 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Scaling Laws for Data Source Utility Estimation in Domain-Specific Pre-Training
Jul 29, 2025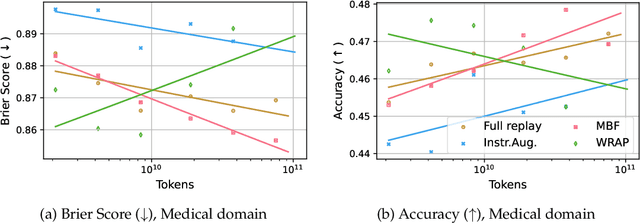
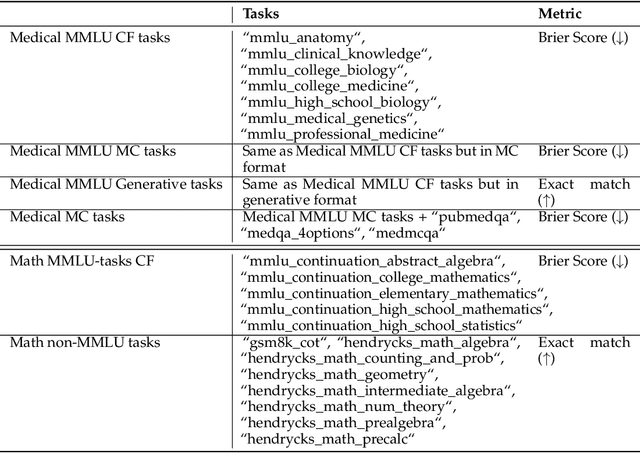
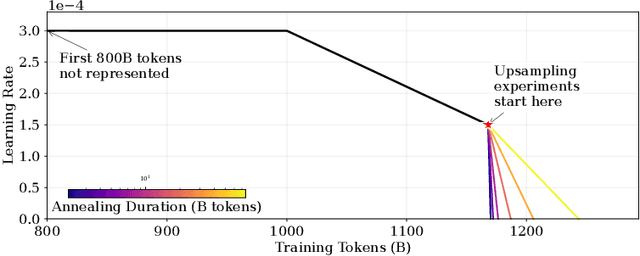
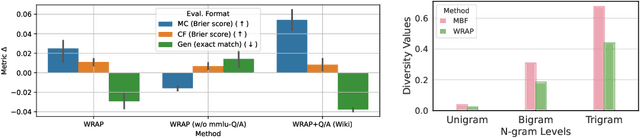
We introduce a framework for optimizing domain-specific dataset construction in foundation model training. Specifically, we seek a cost-efficient way to estimate the quality of data sources (e.g. synthetically generated or filtered web data, etc.) in order to make optimal decisions about resource allocation for data sourcing from these sources for the stage two pre-training phase, aka annealing, with the goal of specializing a generalist pre-trained model to specific domains. Our approach extends the usual point estimate approaches, aka micro-annealing, to estimating scaling laws by performing multiple annealing runs of varying compute spent on data curation and training. This addresses a key limitation in prior work, where reliance on point estimates for data scaling decisions can be misleading due to the lack of rank invariance across compute scales -- a phenomenon we confirm in our experiments. By systematically analyzing performance gains relative to acquisition costs, we find that scaling curves can be estimated for different data sources. Such scaling laws can inform cost effective resource allocation across different data acquisition methods (e.g. synthetic data), data sources (e.g. user or web data) and available compute resources. We validate our approach through experiments on a pre-trained model with 7 billion parameters. We adapt it to: a domain well-represented in the pre-training data -- the medical domain, and a domain underrepresented in the pretraining corpora -- the math domain. We show that one can efficiently estimate the scaling behaviors of a data source by running multiple annealing runs, which can lead to different conclusions, had one used point estimates using the usual micro-annealing technique instead. This enables data-driven decision-making for selecting and optimizing data sources.
