 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Online Skill and Memory Modules Always Worth Their Tokens? A Budget-Constrained Study of Web Agents
Jun 12, 2026Online web agents often augment a base actor with memory, workflow, or skill modules. These modules can improve performance, but they also consume test-time tokens, a cost rarely reported alongside the actor's inference cost. We study online augmentation, where this overhead is paid on every task, and re-evaluate its benefits under a fixed total inference budget. We compare AWM, ASI, and ReasoningBank with a token-matched vanilla baseline that uses the same budget for additional actor steps. Across three WebArena domains and three models, Gemini 3 Flash, GPT-5.4-mini, and Qwen 3.6-27B, the vanilla baseline matches or surpasses all three augmentation methods in aggregate success rate while often using fewer total tokens. We observe a similar trend on WorkArena-L1 with Qwen 3.6-27B, indicating that the effect extends to enterprise knowledge-work tasks. Our results suggest that skills and workflow memory can be useful in specific domains, but their apparent gains often vanish against a budget-matched actor. We further show that run-to-run variance materially affects outcomes and should be reported as a core evaluation criterion for online web agents.
CUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
Privileged Information Distillation for Language Models
Feb 04, 2026Training-time privileged information (PI) can enable language models to succeed on tasks they would otherwise fail, making it a powerful tool for reinforcement learning in hard, long-horizon settings. However, transferring capabilities learned with PI to policies that must act without it at inference time remains a fundamental challenge. We study this problem in the context of distilling frontier models for multi-turn agentic environments, where closed-source systems typically hide their internal reasoning and expose only action trajectories. This breaks standard distillation pipelines, since successful behavior is observable but the reasoning process is not. For this, we introduce π-Distill, a joint teacher-student objective that trains a PI-conditioned teacher and an unconditioned student simultaneously using the same model. Additionally, we also introduce On-Policy Self-Distillation (OPSD), an alternative approach that trains using Reinforcement Learning (RL) with a reverse KL-penalty between the student and the PI-conditioned teacher. We show that both of these algorithms effectively distill frontier agents using action-only PI. Specifically we find that π-Distill and in some cases OPSD, outperform industry standard practices (Supervised finetuning followed by RL) that assume access to full Chain-of-Thought supervision across multiple agentic benchmarks, models, and forms of PI. We complement our results with extensive analysis that characterizes the factors enabling effective learning with PI, focusing primarily on π-Distill and characterizing when OPSD is competitive.
Self-Evolving Curriculum for LLM Reasoning
May 20, 2025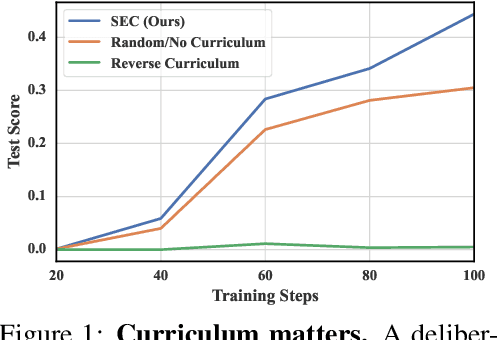
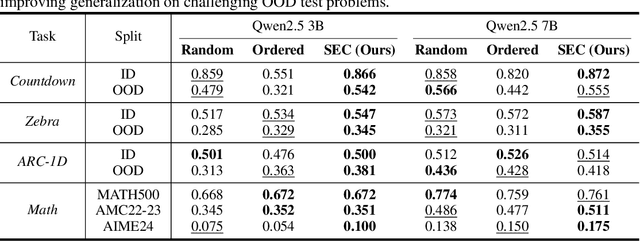
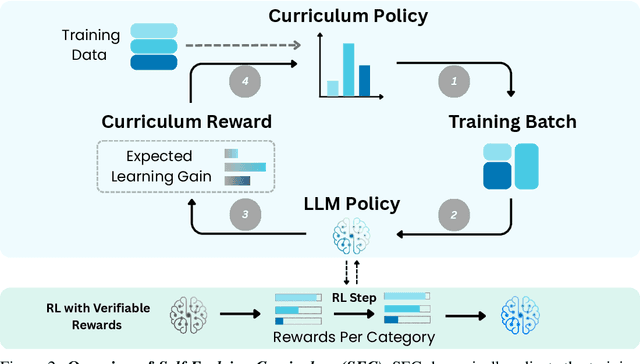
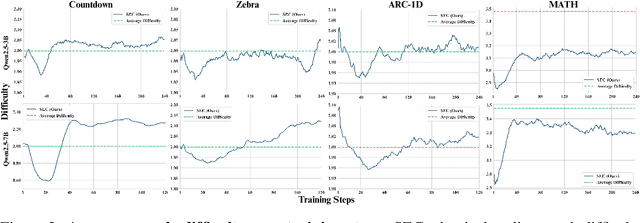
Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
TapeAgents: a Holistic Framework for Agent Development and Optimization
Dec 11, 2024



We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session's resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent's actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent's LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents's advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text -- a unique combination of features absent in previous work.
