 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapeAgents: a Holistic Framework for Agent Development and Optimization
Dec 11, 2024



We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session's resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent's actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent's LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents's advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text -- a unique combination of features absent in previous work.
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023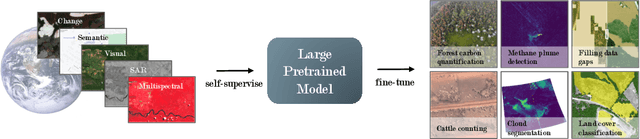
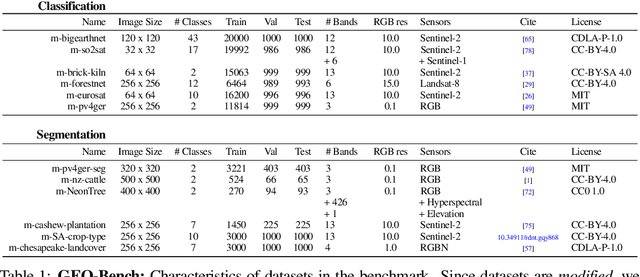

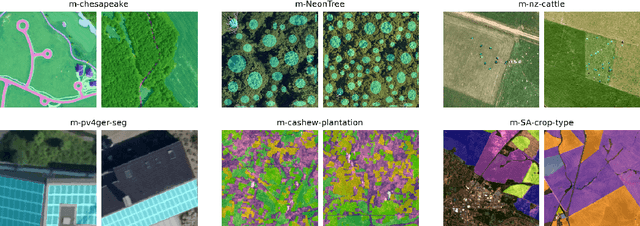
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
A Survey of Self-Supervised and Few-Shot Object Detection
Nov 08, 2021


Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions. Project page at https://gabrielhuang.github.io/fsod-survey/
Repurposing Pretrained Models for Robust Out-of-domain Few-Shot Learning
Mar 16, 2021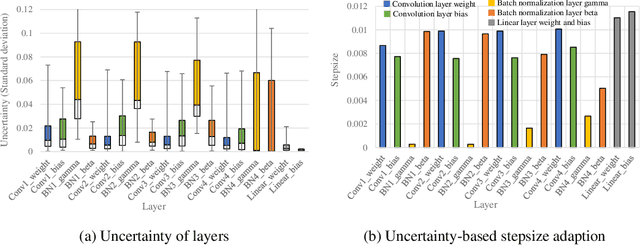
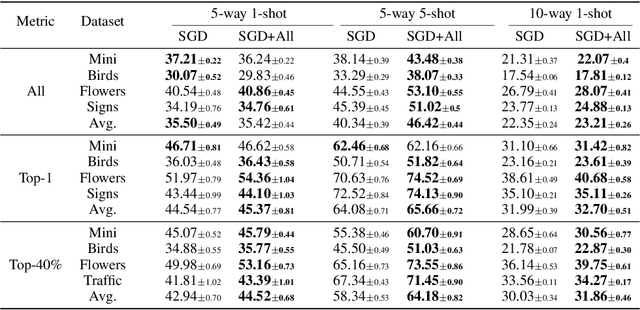
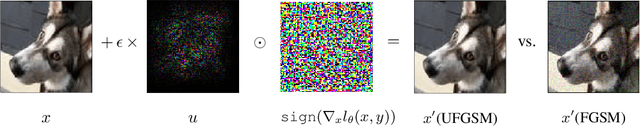
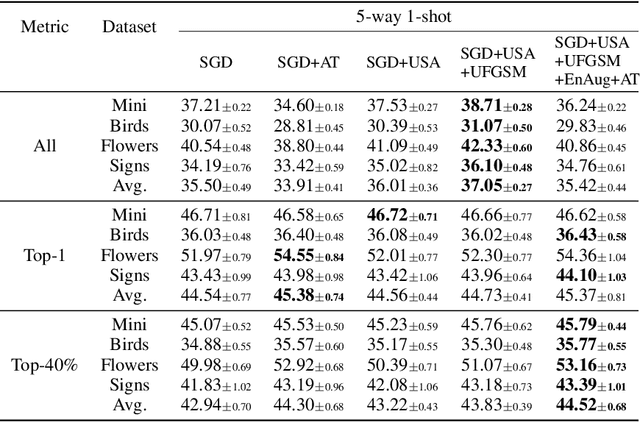
Model-agnostic meta-learning (MAML) is a popular method for few-shot learning but assumes that we have access to the meta-training set. In practice, training on the meta-training set may not always be an option due to data privacy concerns, intellectual property issues, or merely lack of computing resources. In this paper, we consider the novel problem of repurposing pretrained MAML checkpoints to solve new few-shot classification tasks. Because of the potential distribution mismatch, the original MAML steps may no longer be optimal. Therefore we propose an alternative meta-testing procedure and combine MAML gradient steps with adversarial training and uncertainty-based stepsize adaptation. Our method outperforms "vanilla" MAML on same-domain and cross-domains benchmarks using both SGD and Adam optimizers and shows improved robustness to the choice of base stepsize.
Centroid Networks for Few-Shot Clustering and Unsupervised Few-Shot Classification
Feb 22, 2019