Pretraining Generative Flow Networks with Inexpensive Rewards for Molecular Graph Generation
Mar 08, 2025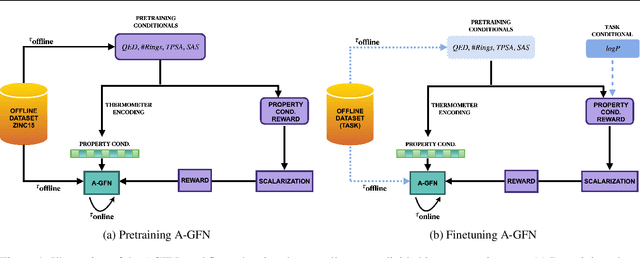



Generative Flow Networks (GFlowNets) have recently emerged as a suitable framework for generating diverse and high-quality molecular structures by learning from rewards treated as unnormalized distributions. Previous works in this framework often restrict exploration by using predefined molecular fragments as building blocks, limiting the chemical space that can be accessed. In this work, we introduce Atomic GFlowNets (A-GFNs), a foundational generative model leveraging individual atoms as building blocks to explore drug-like chemical space more comprehensively. We propose an unsupervised pre-training approach using drug-like molecule datasets, which teaches A-GFNs about inexpensive yet informative molecular descriptors such as drug-likeliness, topological polar surface area, and synthetic accessibility scores. These properties serve as proxy rewards, guiding A-GFNs towards regions of chemical space that exhibit desirable pharmacological properties. We further implement a goal-conditioned finetuning process, which adapts A-GFNs to optimize for specific target properties. In this work, we pretrain A-GFN on a subset of ZINC dataset, and by employing robust evaluation metrics we show the effectiveness of our approach when compared to other relevant baseline methods for a wide range of drug design tasks.
Enabling Realtime Reinforcement Learning at Scale with Staggered Asynchronous Inference
Dec 18, 2024



Realtime environments change even as agents perform action inference and learning, thus requiring high interaction frequencies to effectively minimize regret. However, recent advances in machine learning involve larger neural networks with longer inference times, raising questions about their applicability in realtime systems where reaction time is crucial. We present an analysis of lower bounds on regret in realtime reinforcement learning (RL) environments to show that minimizing long-term regret is generally impossible within the typical sequential interaction and learning paradigm, but often becomes possible when sufficient asynchronous compute is available. We propose novel algorithms for staggering asynchronous inference processes to ensure that actions are taken at consistent time intervals, and demonstrate that use of models with high action inference times is only constrained by the environment's effective stochasticity over the inference horizon, and not by action frequency. Our analysis shows that the number of inference processes needed scales linearly with increasing inference times while enabling use of models that are multiple orders of magnitude larger than existing approaches when learning from a realtime simulation of Game Boy games such as Pok\'emon and Tetris.
Seq-VCR: Preventing Collapse in Intermediate Transformer Representations for Enhanced Reasoning
Nov 04, 2024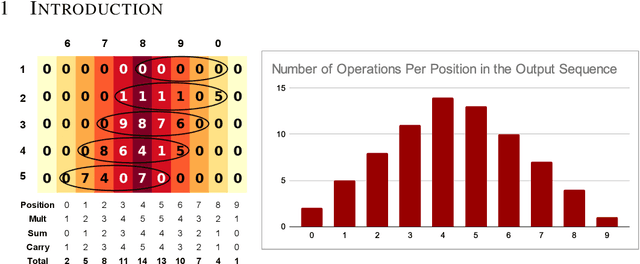
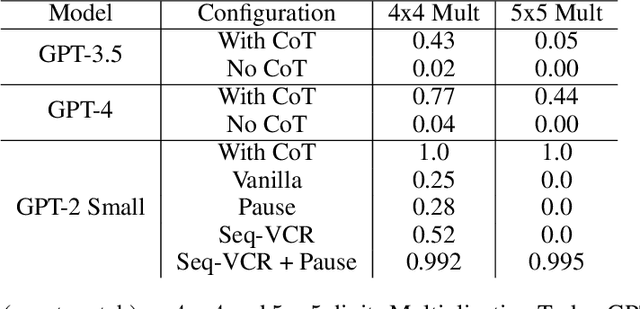
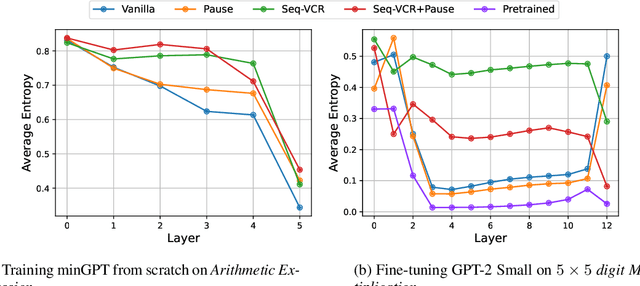
Decoder-only Transformers often struggle with complex reasoning tasks, particularly arithmetic reasoning requiring multiple sequential operations. In this work, we identify representation collapse in the model's intermediate layers as a key factor limiting their reasoning capabilities. To address this, we propose Sequential Variance-Covariance Regularization (Seq-VCR), which enhances the entropy of intermediate representations and prevents collapse. Combined with dummy pause tokens as substitutes for chain-of-thought (CoT) tokens, our method significantly improves performance in arithmetic reasoning problems. In the challenging $5 \times 5$ integer multiplication task, our approach achieves $99.5\%$ exact match accuracy, outperforming models of the same size (which yield $0\%$ accuracy) and GPT-4 with five-shot CoT prompting ($44\%$). We also demonstrate superior results on arithmetic expression and longest increasing subsequence (LIS) datasets. Our findings highlight the importance of preventing intermediate layer representation collapse to enhance the reasoning capabilities of Transformers and show that Seq-VCR offers an effective solution without requiring explicit CoT supervision.