Seq-VCR: Preventing Collapse in Intermediate Transformer Representations for Enhanced Reasoning
Nov 04, 2024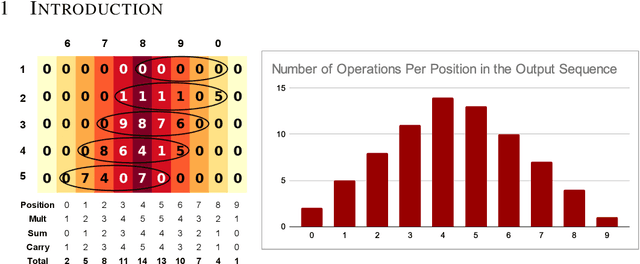
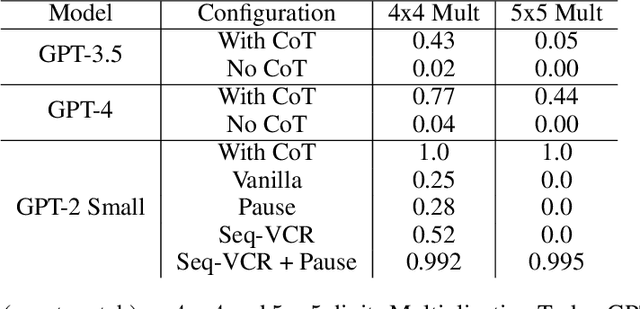
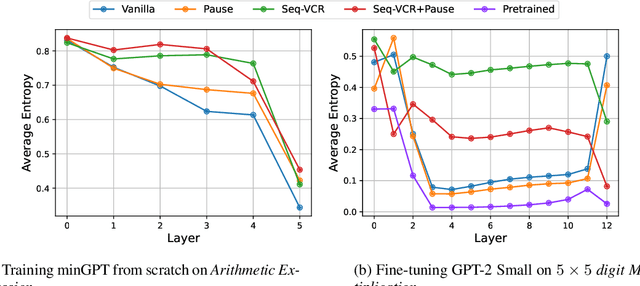
Decoder-only Transformers often struggle with complex reasoning tasks, particularly arithmetic reasoning requiring multiple sequential operations. In this work, we identify representation collapse in the model's intermediate layers as a key factor limiting their reasoning capabilities. To address this, we propose Sequential Variance-Covariance Regularization (Seq-VCR), which enhances the entropy of intermediate representations and prevents collapse. Combined with dummy pause tokens as substitutes for chain-of-thought (CoT) tokens, our method significantly improves performance in arithmetic reasoning problems. In the challenging $5 \times 5$ integer multiplication task, our approach achieves $99.5\%$ exact match accuracy, outperforming models of the same size (which yield $0\%$ accuracy) and GPT-4 with five-shot CoT prompting ($44\%$). We also demonstrate superior results on arithmetic expression and longest increasing subsequence (LIS) datasets. Our findings highlight the importance of preventing intermediate layer representation collapse to enhance the reasoning capabilities of Transformers and show that Seq-VCR offers an effective solution without requiring explicit CoT supervision.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Long-Context Language Decision Transformers and Exponential Tilt for Interactive Text Environments
Feb 10, 2023



Text-based game environments are challenging because agents must deal with long sequences of text, execute compositional actions using text and learn from sparse rewards. We address these challenges by proposing Long-Context Language Decision Transformers (LLDTs), a framework that is based on long transformer language models and decision transformers (DTs). LLDTs extend DTs with 3 components: (1) exponential tilt to guide the agent towards high obtainable goals, (2) novel goal conditioning methods yielding significantly better results than the traditional return-to-go (sum of all future rewards), and (3) a model of future observations. Our ablation results show that predicting future observations improves agent performance. To the best of our knowledge, LLDTs are the first to address offline RL with DTs on these challenging games. Our experiments show that LLDTs achieve the highest scores among many different types of agents on some of the most challenging Jericho games, such as Enchanter.
Does entity abstraction help generative Transformers reason?