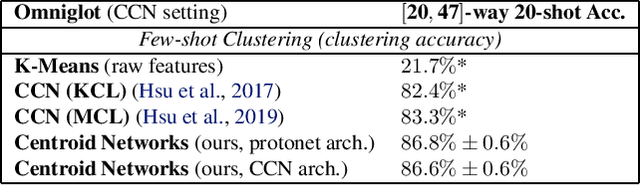
Traditional clustering algorithms such as K-means rely heavily on the nature of the chosen metric or data representation. To get meaningful clusters, these representations need to be tailored to the downstream task (e.g. cluster photos by object category, cluster faces by identity). Therefore, we frame clustering as a meta-learning task, few-shot clustering, which allows us to specify how to cluster the data at the meta-training level, despite the clustering algorithm itself being unsupervised. We propose Centroid Networks, a simple and efficient few-shot clustering method based on learning representations which are tailored both to the task to solve and to its internal clustering module. We also introduce unsupervised few-shot classification, which is conceptually similar to few-shot clustering, but is strictly harder than supervised* few-shot classification and therefore allows direct comparison with existing supervised few-shot classification methods. On Omniglot and miniImageNet, our method achieves accuracy competitive with popular supervised few-shot classification algorithms, despite using *no labels* from the support set. We also show performance competitive with state-of-the-art learning-to-cluster methods.
Scattering Networks for Hybrid Representation Learning
Sep 17, 2018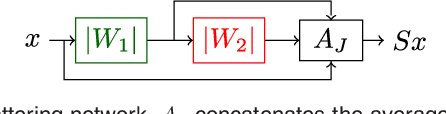

