAN}, its performance on multiple challenging single-hop long-context recall and question-answering benchmarks is found to be stronger and more robust across the range from 16k to 256k tokens than baseline decoders trained with self-attention, and popular retrieval-augmented generation frameworks.
Can Large Language Models Adapt to Other Agents In-Context?
Dec 27, 2024As the research community aims to build better AI assistants that are more dynamic and personalized to the diversity of humans that they interact with, there is increased interest in evaluating the theory of mind capabilities of large language models (LLMs). Indeed, several recent studies suggest that LLM theory of mind capabilities are quite impressive, approximating human-level performance. Our paper aims to rebuke this narrative and argues instead that past studies were not directly measuring agent performance, potentially leading to findings that are illusory in nature as a result. We draw a strong distinction between what we call literal theory of mind i.e. measuring the agent's ability to predict the behavior of others and functional theory of mind i.e. adapting to agents in-context based on a rational response to predictions of their behavior. We find that top performing open source LLMs may display strong capabilities in literal theory of mind, depending on how they are prompted, but seem to struggle with functional theory of mind -- even when partner policies are exceedingly simple. Our work serves to highlight the double sided nature of inductive bias in LLMs when adapting to new situations. While this bias can lead to strong performance over limited horizons, it often hinders convergence to optimal long-term behavior.
Enabling Realtime Reinforcement Learning at Scale with Staggered Asynchronous Inference
Dec 18, 2024



Realtime environments change even as agents perform action inference and learning, thus requiring high interaction frequencies to effectively minimize regret. However, recent advances in machine learning involve larger neural networks with longer inference times, raising questions about their applicability in realtime systems where reaction time is crucial. We present an analysis of lower bounds on regret in realtime reinforcement learning (RL) environments to show that minimizing long-term regret is generally impossible within the typical sequential interaction and learning paradigm, but often becomes possible when sufficient asynchronous compute is available. We propose novel algorithms for staggering asynchronous inference processes to ensure that actions are taken at consistent time intervals, and demonstrate that use of models with high action inference times is only constrained by the environment's effective stochasticity over the inference horizon, and not by action frequency. Our analysis shows that the number of inference processes needed scales linearly with increasing inference times while enabling use of models that are multiple orders of magnitude larger than existing approaches when learning from a realtime simulation of Game Boy games such as Pok\'emon and Tetris.
Combining Domain and Alignment Vectors to Achieve Better Knowledge-Safety Trade-offs in LLMs
Nov 11, 2024



There is a growing interest in training domain-expert LLMs that excel in specific technical fields compared to their general-purpose instruction-tuned counterparts. However, these expert models often experience a loss in their safety abilities in the process, making them capable of generating harmful content. As a solution, we introduce an efficient and effective merging-based alignment method called \textsc{MergeAlign} that interpolates the domain and alignment vectors, creating safer domain-specific models while preserving their utility. We apply \textsc{MergeAlign} on Llama3 variants that are experts in medicine and finance, obtaining substantial alignment improvements with minimal to no degradation on domain-specific benchmarks. We study the impact of model merging through model similarity metrics and contributions of individual models being merged. We hope our findings open new research avenues and inspire more efficient development of safe expert LLMs.
Game-Theoretical Perspectives on Active Equilibria: A Preferred Solution Concept over Nash Equilibria
Oct 28, 2022
Multiagent learning settings are inherently more difficult than single-agent learning because each agent interacts with other simultaneously learning agents in a shared environment. An effective approach in multiagent reinforcement learning is to consider the learning process of agents and influence their future policies toward desirable behaviors from each agent's perspective. Importantly, if each agent maximizes its long-term rewards by accounting for the impact of its behavior on the set of convergence policies, the resulting multiagent system reaches an active equilibrium. While this new solution concept is general such that standard solution concepts, such as a Nash equilibrium, are special cases of active equilibria, it is unclear when an active equilibrium is a preferred equilibrium over other solution concepts. In this paper, we analyze active equilibria from a game-theoretic perspective by closely studying examples where Nash equilibria are known. By directly comparing active equilibria to Nash equilibria in these examples, we find that active equilibria find more effective solutions than Nash equilibria, concluding that an active equilibrium is the desired solution for multiagent learning settings.
Influencing Long-Term Behavior in Multiagent Reinforcement Learning
Mar 07, 2022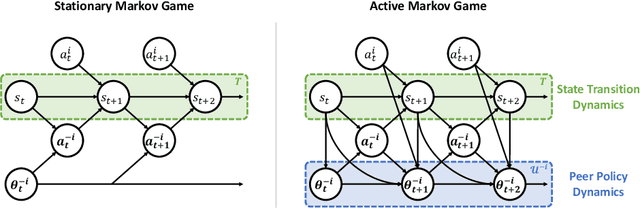
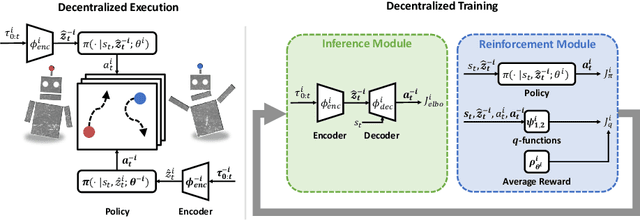
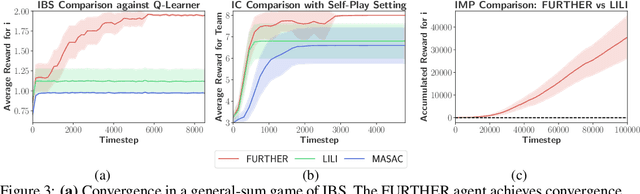
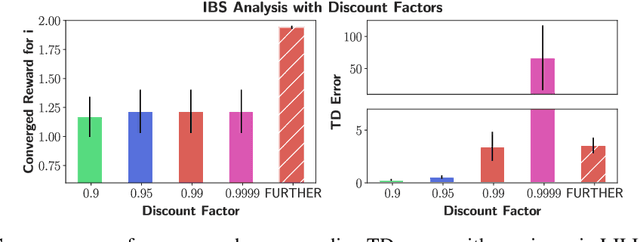
The main challenge of multiagent reinforcement learning is the difficulty of learning useful policies in the presence of other simultaneously learning agents whose changing behaviors jointly affect the environment's transition and reward dynamics. An effective approach that has recently emerged for addressing this non-stationarity is for each agent to anticipate the learning of other interacting agents and influence the evolution of their future policies towards desirable behavior for its own benefit. Unfortunately, all previous approaches for achieving this suffer from myopic evaluation, considering only a few or a finite number of updates to the policies of other agents. In this paper, we propose a principled framework for considering the limiting policies of other agents as the time approaches infinity. Specifically, we develop a new optimization objective that maximizes each agent's average reward by directly accounting for the impact of its behavior on the limiting set of policies that other agents will take on. Thanks to our farsighted evaluation, we demonstrate better long-term performance than state-of-the-art baselines in various domains, including the full spectrum of general-sum, competitive, and cooperative settings.