Jan 05, 2022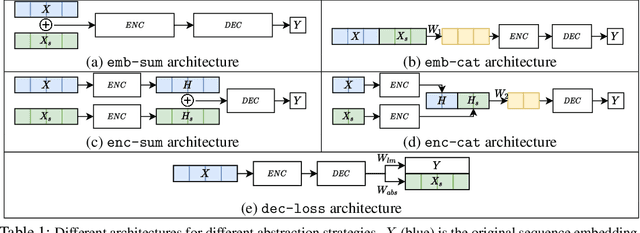


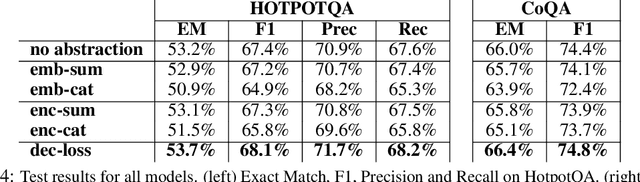
Pre-trained language models (LMs) often struggle to reason logically or generalize in a compositional fashion. Recent work suggests that incorporating external entity knowledge can improve LMs' abilities to reason and generalize. However, the effect of explicitly providing entity abstraction remains unclear, especially with recent studies suggesting that pre-trained LMs already encode some of that knowledge in their parameters. We study the utility of incorporating entity type abstractions into pre-trained Transformers and test these methods on four NLP tasks requiring different forms of logical reasoning: (1) compositional language understanding with text-based relational reasoning (CLUTRR), (2) abductive reasoning (ProofWriter), (3) multi-hop question answering (HotpotQA), and (4) conversational question answering (CoQA). We propose and empirically explore three ways to add such abstraction: (i) as additional input embeddings, (ii) as a separate sequence to encode, and (iii) as an auxiliary prediction task for the model. Overall, our analysis demonstrates that models with abstract entity knowledge performs better than without it. However, our experiments also show that the benefits strongly depend on the technique used and the task at hand. The best abstraction aware models achieved an overall accuracy of 88.8% and 91.8% compared to the baseline model achieving 62.3% and 89.8% on CLUTRR and ProofWriter respectively. In addition, abstraction-aware models showed improved compositional generalization in both interpolation and extrapolation settings. However, for HotpotQA and CoQA, we find that F1 scores improve by only 0.5% on average. Our results suggest that the benefit of explicit abstraction is significant in formally defined logical reasoning settings requiring many reasoning hops, but point to the notion that it is less beneficial for NLP tasks having less formal logical structure.
Measuring Systematic Generalization in Neural Proof Generation with Transformers
Oct 20, 2020

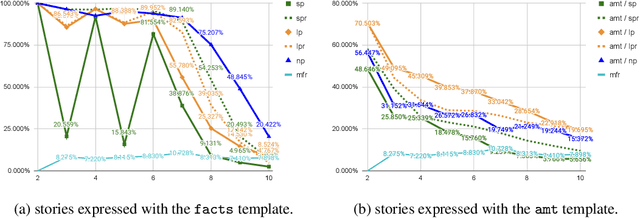
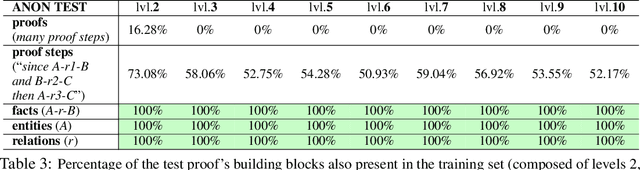
We are interested in understanding how well Transformer language models (TLMs) can perform reasoning tasks when trained on knowledge encoded in the form of natural language. We investigate their systematic generalization abilities on a logical reasoning task in natural language, which involves reasoning over relationships between entities grounded in first-order logical proofs. Specifically, we perform soft theorem-proving by leveraging TLMs to generate natural language proofs. We test the generated proofs for logical consistency, along with the accuracy of the final inference. We observe length-generalization issues when evaluated on longer-than-trained sequences. However, we observe TLMs improve their generalization performance after being exposed to longer, exhaustive proofs. In addition, we discover that TLMs are able to generalize better using backward-chaining proofs compared to their forward-chaining counterparts, while they find it easier to generate forward chaining proofs. We observe that models that are not trained to generate proofs are better at generalizing to problems based on longer proofs. This suggests that Transformers have efficient internal reasoning strategies that are harder to interpret. These results highlight the systematic generalization behavior of TLMs in the context of logical reasoning, and we believe this work motivates deeper inspection of their underlying reasoning strategies.