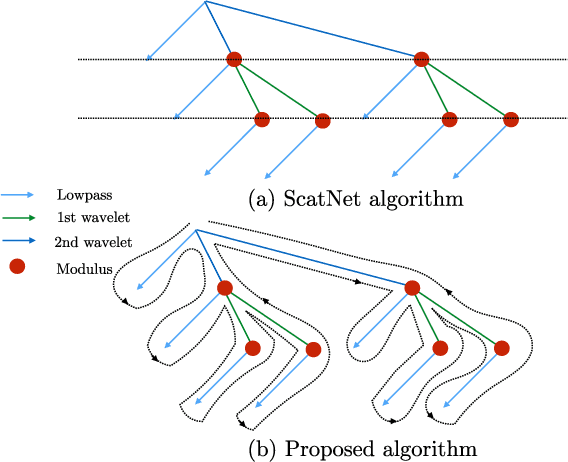

Scattering networks are a class of designed Convolutional Neural Networks (CNNs) with fixed weights. We argue they can serve as generic representations for modelling images. In particular, by working in scattering space, we achieve competitive results both for supervised and unsupervised learning tasks, while making progress towards constructing more interpretable CNNs. For supervised learning, we demonstrate that the early layers of CNNs do not necessarily need to be learned, and can be replaced with a scattering network instead. Indeed, using hybrid architectures, we achieve the best results with predefined representations to-date, while being competitive with end-to-end learned CNNs. Specifically, even applying a shallow cascade of small-windowed scattering coefficients followed by 1$\times$1-convolutions results in AlexNet accuracy on the ILSVRC2012 classification task. Moreover, by combining scattering networks with deep residual networks, we achieve a single-crop top-5 error of 11.4% on ILSVRC2012. Also, we show they can yield excellent performance in the small sample regime on CIFAR-10 and STL-10 datasets, exceeding their end-to-end counterparts, through their ability to incorporate geometrical priors. For unsupervised learning, scattering coefficients can be a competitive representation that permits image recovery. We use this fact to train hybrid GANs to generate images. Finally, we empirically analyze several properties related to stability and reconstruction of images from scattering coefficients.
* arXiv admin note: substantial text overlap with arXiv:1703.08961
Negative Momentum for Improved Game Dynamics
Jul 12, 2018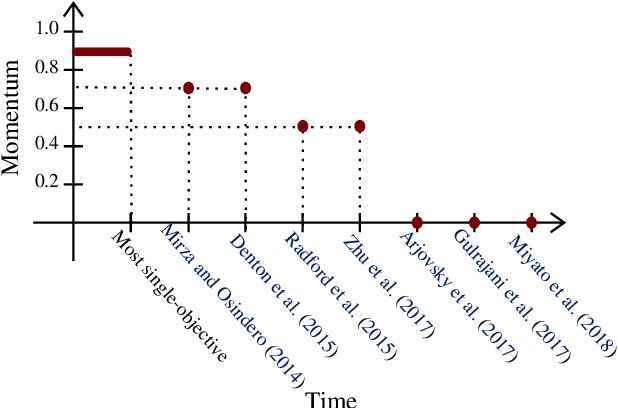

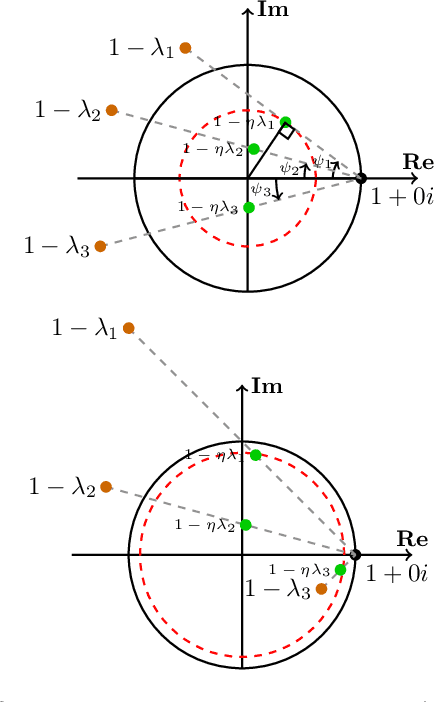
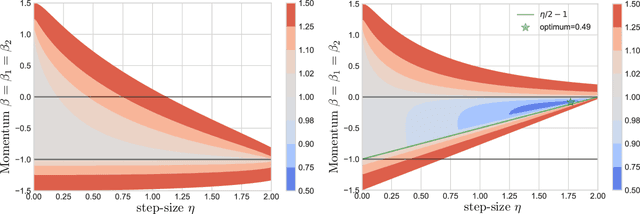
Games generalize the optimization paradigm by introducing different objective functions for different optimizing agents, known as players. Generative Adversarial Networks (GANs) are arguably the most popular game formulation in recent machine learning literature. GANs achieve great results on generating realistic natural images, however they are known for being difficult to train. Training them involves finding a Nash equilibrium, typically performed using gradient descent on the two players' objectives. Game dynamics can induce rotations that slow down convergence to a Nash equilibrium, or prevent it altogether. We provide a theoretical analysis of the game dynamics. Our analysis, supported by experiments, shows that gradient descent with a negative momentum term can improve the convergence properties of some GANs.
Parametric Adversarial Divergences are Good Task Losses for Generative Modeling
Jun 27, 2018
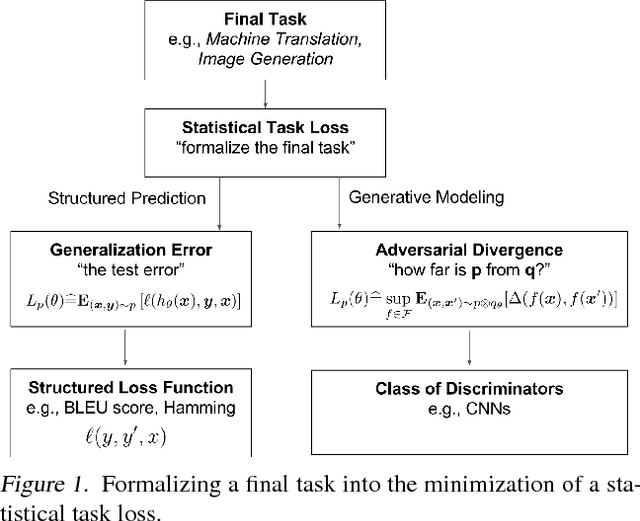