GFlowNet Pretraining with Inexpensive Rewards
Sep 15, 2024



Generative Flow Networks (GFlowNets), a class of generative models have recently emerged as a suitable framework for generating diverse and high-quality molecular structures by learning from unnormalized reward distributions. Previous works in this direction often restrict exploration by using predefined molecular fragments as building blocks, limiting the chemical space that can be accessed. In this work, we introduce Atomic GFlowNets (A-GFNs), a foundational generative model leveraging individual atoms as building blocks to explore drug-like chemical space more comprehensively. We propose an unsupervised pre-training approach using offline drug-like molecule datasets, which conditions A-GFNs on inexpensive yet informative molecular descriptors such as drug-likeliness, topological polar surface area, and synthetic accessibility scores. These properties serve as proxy rewards, guiding A-GFNs towards regions of chemical space that exhibit desirable pharmacological properties. We further our method by implementing a goal-conditioned fine-tuning process, which adapts A-GFNs to optimize for specific target properties. In this work, we pretrain A-GFN on the ZINC15 offline dataset and employ robust evaluation metrics to show the effectiveness of our approach when compared to other relevant baseline methods in drug design.
Continual Learning In Environments With Polynomial Mixing Times
Dec 13, 2021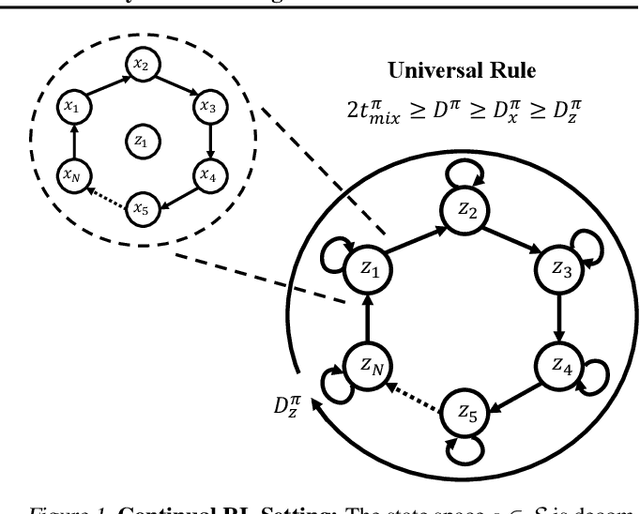

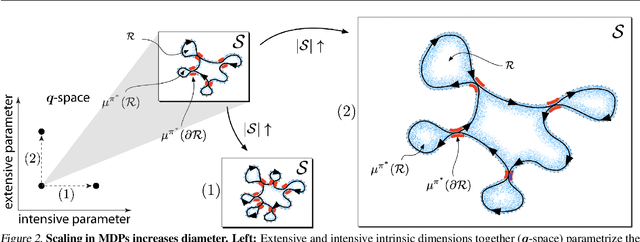
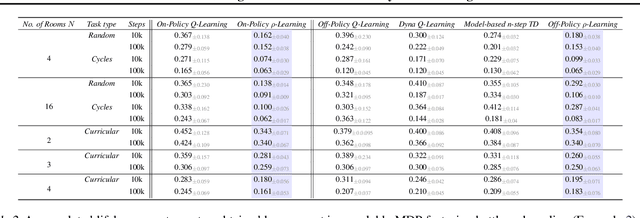
The mixing time of the Markov chain induced by a policy limits performance in real-world continual learning scenarios. Yet, the effect of mixing times on learning in continual reinforcement learning (RL) remains underexplored. In this paper, we characterize problems that are of long-term interest to the development of continual RL, which we call scalable MDPs, through the lens of mixing times. In particular, we establish that scalable MDPs have mixing times that scale polynomially with the size of the problem. We go on to demonstrate that polynomial mixing times present significant difficulties for existing approaches and propose a family of model-based algorithms that speed up learning by directly optimizing for the average reward through a novel bootstrapping procedure. Finally, we perform empirical regret analysis of our proposed approaches, demonstrating clear improvements over baselines and also how scalable MDPs can be used for analysis of RL algorithms as mixing times scale.