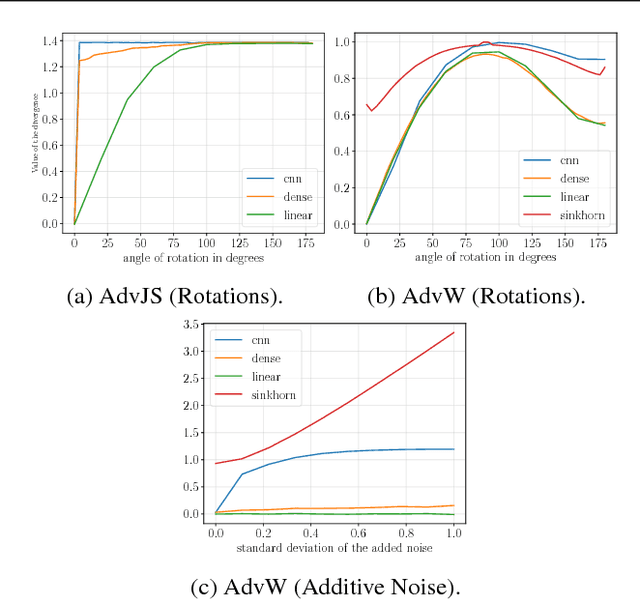
Generative modeling of high dimensional data like images is a notoriously difficult and ill-defined problem. In particular, how to evaluate a learned generative model is unclear. In this position paper, we argue that adversarial learning, pioneered with generative adversarial networks (GANs), provides an interesting framework to implicitly define more meaningful task losses for generative modeling tasks, such as for generating "visually realistic" images. We refer to those task losses as parametric adversarial divergences and we give two main reasons why we think parametric divergences are good learning objectives for generative modeling. Additionally, we unify the processes of choosing a good structured loss (in structured prediction) and choosing a discriminator architecture (in generative modeling) using statistical decision theory; we are then able to formalize and quantify the intuition that "weaker" losses are easier to learn from, in a specific setting. Finally, we propose two new challenging tasks to evaluate parametric and nonparametric divergences: a qualitative task of generating very high-resolution digits, and a quantitative task of learning data that satisfies high-level algebraic constraints. We use two common divergences to train a generator and show that the parametric divergence outperforms the nonparametric divergence on both the qualitative and the quantitative task.